Data-selective Transfer Learning for Multi-Domain Speech Recognition
Negative transfer in training of acoustic models for automatic speech recognition has been reported in several contexts such as domain change or speaker characteristics. This paper proposes a novel technique to overcome negative transfer by efficient selection of speech data for acoustic model training. Here data is chosen on relevance for a specific target. A submodular function based on likelihood ratios is used to determine how acoustically similar each training utterance is to a target test set. The approach is evaluated on a wide-domain data set, covering speech from radio and TV broadcasts, telephone conversations, meetings, lectures and read speech. Experiments demonstrate that the proposed technique both finds relevant data and limits negative transfer. Results on a 6–hour test set show a relative improvement of 4% with data selection over using all data in PLP based models, and 2% with DNN features.
💡 Research Summary
This paper addresses the problem of negative transfer in acoustic model training for automatic speech recognition (ASR) when data from multiple, heterogeneous domains are combined. While maximum‑likelihood estimation (MLE) of Gaussian mixture model (GMM)–hidden Markov model (HMM) parameters is a long‑standing approach, it assumes model correctness and an effectively infinite amount of training data. In practice, adding more data from mismatched domains can degrade performance, a phenomenon known as negative transfer.
The authors propose a data‑selective transfer‑learning method that automatically chooses training utterances most acoustically similar to a given target test set. The core idea is to compute a likelihood‑ratio (LR) for each training utterance O:
LR(O) = (1/T) ∑_{t=1}^{T} p(O_t | Θ_tgt) / p(O_t | Θ_Ω)
where Θ_tgt is a 512‑mixture GMM trained only on the target domain data, and Θ_Ω is a 512‑mixture GMM trained on the full 60‑hour multi‑domain pool. The geometric mean of frame‑level ratios yields a single scalar LR(O) that quantifies acoustic similarity.
A submodular set function f_LR(S) = Σ_{O∈S} LR(O) is defined over any subset S of the training pool. Because f_LR is modular (a special case of submodular) and non‑decreasing, a greedy selection algorithm that iteratively adds the utterance with the highest marginal gain provides a (1 − 1/e) approximation to the optimal subset. The algorithm stops either when a predefined “budget” (total hours of speech) is reached or when adding another utterance does not increase f_LR.
Experiments use six well‑known speech domains: BBC Radio, BBC TV, Fisher telephone conversations, AMI/ICSI meetings, TED talks, and WSJCAM0 read speech. From each domain 10 hours are taken for training (total 60 h) and 1 hour for testing (total 6 h). Two acoustic feature sets are evaluated: (1) 39‑dimensional PLP (including first and second derivatives) and (2) a 65‑dimensional vector that concatenates the PLP features with 26‑dimensional bottleneck (BN) features extracted from a four‑layer deep neural network (DNN) trained on the full data. GMM‑HMM acoustic models are built with 5‑state triphones and 16 Gaussians per state; a 50 k‑word language model is interpolated across domains.
Baseline results show large domain‑dependent WER variations (e.g., 17 % for read speech, 51 % for TV) and a 25 % relative improvement when using PLP+BN versus PLP alone. Cross‑domain training without selection leads to substantial degradation, confirming negative transfer.
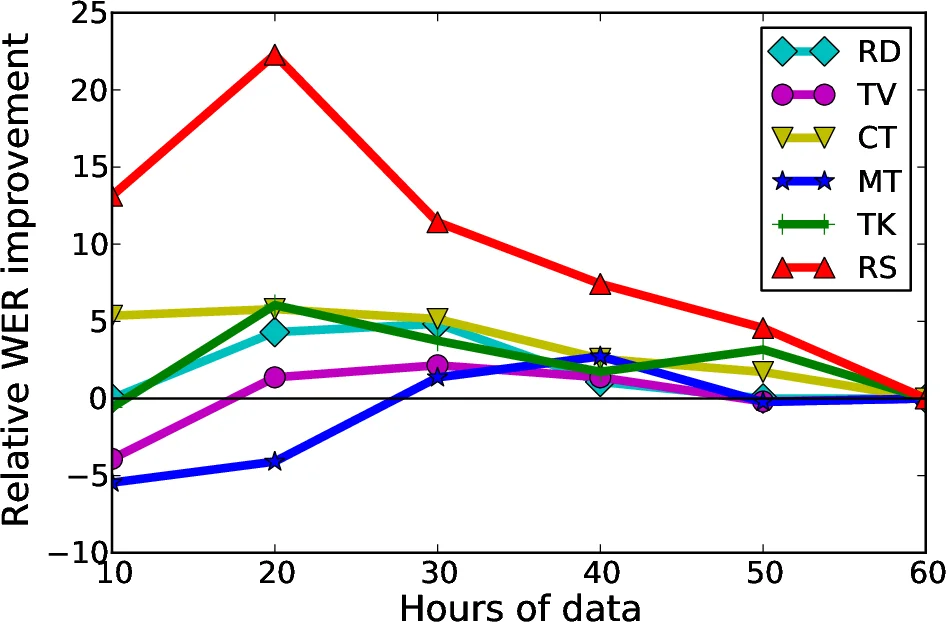
Data‑selection experiments are conducted in two ways. First, a budget‑based approach evaluates five budgets (10, 20, 30, 40, 50 h). As the budget grows, WER improves until a plateau, after which additional data re‑introduces negative transfer and performance converges to the full‑data baseline. Analysis of the selected subsets shows that while most utterances come from the same domain as the test set, a non‑trivial portion originates from other domains, evidencing positive transfer (e.g., TV and read speech utterances selected for Radio).
Second, an automatic budget decision is introduced to avoid manually fixing a budget. The distribution of LR values across all training utterances is modeled with a 512‑mixture GMM; the component with the highest mixture weight is taken as a robust estimate of the central tendency, and its mean serves as a threshold. All utterances with LR above this threshold are retained. This adaptive method automatically yields different amounts of data per target domain (e.g., ~41 h for Radio, ~17 h for Read speech).
Results with automatic thresholding outperform the best fixed‑budget (30 h) configuration for both feature sets. For PLP features the average WER drops from 34.9 % (full data) to 34.7 % (auto‑budget), a 4 % relative gain. For PLP+BN features the average WER improves from 26.3 % to 26.2 %, a 2 % relative gain.
The authors note that the LR‑based submodular function focuses solely on acoustic similarity and does not explicitly enforce phonetic coverage. In the current balanced dataset this did not cause phone‑distribution bias, but they suggest augmenting the selection criterion with a phonetic‑coverage term for more skewed corpora. They also discuss extending the approach to discriminative training criteria such as Minimum Phone Error (MPE), which would require different submodular formulations. Future work includes scaling to larger, more mismatched datasets and exploring alternative feature representations.
In summary, the paper demonstrates that (1) negative transfer is a real issue in multi‑domain ASR, (2) a simple likelihood‑ratio based submodular function can efficiently identify acoustically relevant training data, and (3) both budget‑based and automatically derived thresholds lead to consistent WER reductions, confirming the practical value of data‑selective transfer learning for diverse speech recognition scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment