Hybrid Update/Invalidate Schemes for Cache Coherence Protocols
In general when considering cache coherence, write back schemes are the default. These schemes invalidate all other copies of a data block during a write. In this paper we propose several hybrid schemes that will switch between updating and invalidating on processor writes at runtime, depending on program conditions. We created our own cache simulator on which we could implement our schemes, and generated data sets from both commercial benchmarks and through artificial methods to run on the simulator. We analyze the results of running the benchmarks with various schemes, and suggest further research that can be done in this area.
💡 Research Summary
The paper investigates the trade‑offs between the two dominant cache‑coherence strategies used in modern multicore processors—write‑back invalidate‑only protocols and update‑only protocols—and proposes a set of hybrid schemes that dynamically choose between invalidation and update on a per‑write basis.
The authors begin with a concise review of the MOESI state‑based protocol, describing its five states (Modified, Owned, Exclusive, Shared, Invalid) and noting that most commercial systems implement a write‑back invalidate‑only variant (N‑MOESI). Invalidate‑only protocols send an invalidate message to all other caches whenever a core writes to a line that is not in the exclusive or modified state, thereby avoiding unnecessary data traffic but potentially incurring extra memory accesses later when the invalidated line is needed again. Update‑only protocols, by contrast, broadcast the new data to all sharers on every write, eliminating the later miss penalty but generating a large amount of bus traffic, especially when the line is not actually shared.
To bridge this gap, the authors design four hybrid mechanisms:
-
Threshold Scheme – Each cache line carries a counter initialized to zero. On every read of a valid line the counter is incremented; after a successful write the counter is decremented. When a core writes, the counter is compared to a configurable threshold. If the counter ≥ threshold, an update message is sent; otherwise an invalidate is sent. The scheme is intended to favour updates for lines that have been read many times and to favour invalidates for write‑heavy lines.
-
Adapted‑MOESI – This is a minimal modification of the invalidate‑only protocol: when a line is in the Owned (O) state, a write triggers an update instead of an invalidate; writes to Shared (S) or Invalid (I) still generate invalidates. The idea is that O state already indicates that another core holds a dirty copy, so broadcasting the new value is cheap.
-
Number‑of‑Sharers Scheme – The decision is based on the current number of sharers for a line (information readily available in directory‑based systems). If the number of sharers meets or exceeds a preset limit, the write is performed as an update; otherwise it is an invalidate.
-
Baseline Schemes – Pure Invalidate‑Only and pure Update‑Only are retained for comparison.
The authors built a custom functional cache simulator in C++ to evaluate these schemes. The simulator supports 2–16 cores, each with a single‑level cache of 64 sets and 4‑way associativity. Input traces consist of “load/store, core ID, address” tuples. During simulation the tool counts read requests, invalidate requests, and update requests; total bus traffic (the sum of these three) is used as the performance metric, under the assumption that it correlates with actual network load.
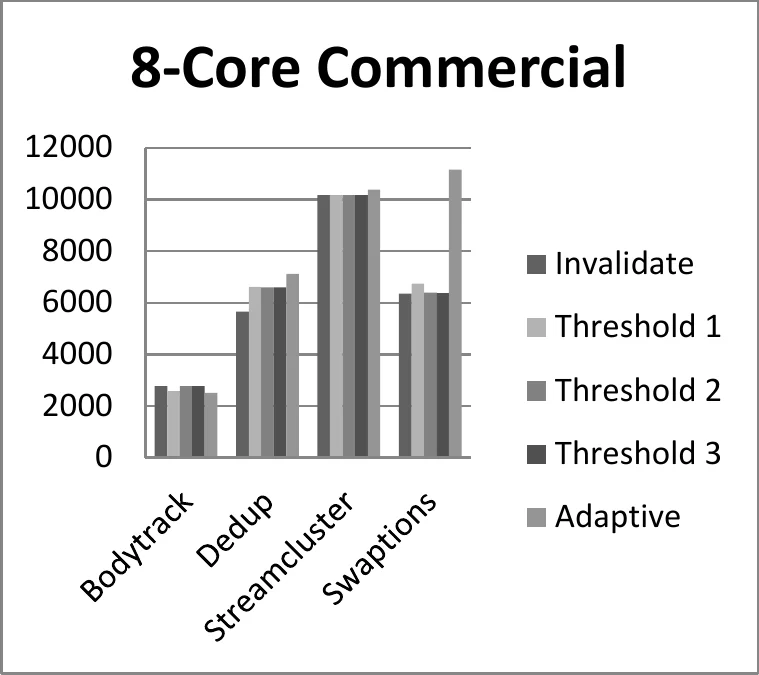
Two families of workloads are used. Commercial benchmarks (Bodytrack, Dedup, Streamcluster, Swaptions) are extracted from the multi2sim timing simulator: after a warm‑up phase, five million memory operations are recorded for each benchmark and each core count (2, 4, 8, 16). Artificial workloads are also generated: a Locks benchmark that models contention on a small set of shared locks, an Arrays benchmark that mimics stencil‑like neighbor updates, and a Pseudo‑Server benchmark that separates public and private address spaces.
Key Findings
-
For most benchmarks, especially those with low sharing (Dedup, Streamcluster, Swaptions), the pure Invalidate‑Only scheme yields the smallest number of bus transactions. Update‑Only inflates traffic dramatically because it pushes updates to cores that never read the line again.
-
The Bodytrack benchmark, a computer‑vision application with dense sharing, shows a different pattern: both Invalidate‑Only and Update‑Only perform relatively well, and the hybrid schemes (Threshold with threshold = 1 and Adapted‑MOESI) outperform both by roughly 10–15 % in total traffic. This confirms the intuition that a dynamic choice can exploit high sharing.
-
The Threshold scheme is sensitive to the threshold value. A threshold of 1 produces noticeable benefits for Bodytrack and a few other cases; thresholds of 3 or higher behave almost identically to pure invalidation, because the counter rarely reaches those values in the tested workloads.
-
The Adapted‑MOESI scheme, which only updates when the line is in the Owned state, performs similarly to the Threshold‑1 scheme, reinforcing the observation that many “update‑worthy” lines are indeed in the O state. However, not all O‑state lines meet the counter‑= 1 condition, so the two policies are not perfectly equivalent.
-
The Number‑of‑Sharers scheme does not yield a clear advantage for any of the tested workloads. Even with a low sharer‑count threshold (2–3), the total traffic remains close to the Invalidate‑Only baseline, suggesting that the simple sharer count is not a strong predictor of future reads in the examined programs.
-
Artificial workloads exhibit expected behavior: the Locks benchmark (few shared lines) slightly favors invalidation, the Arrays benchmark shows almost no difference across schemes because its strict ordering prevents useful updates, and the Pseudo‑Server benchmark actually benefits from Update‑Only due to its single writer / many readers pattern.
Interpretation and Implications
The study confirms that in the majority of realistic applications, a pure invalidate‑only protocol remains the most efficient choice because sharing is limited. Nevertheless, for workloads with high temporal and spatial sharing, a lightweight hybrid mechanism can reduce bus traffic without incurring the full cost of an always‑update protocol. Among the hybrids, the Adapted‑MOESI approach is attractive from a hardware‑design perspective: it requires only a modest change to the state‑machine (treat O‑state writes as updates) and avoids per‑line counters. The Threshold scheme, while conceptually elegant, demands extra metadata (counters) and careful tuning of the threshold. The Number‑of‑Sharers scheme, though easy to implement in directory systems, did not prove effective in the tested scenarios.
Limitations and Future Work
The evaluation is based on a functional (timing‑agnostic) simulator; latency effects, bandwidth constraints, and interaction with other microarchitectural components (e.g., prefetchers, out‑of‑order execution) are not captured. Future research could integrate the hybrid policies into a full‑system timing simulator to assess impact on execution time and energy. Adaptive thresholds that change at runtime based on observed miss rates or machine‑learning predictors could further improve decision quality. Moreover, extending the study to larger core counts (64‑core and beyond), to heterogeneous systems, and to emerging memory technologies (e.g., non‑volatile caches) would broaden the relevance of the findings.
In summary, the paper provides a systematic exploration of hybrid update/invalidate coherence strategies, demonstrates that modest protocol extensions can yield measurable traffic reductions for highly shared workloads, and outlines clear directions for refining and deploying such mechanisms in future multicore architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment