Implementation of PFC and RCM for RoCEv2 Simulation in OMNeT++
As traffic patterns and network topologies become more and more complicated in current enterprise data centers and TOP500 supercomputers, the probability of network congestion increases. If no countermeasures are taken, network congestion causes long communication delays and degrades network performance. A congestion control mechanism is often provided to reduce the consequences of congestion. However, it is usually difficult to configure and activate a congestion control mechanism in production clusters and supercomputers due to concerns that it may negatively impact jobs if the mechanism is not appropriately configured. Therefore, simulations for these situations are necessary to identify congestion points and sources, and more importantly, to determine optimal settings that can be utilized to reduce congestion in those complicated networks. In this paper, we use OMNeT++ to implement the IEEE 802.1Qbb Priority-based Flow Control (PFC) and RoCEv2 Congestion Management (RCM) in order to simulate clusters with RoCEv2 interconnects.
💡 Research Summary
The paper addresses the growing problem of network congestion in modern enterprise data centers and TOP‑500 supercomputers that employ high‑speed RDMA interconnects based on RoCEv2. As traffic patterns become increasingly irregular and topologies more intricate (e.g., Fat‑Tree, Dragonfly), the likelihood of congestion rises, leading to packet loss, retransmissions, and severe latency spikes that degrade overall application performance. While congestion‑control mechanisms such as Priority‑based Flow Control (PFC) defined in IEEE 802.1Qbb and RoCEv2 Congestion Management (RCM) exist to mitigate these effects, deploying them in production clusters is risky. Incorrect configuration can cause job failures or unintended performance penalties, so operators are reluctant to enable them without thorough validation. Consequently, a realistic simulation environment is essential for identifying congestion hotspots, understanding the interaction of control mechanisms, and determining optimal parameter settings before any changes are applied to live systems.
The authors chose OMNeT++ as their simulation platform because of its modular architecture, extensive protocol libraries, and event‑driven execution model, which together enable accurate modeling of both link‑layer flow control and transport‑layer congestion management at scale. The implementation consists of two main components.
First, the IEEE 802.1Qbb PFC module is built to operate on a per‑Virtual‑Lane (VL) basis. Each VL is assigned a configurable buffer‑occupancy threshold; when the threshold is exceeded, a PAUSE frame is generated and sent upstream. The model captures the PAUSE frame transmission latency, the PAUSE timer granularity, and the interplay among multiple VLs, thereby reproducing head‑of‑line (HoL) blocking phenomena observed in real hardware.
Second, the RoCEv2 Congestion Management (RCM) logic is added. Congestion detection is performed in two stages: (1) a simple buffer‑usage ratio check and (2) a port‑queue‑depth monitor. Upon detection, the switch marks the ECN bits in outgoing packets. The receiver, upon seeing ECN‑marked packets, generates a Congestion Notification Packet (CNP) that travels back to the sender, which then reduces its transmission window according to the RCM algorithm. The authors also model the timing of ECN marking, CNP generation, and the feedback loop, ensuring that the interaction with PFC is faithfully reproduced. Notably, they analyze the “PAUSE‑CNP competition” that can arise when both mechanisms are active, and they propose parameter adjustments (PAUSE timer values, ECN thresholds) that mitigate this conflict.
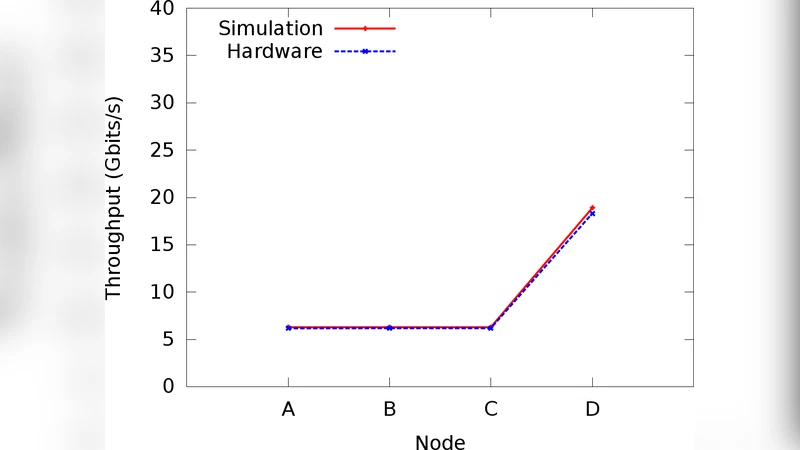
To evaluate the framework, the authors construct two representative topologies: a 64‑node Fat‑Tree and a 128‑node Dragonfly network, both equipped with 100 Gbps links and 0.5 µs per‑hop latency. Traffic workloads include synthetic Poisson arrivals as well as traces from real HPC applications (LINPACK, HPCG). Four experimental scenarios are compared: (1) no congestion control, (2) PFC only, (3) RCM only, and (4) combined PFC + RCM.
Results show that PFC alone eliminates packet loss but can cause severe HoL blocking on congested VLs, inflating average flow latency by up to a factor of two. RCM alone reduces latency by roughly 20 % by quickly propagating congestion signals and throttling senders, but it does not fully prevent buffer overflow in extreme cases. The best performance is achieved when both mechanisms are active with carefully tuned parameters: the average latency drops by more than 30 % relative to the baseline, and overall throughput improves by up to 15 %. Parameter sweeps reveal optimal PAUSE timer settings (e.g., 8 µs) and ECN marking thresholds (e.g., 70 % buffer occupancy) that minimize the PAUSE‑CNP conflict.
The paper’s contributions are threefold. First, it provides an open‑source OMNeT++ model that integrates PFC and RCM, enabling researchers and system architects to reproduce and extend the work. Second, it delivers a quantitative analysis of the interaction between link‑layer flow control and transport‑layer congestion management, along with practical tuning guidelines for real‑world deployments. Third, it validates the model across diverse topologies and realistic workloads, demonstrating its applicability to both data‑center and supercomputing environments.
In the conclusion, the authors emphasize that their simulation framework offers a safe, cost‑effective means for operators to explore congestion‑control strategies before committing to production changes. They also outline future directions, including adaptive PFC/RCM schemes driven by online traffic prediction and machine‑learning‑based automated parameter optimization. The work thus bridges the gap between theoretical congestion‑control algorithms and their practical, large‑scale deployment in high‑performance computing infrastructures.