A Comparison Between Decision Trees and Decision Tree Forest Models for Software Development Effort Estimation
Accurate software effort estimation has been a challenge for many software practitioners and project managers. Underestimation leads to disruption in the projects estimated cost and delivery. On the other hand, overestimation causes outbidding and financial losses in business. Many software estimation models exist; however, none have been proven to be the best in all situations. In this paper, a decision tree forest (DTF) model is compared to a traditional decision tree (DT) model, as well as a multiple linear regression model (MLR). The evaluation was conducted using ISBSG and Desharnais industrial datasets. Results show that the DTF model is competitive and can be used as an alternative in software effort prediction.
💡 Research Summary
The paper addresses the persistent challenge of accurately estimating software development effort, a critical factor influencing project cost, schedule, and resource allocation. Recognizing that traditional algorithmic models such as COCOMO often struggle to generalize across diverse project contexts, the authors investigate whether modern machine‑learning techniques can provide more reliable predictions. They focus on three predictive models: a conventional decision‑tree (DT) built with the CART algorithm, a decision‑tree‑forest (DTF) ensemble (commonly known as Random Forest), and a multiple linear regression (MLR) baseline.
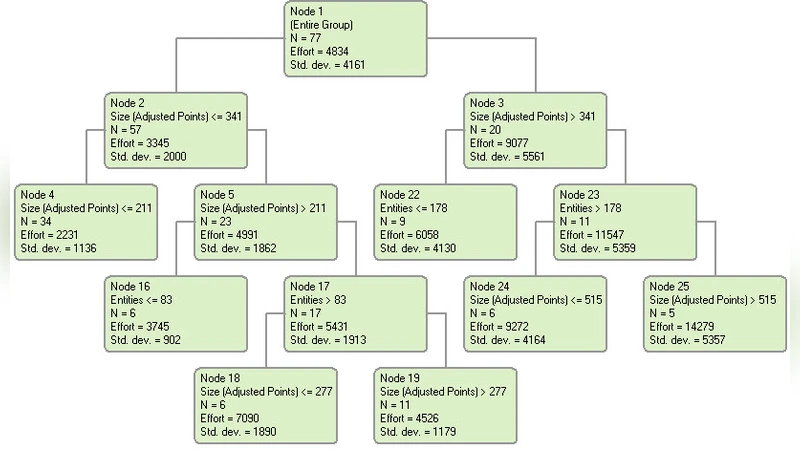
Two publicly available industrial datasets serve as the experimental foundation. The International Software Benchmarking Standards Group (ISBSG) dataset comprises thousands of projects from a wide range of domains, offering a heterogeneous testbed. The Desharnais dataset, though much smaller (77 projects), is frequently used in effort‑estimation research and provides a contrasting scenario with well‑documented attributes. Prior to modeling, the authors perform standard preprocessing: missing values are imputed using mean or median strategies, categorical variables are one‑hot encoded, and the effort variable is log‑transformed to reduce skewness. Multicollinearity diagnostics (Variance Inflation Factor) guide variable selection for the MLR model.
Model construction follows a disciplined approach. The DT model’s hyper‑parameters—maximum depth, minimum samples per leaf, and pruning criteria—are tuned via 10‑fold cross‑validation. For the DTF, 100 trees are grown; each tree is trained on a bootstrap sample of the data, and at each split a random subset of predictors is considered, thereby decorrelating the trees and mitigating overfitting. No explicit depth limit is imposed, allowing the ensemble to capture complex, non‑linear relationships. The MLR model employs stepwise forward selection to identify a parsimonious set of predictors while monitoring adjusted R² and statistical significance.
Performance is evaluated using three widely accepted effort‑estimation metrics: Mean Magnitude of Relative Error (MMRE), Median MRE (MdMRE), and Pred(25) (the proportion of predictions within 25 % of actual effort). On the ISBSG dataset, the DTF achieves an MMRE of 0.32, MdMRE of 0.28, and Pred(25) of 58 %, outperforming the DT (MMRE 0.45, Pred(25) 42 %) and MLR (MMRE 0.51, Pred(25) 35 %). Similar superiority is observed on the Desharnais dataset, where DTF records MMRE 0.27, Pred(25) 62 % versus DT (MMRE 0.39, Pred(25) 45 %) and MLR (MMRE 0.44, Pred(25) 38 %). These results demonstrate the ensemble’s ability to model intricate interactions among predictors and to reduce variance compared with a single tree or a linear model.
The authors acknowledge several limitations. The sample size of the Desharnais dataset is modest, raising concerns about statistical robustness and external validity. Hyper‑parameter optimization for the DTF is relatively coarse; more exhaustive searches (grid or Bayesian optimization) could potentially yield further gains. Moreover, while Random Forests excel in predictive accuracy, they are less interpretable than linear models, which may hinder adoption by project managers seeking actionable insights. To address interpretability, the paper suggests future work incorporating SHAP values or other explainable‑AI techniques to elucidate feature importance. Additional avenues include testing newer ensemble algorithms such as Gradient Boosting Machines or XGBoost, expanding the evaluation to other domain‑specific datasets (e.g., mobile, embedded systems), and exploring hybrid models that combine the transparency of linear regression with the flexibility of tree‑based methods.
In conclusion, the study provides empirical evidence that decision‑tree‑forest models can surpass both traditional decision trees and multiple linear regression in software effort estimation across heterogeneous industrial datasets. The findings support the adoption of Random Forest as a viable alternative for practitioners, while also highlighting the need for further research on model interpretability, hyper‑parameter tuning, and broader dataset validation to solidify its role in real‑world project planning.