A Neural Attention Model for Abstractive Sentence Summarization
Summarization based on text extraction is inherently limited, but generation-style abstractive methods have proven challenging to build. In this work, we propose a fully data-driven approach to abstractive sentence summarization. Our method utilizes a local attention-based model that generates each word of the summary conditioned on the input sentence. While the model is structurally simple, it can easily be trained end-to-end and scales to a large amount of training data. The model shows significant performance gains on the DUC-2004 shared task compared with several strong baselines.
💡 Research Summary
The paper tackles the problem of abstractive sentence summarization by introducing a fully data‑driven neural architecture that combines a feed‑forward neural language model with an attention‑based encoder. The authors argue that extraction‑based summarization is inherently limited because it can only copy fragments of the source text, whereas human summarizers frequently paraphrase, generalize, and reorder information. To address these challenges, the model is designed to generate each summary token conditioned on the entire input sentence and the previously generated summary context.
The core of the system is a conditional language model p(y_{i+1} | x, y_c; θ) where x denotes the input sentence and y_c the recent summary context (a fixed‑size window of previous words). The decoder follows the classic feed‑forward neural language model (NNLM) of Bengio et al., using word embeddings, a hidden tanh layer, and an output projection. What distinguishes this work is the encoder term enc(x, y_c) that injects source‑side information into the decoder at every time step.
Three encoder variants are explored:
- Bag‑of‑Words Encoder – a simple average of input word embeddings, providing a global representation that captures word importance but ignores order.
- Convolutional Encoder – a deep time‑delay neural network (TDNN) with alternating convolution and max‑pooling layers, allowing the model to capture local n‑gram patterns while remaining computationally cheap.
- Attention‑Based Encoder – inspired by Bahdanau et al. (2014), this component computes a soft alignment between the current summary context and each input token. The alignment scores are obtained via a dot‑product between context embeddings and input embeddings transformed by a learned matrix P, optionally smoothed by a window Q. The resulting weighted sum of input embeddings forms a dynamic representation that changes as the summary is generated.
Training proceeds by minimizing the negative log‑likelihood of the reference summaries over a large parallel corpus of (input, summary) pairs. The authors use mini‑batch stochastic gradient descent and train on the Gigaword headline‑generation dataset, which contains roughly four million article‑headline pairs. Because the model makes no hard alignment constraints, it can be trained end‑to‑end without any external alignment or syntactic preprocessing.
For inference, exact Viterbi decoding is theoretically possible but impractical due to the large vocabulary size. Consequently, the authors adopt a beam‑search algorithm that keeps the top K hypotheses at each generation step. The beam search operates in O(K·N·|V|) time, but the probability of each candidate word is computed in a single mini‑batch, making the procedure efficient on modern GPUs.
To compensate for the model’s limited ability to copy rare or out‑of‑vocabulary tokens directly from the source, the authors augment the scoring function with a log‑linear term containing five handcrafted features: (i) the neural model’s log‑probability, (ii) a binary indicator of whether the candidate word appears anywhere in the source, (iii) bigram match, (iv) trigram match, and (v) a reordering indicator. The feature weights α are tuned using Minimum Error Rate Training (MERT) on a development set, directly optimizing the ROUGE metric.
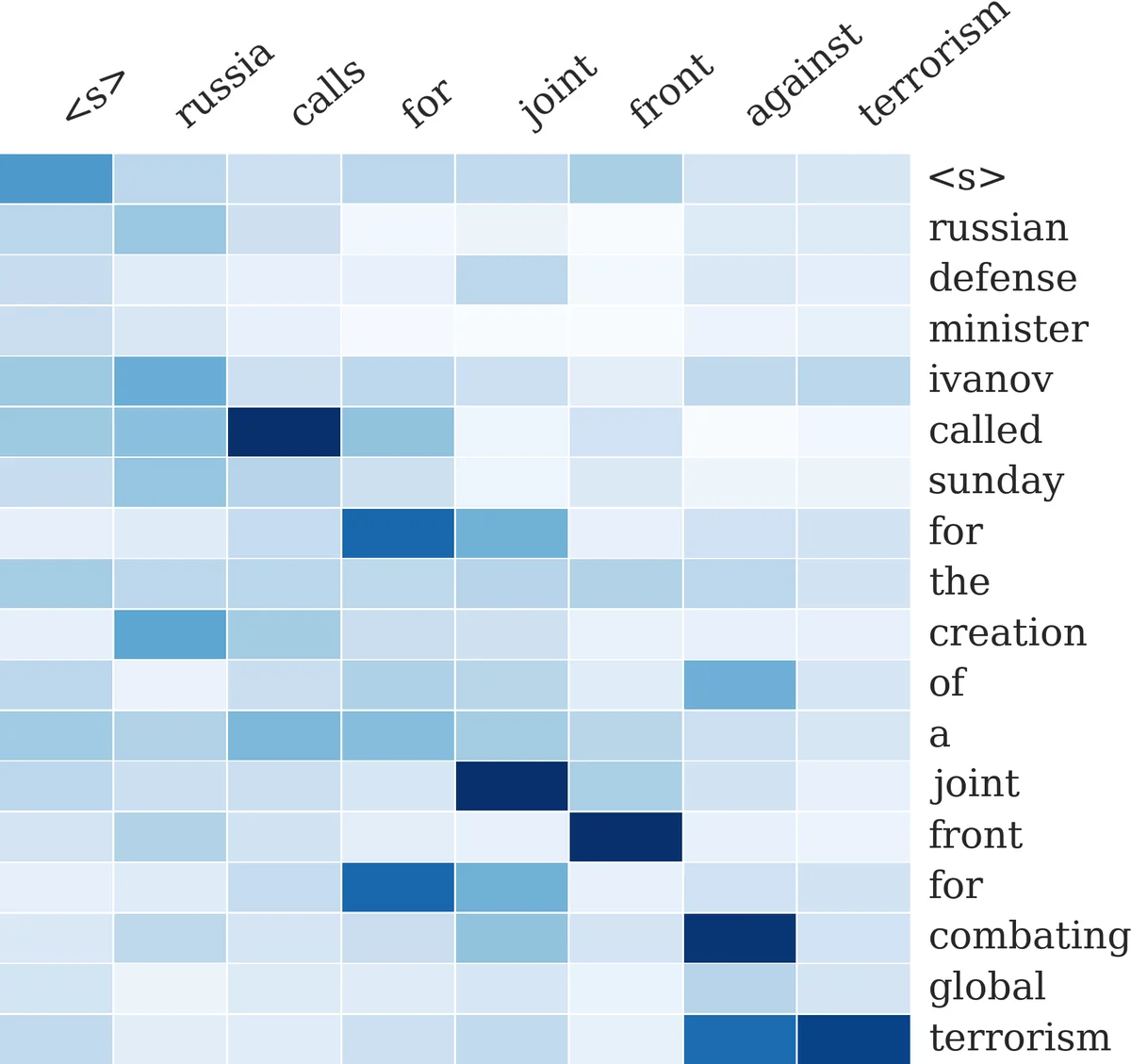
Experiments are conducted on two fronts. First, the model is trained on the Gigaword corpus and evaluated on headline generation, demonstrating that the attention‑based system (ABS) outperforms a strong phrase‑based statistical machine translation baseline and a standard neural MT model trained on the same data. Second, the system is tested on the DUC‑2004 summarization task, where summaries are limited to 75 bytes. ABS achieves the highest ROUGE‑1, ROUGE‑2, and ROUGE‑L scores among all compared systems, including syntax‑based compression, integer linear programming extractors, information‑retrieval methods, and a phrase‑based MT system. Qualitative analysis of the attention heatmaps shows that the model learns sensible alignments, focusing on salient source words when generating each summary token.
The paper situates its contribution within prior work on abstractive summarization, noting that earlier approaches relied on linguistic constraints, syntactic transformations, or noisy‑channel models that separated language and translation components. By integrating the encoder and decoder into a single neural network trained end‑to‑end, the authors demonstrate that a relatively simple architecture can scale to massive datasets and achieve state‑of‑the‑art performance on benchmark summarization tasks.
In conclusion, the authors present a compact yet powerful neural summarization model that leverages attention to dynamically incorporate source information during generation. The model’s simplicity enables efficient training on large corpora, while the attention mechanism provides the flexibility needed for paraphrasing and content reordering. Future directions suggested include extending the approach to multi‑sentence or multi‑document summarization, incorporating reinforcement learning for global sequence optimization, and exploring richer encoder architectures such as bidirectional RNNs or Transformers.
Comments & Academic Discussion
Loading comments...
Leave a Comment