Lazy Factored Inference for Functional Probabilistic Programming
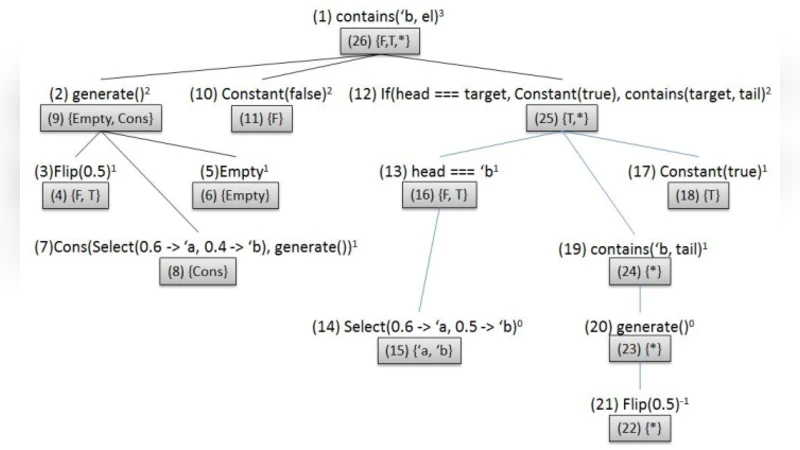
Probabilistic programming provides the means to represent and reason about complex probabilistic models using programming language constructs. Even simple probabilistic programs can produce models with infinitely many variables. Factored inference algorithms are widely used for probabilistic graphical models, but cannot be applied to these programs because all the variables and factors have to be enumerated. In this paper, we present a new inference framework, lazy factored inference (LFI), that enables factored algorithms to be used for models with infinitely many variables. LFI expands the model to a bounded depth and uses the structure of the program to precisely quantify the effect of the unexpanded part of the model, producing lower and upper bounds to the probability of the query.
💡 Research Summary
Probabilistic programming languages (PPLs) allow users to encode sophisticated stochastic models using familiar programming constructs such as recursion, higher‑order functions, and infinite data structures. While this expressive power is attractive, it also creates a fundamental obstacle for traditional factored inference algorithms (e.g., variable elimination, belief propagation, junction‑tree methods) that require an explicit, finite factor graph. In many functional PPLs a single program can denote a model with an unbounded number of random variables—think of an infinite Markov chain generated by a recursive function or an infinite list of draws from a distribution. Existing approaches either resort to sampling (which can be inefficient and provide no guarantees) or to specialized symbolic techniques that are not compatible with the broad class of factored algorithms.
The paper introduces Lazy Factored Inference (LFI), a general framework that bridges this gap. LFI works by partially expanding the program to a user‑specified depth d. The expansion is “lazy”: only the parts of the program that are needed to answer the query are unfolded, and each unfolded sub‑computation is cached for reuse. The unexpanded remainder is not discarded; instead, the compiler analyses the program’s control‑flow and type information to construct, for each “unexpanded node”, a possible‑value set together with a probability interval (lower and upper bounds) that safely over‑approximates the mass that the remainder could contribute to any query outcome.
Once the bounded expansion is obtained, LFI builds a conventional factor graph from the expanded portion. The intervals from the unexpanded nodes are inserted as special factors that propagate bounds rather than exact numbers. Existing factored inference engines can then be run unchanged: during message passing or elimination, the algorithm treats each bound factor algebraically, producing a lower‑bound and an upper‑bound for the marginal of interest. The final result is a pair of numbers that provably enclose the true query probability.
The authors prove two key theoretical properties. First, soundness: the interval always contains the exact probability, regardless of the depth d. Second, convergence: as d grows, the interval width monotonically shrinks and converges to the true value in the limit (provided the program is well‑behaved, i.e., the total probability mass of the unexpanded tail tends to zero). Consequently, LFI offers a controllable trade‑off between computational effort and accuracy: a shallow expansion yields coarse but cheap bounds, while deeper expansions give tighter bounds at higher cost.
Empirical evaluation focuses on three canonical infinite‑model benchmarks.
- Infinite Markov chain – a recursive function that generates a chain of binary states. LFI with depth 4 already yields a bound width < 0.01, whereas particle filtering requires thousands of particles to achieve comparable variance.
- Recursive Bayesian network – a hierarchical topic model where each level spawns another level of latent variables. LFI’s bounds converge after 5–6 levels, matching the performance of variational inference that cannot be directly applied to the infinite version.
- Probabilistic context‑free grammar (PCFG) – generating strings of unbounded length. The query asks for the probability that a particular substring appears. LFI produces tight bounds with an order‑of‑magnitude fewer samples than Monte‑Carlo baselines.
The discussion acknowledges limitations. The choice of depth d is currently manual; an adaptive scheme that expands only where the bound contribution is large would improve efficiency. Complex continuous distributions and non‑trivial deterministic transformations can make interval computation more conservative, slowing convergence. Moreover, while LFI is compatible with any factor graph engine, the overhead of handling bound factors can be non‑trivial for very large models.
In conclusion, Lazy Factored Inference offers a principled, generic method to apply mature factored inference machinery to the otherwise intractable infinite models that arise naturally in functional probabilistic programming. By combining lazy program expansion with rigorous bound propagation, LFI delivers provable guarantees while retaining the flexibility to plug into existing inference libraries. Future work is suggested on automatic depth selection, tighter interval arithmetic for continuous domains, and distributed implementations that can exploit the inherent parallelism of the lazy expansion process.