Incremental Active Opinion Learning Over a Stream of Opinionated Documents
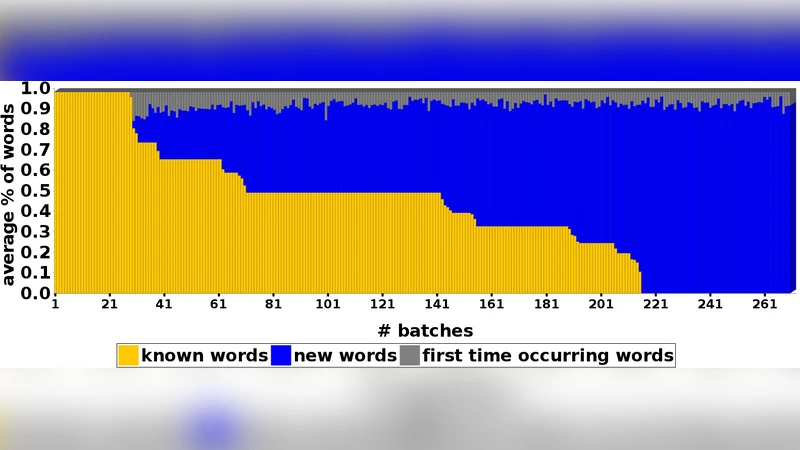
Applications that learn from opinionated documents, like tweets or product reviews, face two challenges. First, the opinionated documents constitute an evolving stream, where both the author’s attitude and the vocabulary itself may change. Second, labels of documents are scarce and labels of words are unreliable, because the sentiment of a word depends on the (unknown) context in the author’s mind. Most of the research on mining over opinionated streams focuses on the first aspect of the problem, whereas for the second a continuous supply of labels from the stream is assumed. Such an assumption though is utopian as the stream is infinite and the labeling cost is prohibitive. To this end, we investigate the potential of active stream learning algorithms that ask for labels on demand. Our proposed ACOSTREAM 1 approach works with limited labels: it uses an initial seed of labeled documents, occasionally requests additional labels for documents from the human expert and incrementally adapts to the underlying stream while exploiting the available labeled documents. In its core, ACOSTREAM consists of a MNB classifier coupled with “sampling” strategies for requesting class labels for new unlabeled documents. In the experiments, we evaluate the classifier performance over time by varying: (a) the class distribution of the opinionated stream, while assuming that the set of the words in the vocabulary is fixed but their polarities may change with the class distribution; and (b) the number of unknown words arriving at each moment, while the class polarity may also change. Our results show that active learning on a stream of opinionated documents, delivers good performance while requiring a small selection of labels
💡 Research Summary
The paper addresses the problem of learning from a continuous stream of opinionated documents (e.g., tweets, product reviews) under two realistic constraints: (1) the vocabulary evolves over time, with new words appearing and the polarity of existing words potentially shifting, and (2) labeled data are scarce because obtaining document-level sentiment labels is costly in an infinite‑stream setting. While most prior work on opinion‑stream mining focuses on concept drift (changes in class distribution) and assumes a fixed vocabulary and abundant labels, this study proposes an active, incremental learning framework called ACOSTREAM that works with a limited set of labeled documents and requests additional labels only when needed.
ACOSTREAM’s core is a Multinomial Naïve Bayes (MNB) classifier. An initial seed set S of labeled documents is used to compute word‑class counts N_ic and class counts N_c, from which empirical priors ˆP(c) and conditional probabilities ˆP(w_i|c) are derived (with Laplace smoothing). For each incoming document d, the classifier predicts its polarity by maximizing the posterior ˆP(c|d)∝ˆP(c)∏ˆP(w_i|c). Because the stream may drift, the model is updated incrementally rather than retrained from scratch.
The novelty lies in the active sampling component. Two strategies are explored: (a) Information‑Gain (IG) sampling, which measures the reduction in entropy of word‑class distributions if the predicted label of d were added to the training set; documents that produce a large IG are queried for their true label. (b) Uncertainty sampling, which selects documents whose predicted class probability is near 0.5, i.e., the classifier is most unsure. Once a true label is obtained from an expert, the word‑class counts for all words in d (including newly observed words) are updated, the vocabulary V is expanded as needed, and the seed set S is enlarged. This incremental update avoids costly full retraining and allows the model to adapt both to concept drift and to vocabulary change.
Experiments were conducted under two controlled scenarios. In the first, the class distribution changes while the vocabulary remains fixed, but word polarities shift in accordance with the new distribution. In the second, each time step introduces a number of previously unseen words and the class distribution may also change. Across both settings, ACOSTREAM achieved classification performance comparable to fully supervised baselines that have access to all labels, while requesting labels for only about 5–10 % of the incoming documents. This demonstrates that a small, strategically selected set of labeled instances suffices to keep the model accurate.
The paper positions ACOSTREAM against related work in active learning, stream mining, and context‑sensitive sentiment analysis. Most existing stream‑based sentiment classifiers assume a static vocabulary and either continuous labeling or semi‑supervised propagation without active querying. ACOSTREAM’s combination of MNB’s easy incremental statistics, active sampling, and dynamic vocabulary handling fills this gap. The authors also discuss practical considerations such as Laplace smoothing to handle zero‑frequency words and the computational efficiency of updating counts versus full model reconstruction.
In conclusion, ACOSTREAM offers a practical solution for real‑time opinion mining where labeling resources are limited and language evolves. It maintains high accuracy with minimal labeling effort and low computational overhead, making it suitable for large‑scale, continuously arriving opinion streams. Future work suggested includes extending the approach to multi‑class sentiment (e.g., neutral), integrating deep‑learning representations, and performing a more detailed cost‑benefit analysis of labeling strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment