End-to-End Text-Dependent Speaker Verification
In this paper we present a data-driven, integrated approach to speaker verification, which maps a test utterance and a few reference utterances directly to a single score for verification and jointly optimizes the system’s components using the same evaluation protocol and metric as at test time. Such an approach will result in simple and efficient systems, requiring little domain-specific knowledge and making few model assumptions. We implement the idea by formulating the problem as a single neural network architecture, including the estimation of a speaker model on only a few utterances, and evaluate it on our internal “Ok Google” benchmark for text-dependent speaker verification. The proposed approach appears to be very effective for big data applications like ours that require highly accurate, easy-to-maintain systems with a small footprint.
💡 Research Summary
The paper proposes a fully end‑to‑end neural network architecture for text‑dependent speaker verification, aiming to replace the traditional multi‑stage pipeline (feature extraction, i‑vector or d‑vector generation, PLDA scoring, score normalization) with a single model that directly maps a test utterance and a few enrollment utterances to a verification score. The authors argue that such an integrated approach reduces system complexity, eliminates the need for hand‑crafted heuristics, and can be trained using exactly the same protocol and metric that will be used at test time.
System Design
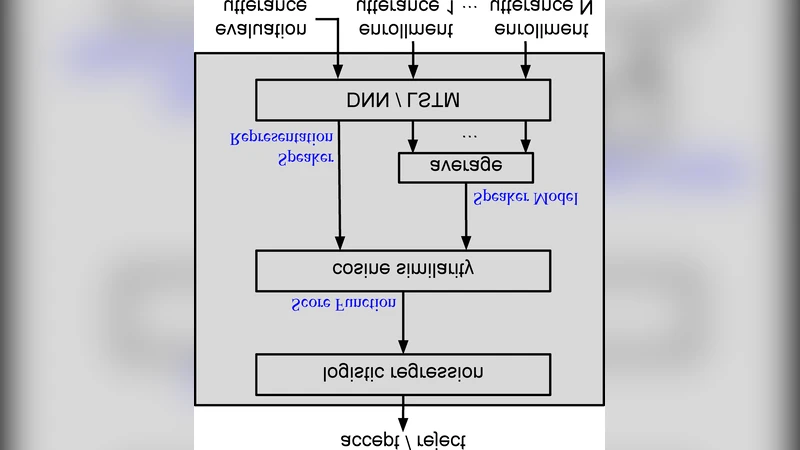
The architecture consists of three logical blocks that are implemented as a single computational graph:
-
Speaker Representation Network – Two variants are explored. The first is a deep neural network (DNN) with a locally‑connected layer followed by several fully‑connected layers; the second is a single‑layer long short‑term memory (LSTM) recurrent network. The DNN receives a fixed‑length input formed by concatenating 80 frames (≈0.8 s) of 40‑dimensional log‑filterbank features, while the LSTM processes the same frames sequentially. Both networks output a single embedding vector for each utterance.
-
Enrollment Model Estimation – For a given speaker, the embeddings of up to N enrollment utterances are averaged (a mask is used to allow a variable number of utterances). This average constitutes the speaker model. The same network is used to compute embeddings for the test utterance and for each enrollment utterance, ensuring that the model parameters are shared across all stages.
-
Verification Scoring – The cosine similarity S between the test embedding and the speaker model is fed into a logistic regression layer. The loss function is a binary cross‑entropy:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment