OCReP: An Optimally Conditioned Regularization for Pseudoinversion Based Neural Training
In this paper we consider the training of single hidden layer neural networks by pseudoinversion, which, in spite of its popularity, is sometimes affected by numerical instability issues. Regularization is known to be effective in such cases, so that…
Authors: Rossella Cancelliere, Mario Gai, Patrick Gallinari
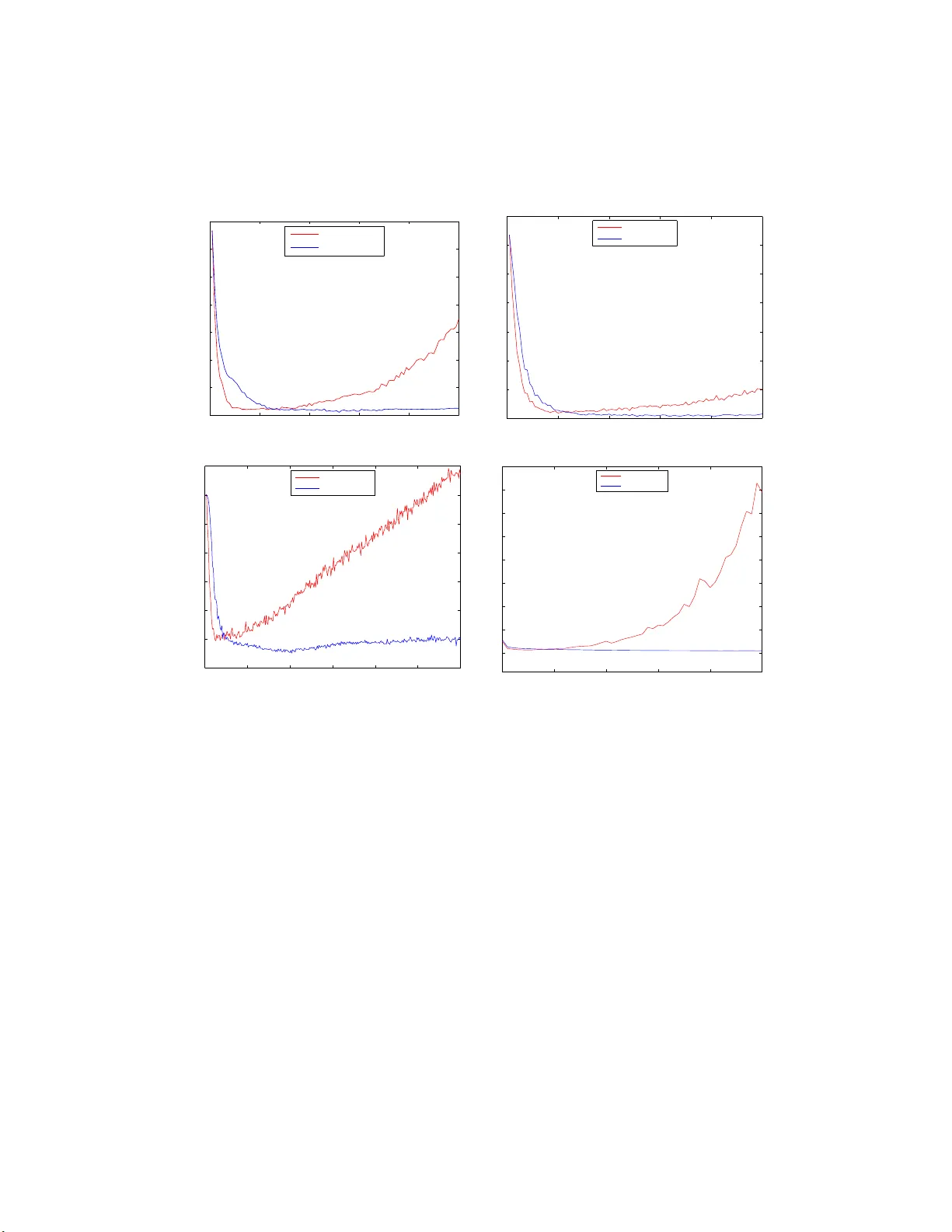
OCReP: An Optimally Conditioned Regula rization for Pseudoin v ersion Based Neural T raining Rossella Cancelliere a , Mario Gai b , P atric k Ga llinari c , Luca Rubini a a University of T u rin, Dep. of Computer Scienc es, C. so Svizzer a 185, 1014 9 T orino, Italy b National Institute of Astr ophysics, Astr ophys. Observ. of T orino , Pino T.se (TO), Italy c L ab or a tory of Computer S cienc es, LIP6, Univ. Pierr e et Marie Curie, Paris, F r anc e Abstract In this pap er w e consider the training of single hidden la y er neural net- w orks b y pseudoin v ersion, whic h, in spite of its p opularit y , is sometimes affected b y n umerical instabilit y issues. Regularization is kno wn t o b e ef- fectiv e in suc h cases, so that w e intro duce, in the framework of Tikhono v regularization, a matricial reformulation of the problem whic h allo ws us to use the condition n umber as a diag no stic to ol for iden tification of instabil- it y . By imp osing w ell-conditioning requiremen ts on t he relev an t matrices, our theoretical analysis allo ws the iden tification of an optimal v alue for the regularization parameter from the standp oin t of stabilit y . W e compare with the v alue deriv ed b y cross-v alidation for ov erfitting con trol and optimisation of the generalization p erformance. W e test our metho d for b ot h regression and classification tasks. The prop osed method is quite effectiv e in terms of predictivit y , often with some improv eme nt on p erformance with resp ect to the reference cases considere d. This approac h, due to analytical determina- tion of the regularization pa r a meter, dramatically reduces the computational load required by man y other t ec hniques. Keywor ds: Regularization parameter, Condition n um b er, Pseudoin v ersion, Numerical instabilit y 1. In t r o duction In past decades Single Lay er F eedforward Neural Net w orks (SLF N) train- ing w as mainly a ccomplished b y iterativ e algorithms in v olving the rep etition of learning steps aimed at minimising the error functional o v er the space o f Pr eprint submitte d to Neur al Net works August 14, 2021 net w ork parameters. These tec hniques often gav e rise to metho ds slow and computationally expensiv e. Researc hers therefore ha v e alw a ys b een motiv ated to explore alternative algorithms and recen tly some new tec hniques based on matrix in ve rsion ha ve b een dev elop ed. In the literature, they we re initially emplo y ed to train radial basis function neural net works (P ogg io and Girosi, 1 990a): the idea of using them also for differen t neural a rc hitectures w as suggested for instance in (Cancelliere, 2001). The w ork b y Huang et al. (see for instance (Huang et al. , 2006)) gav e rise to a great interest in neural netw ork comm unit y: they presen ted the tec h- nique of Extreme Learning Mac hine (ELM) for whic h SLF Ns with randomly c hosen input w eights a nd hidden la y er biases can learn sets of observ ations with a desired precision, pro vided that a ctiv ation functions in the hidden la y er are infinitely differen tiable. Besides, b ecause o f the use of linear output neurons, output w eigh ts determination can b e brough t bac k to line ar systems solution, obta ined via Mo ore- Penrose generalised inv erse (or pseudoin v erse) of the hidden la y er output matrix; so doing itera t iv e training is no more required. Suc h tec hniques app ear any w ay to req uire mor e hidden units with respect to conv en tional neural net w ork training alg orithms to ac hiev e comparable accuracy , as discuss ed in Y u and Deng (Y u and D eng, 2012). Man y application-oriented studies in the last y ears hav e b een dev oted to the use of these single-pass tec hniques, easy to implemen t and computa- tionally fast; some are describ ed e.g. in (Nguye n et al. , 2010; Kohno e t al. , 2010; Ajorlo o et al. , 2007). A y early conference is cu rrently being held on the sub j ect, t he Inte rnatio nal Conference on Extreme Learning Machin es, and the metho d is curren tly dealt with in some journal sp ecial issue, e.g. Soft Computing (W ang et al. , 2012) and the In ternational Journal of Uncertain t y , F uzziness and Kno wledge-Based Systems (W ang, 2013). Because of the p ossible presence of singular and almost singular mat r ices, pseudoin v ersion is kno wn to b e a p ow erful but n umerically unstable method: nonetheless in the neural netw ork comm unity it is often used without singu- larit y c hec ks and ev aluated through appro ximated metho ds. In this pap er w e impro v e on the t heoretical f r a mew ork using singular v alue a nalysis to detec t the o ccurrence o f instability . Building on Tikhono v regularization, whic h is kno wn to b e effectiv e in this con text (Golub et al. , 1999), w e pres ent a tec hnique, named Optimally Conditioned Regularization for P seudoin v ersion (OCReP), that replaces unstable, ill-p osed problems with 2 w ell-p osed ones. Our a pproac h is based on the for ma l definition o f a new matricial for- m ulation that allows the use of condition n um b er as diagnostic to ol. In this con text an o ptimal v alue for the regularization parameter is analytically deriv ed by imp o sing w ell-conditioning requiremen ts on the relev an t matr ices. The issue of regularization parameter c hoice has often been iden tified as crucial in literature, and dealt with in a num ber of historical contributions: a conserv ative guess might put its published estimates at sev eral dozens. Some of the most relev an t works are men tioned in section 2, where the related theoretical bac kground is recalled. Its determination, mainly aimed at o ve rfitting con trol, has often b een done either exp erimen ta lly via cross-v alidation, requiring hea vy computa- tional training pro cedures, or analytically under sp ecific conditions on the matrices in v olv ed, sometimes hardly applicable to real dat asets, as discus sed in section 2. In section 3 w e presen t the basic concepts concerning input and output w eigh ts setting, and w e recall the main ideas on ill-p osedness, regularizatio n and condition n um b er. In section 4 o ur matricial framework is intro duced, and constraints on condition n um b er are imp osed in order to deriv e the optimal v alue for the regularization parameter. In section 5 our diagnosis and con trol to ol is tested on some applica- tions selec ted fro m the UC I database and v alidat ed by comparison with the framew ork regularized via cross-v alidation and with the unregularized one. The same datasets a re used in section 6 to test the tech nique effectiv e- ness: our p erformance is compared with those obtained in other regularized framew orks, originated in both statistical and neural domains. 2. Recap on ordinary least-square and ridge regression estimators As stated in the in tro duction, pseudoin v ersion based neural training brings bac k output w eights determination to linear sy stems solution: in this section w e recall some general ideas on this issue, that in next sec tions will b e sp e- cialized to deal with SLFN training. The estimate of β through ordinary least-squares (OL S) tec hnique is a classical to ol for solving the problem Y = X β + ǫ , (1) 3 where Y and ǫ are column n -ve ctors, β is a column p -v ector a nd X is a n n × p matrix; ǫ is random, with exp ectation v alue ze ro and v ariance σ 2 . In (Ho erl, 1962) and (Ho erl and Kennard, 1 9 70) the r ole of ordinary ridg e regression (ORR ) estimator ˆ β ( λ ) as an alternativ e to t he OLS estimator in the presence of multic ollinearity is deeply analized. In statistics, m ulti- collinearit y (also collinearit y) is a phenomenon in whic h t wo or more predictor v ar iables in a m ultiple regression mo del are highly correlated, meaning that one can be linearly predicted from the others with a no n- trivial degree of ac- curacy . In this situation, the co efficien t estimates of the m ultiple regression ma y c hange erratically in resp onse t o small c hanges in the mo del or the data. It is known in literature that there exist estimates of β with smaller mean square error (MSE) than the un biased, or Gauss-Mark ov, estimate (Golub et al. , 1979; Berger, 19 76) ˆ β (0) = ( X T X ) − 1 X T Y . (2) Allo wing fo r some bias may result in a significan t v ariance reduction: this is know n as the bias-v aria nce dilemma ( see e.g. (Tibshirani, 1996; Geman et al. , 1992), whose effects o n output w eigh ts determination will b e deep ened in section 3.2. Hereafter w e fo cus o n the one parameter family of ridge estimates ˆ β ( λ ) giv en b y ˆ β ( λ ) = ( X T X + nλI ) − 1 X T Y . (3) It can b e sho wn that ˆ β ( λ ) is also the solution to the problem of finding the minim um o v er β of 1 n || Y − X β | | 2 2 + λ || β || 2 2 , (4) whic h is known as the metho d of r egularization in the appro ximation theory literature (Golub et al. , 1979); ba sing on it we will dev elop the theoretical framew ork for our w ork in the next sections. There has alw ays b een a substantial a mount of in terest in estimating a go o d v a lue of λ from the data: in addition to those already cited in this section a non-exhaustiv e list of well kno wn or more r ecen t pap ers is e.g (Ho erl and Kennard, 1976; La wless and W ang, 1976; McDonald and Galarneau, 1975; Nordb erg, 19 8 2; Saleh and Kibria, 1993; Kibria, 2003 ; Khalaf and Sh ukur, 2005; Mardiky a n and Ce tin , 2008). 4 A meaningful review of these formulations is prov ided in (Doruga de a nd Kashid, 2010). They first define the matrix T suc h that T T X T X T = Λ (Λ = diag ( λ 1 , λ 2 , · · · λ p ) con tains t he eigen v alues of the matrix X T X ); then they set Z = X T and α = T T β , and sho w that a great amoun t of differen t metho ds require the OL S estimates of α and σ ˆ α = ( Z T Z ) − 1 Z T Y , (5) ˆ σ 2 = Y T Y − ˆ α T Z T Y n − p − 1 . (6) to define effectiv e ridge parameter v alues. It is importa nt to note that often sp ecific conditions on dat a are needed to ev aluate these estimators. In particular this applies to the expressions of the ridge parameter pro- p osed b y (Kibria, 2003) and (Ho erl and Kennard, 19 70), that share the c har- acteristic o f b eing functions of the ratio betw een ˆ σ 2 and a function o f ˆ α ; they will be used for comparison with our prop osed me tho d in se ction 6. The alternativ e tec hnique of generalised cross-v alidatio n (GCV) prop osed b y (Go lub e t al. , 1979) prov ides a g o o d estimate of λ from the data as the minimizer of V ( λ ) = 1 n || I − A ( λ ) Y || 2 2 1 n T race( I − A ( λ )) 2 2 , (7) where A ( λ ) = X ( X T X + nλI ) − 1 X T . (8) This solution is part icularly in teresting, since it do es not require an es- timate of σ 2 : b ecause of this, it will b e one term of comparison with o ur exp erimental results in section 6. In the next section w e will sho w how the pro blem of finding a go o d so- lution to (1) applies to the con text of pseudoin v ersion based neural training, sp ecializing the in v olv ed relev an t matricies to deal with this issue. 3. Main ideas on regularization and condition n um b er theory 3.1. Gener alise d inverse matrix for weights setting W e deal with a standard SLFN with L input neurons, M hidden neurons and Q output neurons, non-linear activ a t io n functions φ in the hidden lay er and linear activ ation functions in the output lay er. 5 Considering a dataset of N distinct training sample s ( x j , t j ), where x j ∈ R L and t j ∈ R Q , the learning pro cess for a SLFN aims at pro ducing the matrix of desired outputs T ∈ R N × Q when the matrix of all input instances X ∈ R N × L is prese nted as input. As stated in the in tro duction, in the pseudoin v erse appro ac h t he mat rix of input we ights and hidden lay er biases is randomly c hosen and no longer mo dified: w e name it C . After having fixed C , the hidden lay er output matrix H = φ ( X C ) is completely determined; w e underline that since H ∈ R N × M , it is not inv ertible. The use of line ar output neurons allows to determine the output w eigh t matrix W ∗ in terms of the OLS solution to the pro blem T = H W + ǫ , in analogy with eq.(1 ). Therefore fro m eq.(2 ), w e ha v e W ∗ = ( H T H ) − 1 H T T (9) According to (P enrose and T o dd, 1956; Bishop, 2006) W ∗ = H + T . (10) H + is the Mo ore-Penrose pseudoinv erse (or generalized in v erse) of matrix H , and it minimises the cost f unctional E D = | | H W − T || 2 2 (11) Singular v alue decomp osition (SVD) is a computationally simple and ac- curate w ay to compute the pseudoin v erse (see for instance ( Golub and V an Loan, 1996)), as fo llo ws. Ev ery matrix H ∈ R N × M can b e expressed as H = U Σ V T , (12) where U ∈ R N × N and V ∈ R M × M are orthogonal matrices and Σ ∈ R N × M is a rectangular diagonal matrix (i.e. a matrix with σ ih = 0 if i 6 = h ); its elemen ts σ ii = σ i , called singular v a lues, are non-negativ e. A common con v en tion is to list the singular v alues in desc ending order, i.e. σ 1 ≥ σ 2 ≥ · · · ≥ σ p > 0 (13) where p = min { N , M } , so that Σ is uniquely determined. The SVD of H is then used to o btain the pseu doinv erse matrix H + : 6 H + = V Σ + U T , (14) where Σ + ∈ R M × N is aga in a r ectangular diagonal matr ix whose elemen ts σ + i are obtained b y ta king the recipro cal of eac h corresp onding eleme nt: σ + i = 1 /σ i (see also (R a o and Mitra , 1971)). F rom eq.(9) w e tha n ha v e: W ∗ = V Σ + U T T , (15) Remark An in teresting case o ccurs whe n only k < p elemen ts in eq.(13) are non- zero, i.e. σ k +1 = · · · = σ p = 0; in this case the rank of matrix H is k and Σ + is defined as: Σ + = diag (1 /σ 1 , · · · , 1 /σ k , 0 , · · · , 0 ) ∈ R M × N , (16) as sho wn for instance in (Golub and V an Loan, 1996). This is also often done in practice, for computat io nal reasons, for ele- men ts smaller than a predefined threshold, th us actually computing an ap- pro ximated v ersion of the pseudoin v erse matrix H + . This approac h is for example used by default for pseudoin v erse ev aluation b y means of t he Matla b pin v function 1 , b ecause the t o ol is wide ly used b y man y scien tists for example in ELM contex t, eac h time that it is applied blindly , i.e. without ha ving decided at what threshold to zero the small σ i , an appro ximation a priori uncon trolled is in tro duced in H + ev aluatio n. 3.2. Stability a n d gener alization pr op erties of r e gularization algorithms A k ey prop ert y fo r any learning algorithm is stabilit y: the learned map- ping has to suffer only small changes in presence of small perturbations (for instance the dele tion of one example in t he training set). Another imp ortant prop erty is generalization: the p erformance on the training examples (empirical error) must b e a go o d indicator o f the p erfor- mance on future examples ( expected erro r ), that is, the difference b et w een the t wo m ust b e small. An algorithm that g uaran tees g o o d g eneralization predicts w ell if its empirical error is small. 1 ht tp:// www.mathw orks.co m/ help/matlab/r e f/pin v.html. 7 Man y studies in literature dealt with the connection b etw een stabilit y and generalization: the notion of stabilit y has b een in v estigated by sev eral au- thors, e.g. b y Devro y e and W agner (Devroy e a nd W agner, 1979) and Kearns and Ron (Kearns and Ron, 1999). P oggio et al. in (Mukherjee et al. , 200 3) in tro duced a statistical form of leav e-one-out stabilit y , named C V E E E loo , building on a cross-v alidat io n lea v e-one-out stabilit y endo w ed with conditio ns on stability of b o th exp ected and empirical errors; t hey demonstrated t ha t this condition is necessary and sufficien t for generalization and consistency of the class o f empirical r isk min- imization (ERM) learning algorithms, and tha t it is also a sufficien t condition for generalisation for not ERM algorithms (see also (Poggio et al. , 2004)). T o turn an original instable, ill-p osed problem in to a w ell-p osed one, reg- ularization metho ds of the fo rm (4) are often used (Badev a and Morozov, 1991) and among t hem, Tikhono v regularizatio n is one of the most com- mon (Tikhono v and Arsenin, 1 9 77; Tikhono v, 1963). It minimises the error functional E ≡ E D + E R = || H W − T || 2 2 + || Γ W || 2 2 , (17) obtained adding to the cost functional E D in eq.(11) a p enalt y term E R that dep ends on a suitably chosen Tikhono v matrix Γ. This issue has b een discusse d in its applications to neural net w orks in (P og g io and G irosi, 1990 b), and surv eye d in (Girosi et al. , 1995; Ha ykin, 1999). Besides, Bousquet and Elisseeff (Bousquet and Elisseeff , 2002) prop osed the notion of uniform stability to c haracterize the generalization prop erties of an algorithm. Their results state tha t Tikhono v regularizatio n algorithms are uniformly stable and t ha t uniform stability implies go o d g eneralization (Mukherjee et al. , 2006). Regularization th us in tro duces a p enalt y function that not only impro v es on stabilit y , ma king the problem less sensitiv e to initial conditions, but it is also important to contain mo del complex ity a v oiding ov erfitting. The idea of p enalizing by a square function of w eigh ts is also w ell kno wn in neural litera t ure as we ight decay : a wide amount of a rticles hav e b een dev oted to this arg ument, and more generally to the adv an tage of regulariza- tion for the control of ov erfitting. Among them w e recall (Hastie et al. , 2009; Tibshirani, 1996; Bishop , 2006; Girosi et al . , 19 95; F u, 1998; Ga llinari and Cibas, 1999). A frequen t c hoice is Γ = √ γ I , to give preference to solutions with smaller 8 norm (Bishop, 2006), so eq. (17) can be rewritten as E ≡ E D + E R = | | H W − T || 2 2 + γ || W || 2 2 . (18) W e define ˆ W = min W ( E ) the regularized solution of (18): it b elongs to the family of ridge estimates described by eq .(3 ) and can b e expressed as ˆ W = ( H T H + γ I ) − 1 H T T (19) or, as shohw in ((F uhry and Reic hel, 2012)) as ˆ W = V D U T T . (20) V and U are fr o m the singular v alue decomp osition of H (eq.(12)) and D ∈ R M × N is a rectangular diagonal matrix whose elemen ts, built using the singular v alues σ i of matrix Σ, a re: D i = σ i σ 2 i + γ . (21) W e remark on the difference b et w een the minima o f the regularized and unregularized error functionals. Increasing v alues of the regularizatio n pa- rameter γ induce larger and larger departure of the former (eq. (19)) f rom the latter (eq. (9)). Th us, the regularization pro cess increases the bias of the appro ximating solution and reduces its v ariance, as discussed a b out the bias-v a riance dilemma in section 2. A suitable v alue for the Tikhono v parameter γ has therefore to deriv e from a compromise b et w een ha ving it sufficien tly large to con trol the approac hing to zero of σ i in eq.(21), while a voiding an exce ss of the p enalt y term in eq.(18). Its tuning is therefore crucial. 3.3. Condition numb er a s a me asur e of il l-p ose dness The condition num ber of a mat r ix A ∈ R N × M is the n umber µ ( A ) defined as µ ( A ) = || A || || A + || (22) where k·k is an y matrix nor m. If the columns (rows ) of A are linearly inde- p enden t, e.g. in case of experimental dat a matrices, then A + is a left (righ t) in v erse of A , i.e. A + A = I N ( AA + = I M ). The Cauch y- Sc h w arz inequalit y in this cas e then pro vides µ ( A ) ≥ 1; b esides, µ ( A ) ≡ µ ( A + ) . Matrices are said to b e ill-conditioned if µ ( A ) ≫ 1 . 9 If k·k 2 norm is use d, then µ ( A ) = σ 1 ( A ) σ p ( A ) , (23) where σ 1 and σ p are the largest and smallest singular v alues of A resp ectiv ely . F r o m eq.(23) w e can easily understand that large condition num b ers µ ( A ) suggest the presence o f v ery small singular v alues (i.e. of almost singular matrices), whose numerical inv ersion, required t o ev aluate Σ + and the un- regularized solution W ∗ , is a cause of instability . F r o m n umeric linear algebra we also kno w that if the condition n um b er is lar g e the problem of finding least- squares solutions to the corresp o nd- ing system of linear equations is ill- p osed, i.e. ev en a small p erturbation in the data can lead to h uge p erturbations in the entries o f solution (see (Golub and V an Loan, 1996)). According to (Mukherjee et al. , 2006) the stability of Tikhono v regular- ization algorithms can also b e c hara cterized using the classical notion of con- dition n um b er: our prop osed regularization metho d fits within this con text. W e will see that it specifically aims at ana litically determining the v alue of the γ para meter that minimizes the conditio ning o f the r egula rized hidden la y er output matrix so that the solution ˆ W is stable in the sense of eq.(2.9) of (Mukhe rjee et al. , 2006). In the next section, w e will derive the o pt ima l v alue of the regulariza- tion pa r a meter γ according to this stabilit y criterion (minimu m condition n um b er). The exp erimen tal results presen ted in sections 5 and 6 will evide nce that our quest for stable solutions allo ws us to also a chiev e go o d generalization and predictivit y . A comparison will b e made to this purp ose with the p erformance obtained when γ is determined via the standard cross-v alidation approach, aimed at ov erfitting con trol and generalization p erformance optimization. 4. Conditioning of the regularized matricial framew ork F o r con v enien t implemen tation of our diagnostics, and building on eq.(20), w e pro p ose an origina l matricial framew ork in whic h to dev elop our study to ol with the fo llo wing definition. Definition 1. We define the matrix H r eg ≡ V D U T (24) 10 as the regularized hidden layer output ma trix of the neur al network. This allo ws us to rewrite eq.(20) as ˆ W = H r eg T , (25) for similarit y with eq.(9). By construction, H r eg is decomp o sed in three matrices according to the SVD framew ork, and its singular v a lues are pro vided by eq.(21) as a function of the singular v alues σ i of H . This new regularized matricial framework mak es easier the comparison of the prop erties of H r eg with those of the corresp o nding unregularized matrix H + . In fact, when unregularized pseudoin v ersion is used, nothing prev en ts the o ccurrence of v ery small singular v a lues that mak e n umerically instable the ev aluation o f H + (see eq. 14). On the con trary , ev en in presence of v ery small v alues σ i of the original unregularized problem, a careful c hoice of the parameter γ allows to tune the singular v alues D i of the r egula rized matrix H r eg , prev en ting n umerical instability . 4.1. Condition numb er d e finition According to eq. (23), w e define the condition n um b er of H r eg as: µ ( H r eg ) = D max D min . (26) where D max and D min are the largest a nd smallest singular v a lues of H r eg . The shap e of the functional relation σ / ( σ 2 + γ ) that links regularized and unregularized singular v alues, defined through eq. (21), is show n in Fig.1 for three differen t v alues of γ . The curv es are no n- negativ e, b ecause σ > 0 and γ > 0, and hav e only one maxim um, with coordina t es ( √ γ ; 1 2 √ γ ). A few pairs of corresponding v alues ( D i , σ i ) are mark ed b y dots on eac h curv e. F o r the sak e of the determination of µ ( H r eg ) w e are in terested in ev a lu- ating D max and D min of H r eg o v er the finite, discrete range [ σ 1 , σ 2 , . . . , σ p ]. The v alue D max is reac hed in corresp ondence to a giv en singular v alue of H , a priori not kno wn, that w e lab el σ max , so that: D max = σ max σ 2 max + γ . (27) 11 σ σ / ( σ 2 + γ ) Figure 1 : Exa mple of regularized/unr egularized singula r v alues relationship via eq. (21) The v ariation of γ has t he effect of changing the curv e and shifting its maxim um p o in t within the in terv al [ σ 1 , σ p ]. Therefore, σ max can coincide with an y singular v alue of H fro m eq. (1 3 ), includin g the extreme ones. Con v ersely , we no w demonstrate that D min can only b e reac hed in corre- sp ondence to σ 1 or σ p (or bo t h when coinciden t). Theorem 3.1 The minim um singular v alue D min of matrix H r eg can only b e reac hed in corresp ondence to the largest singular v alue σ 1 or to the s mallest singular v alue σ p of the unregularized matrix H (or b oth). Pr o of. Without loss of generalit y , w e can express γ as a function of σ 1 σ p , i.e. γ = β σ 1 σ p , where β is a real po sitiv e v alue. By replaceme nt in eq. (21), we get D 1 = 1 σ 1 + β σ p , D p = 1 σ p + β σ 1 T o establish their ordering, w e ev aluate the difference ∆ of their inv erses : ∆ = 1 D 1 − 1 D p = ( σ 1 + β σ p ) − ( σ p + β σ 1 ) = (1 − β )( σ 1 − σ p ) . 12 Recalling that σ 1 − σ p > 0 , w e can distinguish three case s: Case 1, β > 1 ( γ > σ 1 σ p ) → ∆ < 0 → D 1 > D p Because of the D i distribution shape, D p is a lso the minim um among all v alues D i , so that D min ≡ D p . Case 2, β < 1 ( γ < σ 1 σ p ) → ∆ > 0 → D 1 < D p Then, D 1 is also the minim um a mong all v alues D i , so that D min ≡ D 1 . Case 3, β = 1 ( γ = σ 1 σ p ) → ∆ = 0 → D 1 = D p Th us, D 1 and D p are both minima, so that D min ≡ D 1 = D p . 4.2. Condition numb er e v aluation The result b y Theorem 3.1 allo ws us to find, a ccording to eq. (26), the follo wing expressions for µ ( H r eg ) : Case 1, β > 1 : µ ( H r eg ) = D max D p = σ max ( σ p + β σ 1 ) σ 2 max + β σ 1 σ p Case 2, β < 1 : µ ( H r eg ) = D max D 1 = σ max ( σ 1 + β σ p ) σ 2 max + β σ 1 σ p Case 3, β = 1 : µ ( H r eg ) = D max D p = D max D 1 = σ max ( σ p + σ 1 ) σ 2 max + σ 1 σ p Bearing in mind that well-conditioned problems are c ha racterized b y small condition num bers, w e no w will lo ok for the β parameter v alues whic h, in the three cases ab ov e, make the regularized condition n umber smaller. In Case 1, µ ( H r eg ) is an increasing function of β , so that in its domain, i.e. (1 , ∞ ), it s minim um v alue is reac hed when β → 1 + . On the con trary , in Case 2, µ ( H r eg ) is a decreasing function of β , so that in its domain, i.e. (0 , 1), the minim um is reache d when β → 1 − . Fig.2 sho ws the function b eha viour o ve r the whole domain. Both cases ha v e a common limit: 13 1 β µ (H reg ) Figure 2 : Regular ized condition n umber vs. β lim β → 1 + µ ( H r eg ) = lim β → 1 − µ ( H r eg ) = σ max ( σ p + σ 1 ) σ 2 max + σ 1 σ p (28) Suc h v alue is just that provided b y Case 3, whic h can therefore be consid ered the best p ossible c hoice to minimize the condition num ber. Th us our quest for the b est p ossible conditioning for the matrix H r eg iden tifies an explicit optimal v alue for the regular izat io n parameter γ : γ = σ 1 σ p (29) 5. Sim ulation and Discussion F o r the n umerical experimentation, we use eight b ench mark datasets from the UCI rep ository (Bac he and Lic hman, 2013) listed in T able 1. All sim u- lations are carried out in Matlab 7.3 env ironment. The p erformance is assessed b y statistics o v er a set of 50 differen t extrac- tions of input w eigths, computing either the a ve rag e RMSE (for regression tasks) o r the a ve rag e p ercen tage of misclassification ra t e (for classification tasks) on the test set. Either quantit y is lab eled “Err” in t he tables sum- marising our results. The error standard deviation (lab eled “Std”) is also computed to ev idence the disp ersion of experimental results. 14 Dataset T yp e N. Instances N. A ttributes N. Classes Abalone Regression 4177 8 - Mac hine Cpu Regression 209 6 - Delta Ailerons Regression 7129 5 - Housing Regression 506 13 - Iris Classification 150 4 3 Diab etes Classification 768 8 2 Wine Classification 178 13 3 Segmen t Classification 2310 19 7 T able 1: T he UCI datasets and their c harac teristics Our regularization strategy , lab eled Optimally Conditioned Regulariza- tion for Pse udoinv ersion (OCReP), is v erified by sim ulation against t he com- mon approa c h in whic h cross-v alidation is used i) to determine the regular- ization para meter γ at a fixed high num b er of hidden neurons and ii) to p erform also hidden neurons n umber optimization, resp ectiv ely in sec. 5.1 and 5.2. A discussion of the effectiv eness o f OCReP in terms of minimization of the condition n um b er of the in v olv ed matricies is done in se c. 5.3. 5.1. OCR eP p erformanc e assessment: fixe d numb er of hidden units In this section we compare OCReP with a regularization approac h in whic h γ is selected b y a cross-v alidation sc heme, whic h is t ypically used for con trol of under/o v erfitting and optimization o f the mo del generalization p erformance. A 70%/30 % split b etw een training and test set is applied; t hen, a three-fold cross-v alidation searc h on the training set iden tifies the b est γ b y b est p erformance on the v a lidation set, ov er the set of 5 0 v alues of γ [10 − 25 , 10 − 24 , · · · 10 25 ]. F o r the sake o f comparison, a fixed, high num b er of hidden units M is used, selected a ccording to dimension and complexit y o f the datasets. F or the three datasets Mac hine Cpu, Iris and Wine the sim ulation is perfo rmed for 50 and 1 00 hidden neurons; for Abalone, D elta Ailerons, Housing and Diab etes, we use 5 0, 1 00, 200 and 300 neurons; for Segmen t, w e use 100 0 and 1500 units. Figures 3 and 4 ( resp ectiv ely for regression and classification datasets) sho w a v erage test errors as a function of the sampled v a lues of γ (red dots); 15 10 −10 10 −5 10 0 2 2.5 3 3.5 Abalone (M=300) γ RMSE 10 −10 10 −5 10 0 1.4 1.6 1.8 2 2.2 2.4 2.6 2.8 x 10 −4 Delta Ailerons (M=300) γ RMSE 10 −10 10 −5 10 0 0 100 200 300 400 500 600 700 Machine Cpu (M=100) γ RMSE 10 −10 10 −5 10 0 0 5 10 15 20 25 30 35 40 45 Housing (M=300) γ RMSE Figure 3: T est error trends for regression datasets as a function of the v alues of γ ov er the selected cross-v alidation rang e (red dots): the cross- v alidation selected γ is the bla ck square; the prop osed γ from OCReP is the blue circle. the standard deviation is sho wn as an error bar. Our prop o sed optimal γ is evidenced as a blue circle, whereas the v alue of γ selected b y cross-v alidation is sho wn a s a black square. The results a re in eac h case related to the hig hest n um b er o f neurons ex p erimented . The horizontal axis has b een zo omed in o nto the region of in terest, i.e. [10 − 10 , 10 5 ]. It ma y b e not ed that the p erformance from OCReP and cross-v alidation are comparable, and a lso close to the experimen tal minimum. This ma y b e in terpreted as go o d predictivit y for b o th algorithms. Also, w e remark that the error bars, i.e. experimen tal result dispersion, 16 10 −10 10 −5 10 0 0 5 10 15 20 25 30 Iris (M=100) γ Mean Miscl. Err. [%] 10 −10 10 −5 10 0 0 2 4 6 8 10 12 14 16 18 Wine (M=100) γ Mean Miscl. Err. [%] 10 −10 10 −5 10 0 22 24 26 28 30 32 34 Diabetes (M=300) γ Mean Miscl. Err. [%] 10 −10 10 −5 10 0 0 5 10 15 20 25 30 35 Segment (M=1500) γ Mean Miscl. Err. [%] Figure 4: T est erro r trends for class ification datasets as a function of the v alues of γ ov er the selected cross-v alidation rang e (red dots): the cross- v alidation selected γ is the bla ck square; the prop osed γ from OCReP is the blue circle. 17 is large for small v alues o f γ , consisten tly with exp ectations on ineffectiv e regularization. T able 2 : Compariso n of OCReP vs. cross-v alidation at fixed num b er of hidden neuro ns for small size datasets Iris Wine Mac hine Cpu M 50 OCReP Err. 1 . 51 2 . 98 31 . 21 Std 1 . 13 1 . 75 1 . 1 cross-v al. Err. 2 . 13 3 . 37 31 . 1 Std 0 . 77 2 . 27 1 . 02 100 OCReP Err. 2 . 53 1 . 39 34 . 13 Std 0 . 77 1 . 19 01 . 6 8 cross-v al. Err. 2 . 17 1 . 8 8 30 . 94 Std 0 . 31 1 . 88 0 . 69 T able 3 : Compariso n of OCReP vs. cross-v alidation at fixed num b er of hidden neuro ns for lar ge size data sets Segmen t M 1000 OCReP Err. 2 . 53 Std 0 . 77 cross-v al. Err. 2 . 17 Std 0 . 31 1500 OCReP Err. 4 . 41 Std 0 . 45 cross-v al. Err. 3 . 97 Std 0 . 35 The n umerical results hav e been reported in T a b. 2, 3 and 4 according to the grouping ba sed on dimension and complexit y of the datasets. F o r each dataset and selec ted n um b er of hidden neurons M , the b est test error is evidenced in b o ld, whenev er the difference is statistically significan t 2 . 2 The Student’s t-test has been used for assessing the s tatistical significa nce through 18 T able 4 : Compariso n of OCReP vs. cross-v alidation at fixed num b er of hidden neuro ns for medium size datasets. F o r Delta Ailerons, av er age erro rs and standard deviatio ns have to b e m ultiplied b y 1 0 − 4 . Abalone D elta Ailerons Housing Diabetes M 50 OCReP Err. 2 . 22 1 . 64 5 . 54 26 . 01 Std 0 . 16 0 . 0051 0 . 12 0 . 604 cross-v al. Err. 2 . 13 1 . 59 4 . 79 26 . 79 Std 0 . 017 0 . 0073 0 . 37 0 . 814 100 OCReP Err. 2 . 15 1 . 62 5 . 17 25 . 66 Std 0 . 007 0 . 004 0 . 08 0 . 608 cross-v al. Err. 2 . 11 1 . 58 4 . 49 25 . 71 Std 0 . 006 0 . 0036 0 . 28 0 . 608 200 OCReP Err. 2 . 12 1 . 59 4 . 62 25 . 13 Std 0 . 003 0 . 0031 0 . 09 0 . 445 cross-v al. Err. 2 . 11 1 . 61 4 . 30 25 . 79 Std 0 . 003 0 . 0096 0 . 27 0 . 443 300 OCReP Err. 2 . 113 1 . 58 4 . 24 24 . 26 Std 0 . 03 0 . 0018 0 . 13 0 . 689 cross-v al. Err. 2 . 114 1 . 60 4 . 18 25 . 66 Std 0 . 003 0 . 0042 0 . 23 0 . 456 Th us, for example, on Iris the b est p erfo rmance is ac hiev ed using 5 0 neu- rons b y OCReP , and with 100 neurons by cross-v alidatio n. In some cases, e.g. Wine (50 neurons), there is no clear winner fro m statistical considerations, i.e. the b est results are comparable, within the errors. F r o m the ab o v e results it app ears that cross-v alidation ha s b etter test error p erformance o n a n umber of datasets slightly higher, at fixed n um b er of hidden neurons. Ho w ev er, it is imp o rtan t to eviden ce that the use of OCReP allows to sa v e the hu ndreds o f pseudoin v ersion steps required b y cross-v alidat io n, wic h is a crucial issue for practical impleme ntation. determination o f the confidence in terv als r elated to 99% confidence level. 19 5.2. OCR eP p erformanc e assessment: variable numb er of hidden units In o rder to pursue the double aim of p erformance and hidden units opti- mization, a first in teresting step is t o giv e a lo ok to the v a riation as a function of hidden lay er dimension of error trends of unregularized mo dels ( i.e. mo dels whose output weigh ts are ev aluated according to eq.(10)). A con text widely used among researc hers using suc h tec hniques (see e.g. Helm y and Rasheed (2009); Huang et al. (2006)) is to us e input w eigh ts dis- tributed according to a random uniform distribution in the interv al ( − 1 , 1), and sigmoidal activ ation functions for hidden neurons: hereafter w e name this framew ork Sigm-unreg. 0 50 100 150 200 250 300 2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 Abalone Number of hidden neurons RMSE Sigm−unreg OCReP 0 50 100 150 200 250 300 1 2 3 4 5 x 10 −4 Delta Ailerons Number of hidden neurons RMSE Sigm−unreg OCReP 0 20 40 60 80 100 0 100 200 300 400 500 600 700 800 900 Machine Cpu Number of hidden neurons RMSE Sigm−unreg OCReP 0 50 100 150 200 250 300 0 5 10 15 20 25 30 35 Housing Number of hidden neurons RMSE Sigm−unreg OCReP Figure 5: T es t error tre nds for regression datasets: OCReP vs. unreg ularized pseudoin- version. Figures 5 and 6 sho w, resp ectiv ely fo r regression and classification datasets, 20 the a v erage test error v alues, (ov er 50 differen t input w eigh ts sele ctions) for b oth OCReP (blue line) and Sigm-unreg (red line) as a function of the n um- b er of hidden no des, whic h is gra dually increased by unit y steps. In all cases, after an initial decrease the Sigm-unreg test error increases significan tly . On the con trary , the OCReP test error curv es keep decreasing, alb eit a t slo w er and slo w er rate, th us showing also a go o d capa bility of o v erfitting con trol of the method. W e aim no w at comparing t he results obtained when the tr ade-off v alue of γ is searc hed b y cross-v alidation, with t he tw o differen t framew orks discussed so far, i.e. OCReP and Sigm- unreg. A 70 %/ 3 0% split b et w een tr a ining and test set is applied; w e t hen p erform a three-fold cross-v alidation for the selection of the num b er of hidden neurons ¯ M at whic h the minim um error is recorded in all cases. T est errors are again ev aluated as the a v erage of 50 differen t random c hoices of input we ights. The n umerical results of the sim ulation are presen ted in T ables 5 and 6, resp ectiv ely for regression and classification tasks, with their standard deviations (Std) and ¯ M . Best test errors ar e evidenced in b o ld, whenev er the difference b et w een OCReP and cro ss-v alidation is statistically significan t. W e see that our pro p osed regularization techniq ue provides , for regres- sion datasets, p erformance comparable with the cross-v a lida tion option but alw a ys a better p erforma nce (with statistical significance at 99% lev el) with resp ect to the unregularized case. F o r classification datatsets in three cases out of four OCReP provides a b etter p erfo rmance with resp ect to cross-v alidation, and alwa ys a b etter p erformance with resp ect to the Sigm-unreg case. In all suc h cases, the statistical significance is at the 99% lev el. Also, in almost all cases smaller standard deviations are asso ciated with the OCReP metho d, suggesting a low er sensitivit y t o initial input we ights conditions. 5.3. A dd itional c onsider ations The prop osed metho d OCReP presen ts in o ur opinion t wo f eat ures of in terest: on one side, its computational efficienc y , and on the ot her side its optimal conditioning. Our goal o f optimal analytic determination of the regularization param- eter γ results in a dra matic improv ement in the computing requiremen ts with respect to exp erimen tal tuning b y searc h ov er a pre-defined larg e grid 21 0 20 40 60 80 100 0 10 20 30 40 50 60 70 Iris Number of hidden neurons Mean Miscl. Err. [%] Sigm−unreg OCReP 0 20 40 60 80 100 0 10 20 30 40 50 60 70 Wine Number of hidden neurons Mean Miscl. Err. [%] Sigm−unreg OCReP 0 50 100 150 200 250 300 18 20 22 24 26 28 30 32 Diabetes Number of hidden neurons Mean Miscl. Err. [%] Sigm−unreg OCReP 0 200 400 600 800 1000 0 5 10 15 20 25 30 35 40 Segment Number of hidden neurons Mean Miscl. Err. [%] Sigm−unreg OCReP Figure 6 : T est err or trends for classifica tion datasets: O CReP vs. unr egularized pseudo in- version. of N γ ten tativ e v alues. In the latt er case, fo r eac h c hoice of γ o v er the se- lected range, at least a pseudoin v ersion is required for ev ery output w eigh t determination, th us increasing the computational load by a factor N γ . Besides, our metho d is designed explicitly fo r optimal conditioning. In our sim ulations, w e v erify that t he g o al is fulfilled by ev aluating a v erage conditio n n um b ers of hidden lay er output matrices. The stat istics is p erformed o v er 50 differen t configurations of input we ights a nd a fixed n umber of hidden units, namely the largest used in section 5.1 for each dataset. The results are summarised in T ables 7 and 8, resp ectiv ely for regression and classification datasets. On the first row of each table, w e list the ratio of a ve rag e condition n um b ers o f matrices H r eg , and H + , asso ciated resp ectiv ely to OCReP and Sigm-unreg, i.e. regularized and unregularized approac hes. On the second 22 ro w, w e list the ratio of av erage conditio n n um b ers of matrices H r eg and H C V , th us comparing our regula r ization approac h with t he more con v en tional o ne, the latter using cross-v alidation. Not surprisingly , our regularization metho d provides a s ignificant im- pro v emen t o n conditioning with resp ect to the unregularized approach, as evidenced by ratio v alues m uc h smaller than unity . Besides, OCReP also pro vides b etter conditioned matrices tha n those deriv ed b y selection of γ through cross-v alidatio n, s ince the corresp onding condition n umbers are sys- tematically smaller in the former case, sometimes up to an order of magni- tude. T able 5: Hidden layer optimization for reg ression tasks. F or Delta Ailer ons, av erag e errors and standar d deviations ha ve to b e m ultiplied b y 10 − 4 . Abalone Housing Delta Ailerons Mac hine Cpu OCReP Err. 2 . 12 4 . 25 1 . 58 31 . 22 Std. 0 . 32 0 . 13 0 . 0048 0 . 78 ¯ M 178 255 29 8 63 Cross-v alidatio n Err. 2 . 11 4 . 19 1 . 58 31 . 51 Std. 0 . 0097 0 . 25 0 . 0036 1 . 25 ¯ M 110 250 93 70 Sigm-unreg Err. 2 . 14 4 . 73 1 . 62 34 . 44 Std. 0 . 014 0 . 20 0 . 57 2 . 89 ¯ M 31 76 74 15 6. Comparison wit h other approac hes Since the literature prov ides a host of differen t recip es f or either the choice of the regularization parameter, or the actual regularization algorithm, here- after w e fo cus on a couple of specific framew orks. 6.1. Other cho i c es of r e gularization p ar ameter Among the approac hes mentioned in section 2, w e primary select the tec hnique of generalised cross-v alidation (G CV) from (Golub et al. , 1979), 23 T able 6: Hidden lay er optimization for class ification tasks. Iris Wine D iab etes Segment OCReP Err. 1 . 6 1 . 73 25 . 53 2 . 50 Std. 1 . 1 0 1 . 25 0 . 51 0 . 32 ¯ M 67 91 291 760 Cross-v alidatio n Err. 2 . 1 2 2 . 10 25 . 2 2 . 65 Std. 1 . 2 6 2 . 27 1 . 29 0 . 38 ¯ M 14 137 25 620 Sigm-unreg Err. 2 . 3 1 3 . 20 25 . 92 4 . 45 Std. 1 . 4 8 2 . 09 1 . 12 0 . 47 ¯ M 67 91 291 760 T able 7: C o ndition num b er compa rison for regression datas ets Abalone Housing Delta Ailerons Mac hine Cpu µ ( H r eg ) /µ ( H + ) 0 . 0002 0 . 0008 0 . 00007 0 . 0001 µ ( H r eg ) /µ ( H C V ) 0 . 8 0 . 3 0 . 3 0 . 1 described b y eqs. ( 7 ) and (8), for comparison with our metho d. The main motiv a tion for our c hoice is its indep endence on the estimate of the error v ari- ance σ 2 , whic h is a characteristic shared with our case. F or eac h dataset, w e select the same fixe d num bers of hidden units a s in sec tion 5.1: then for eac h case eq. (7) is minimized o v er the set of 50 v alues of γ [1 0 − 25 , 10 − 24 · · · 10 25 ] and for 50 differen t configurations of input w eigh ts. W e ev aluate the mean and standard deviation of the cor r espo nding regu- larized test error, rep orted in T ables 9, 10 and 11. W e also remind tha t the tabulated error “Err” is either t he a v erage RMSE for regression tasks, or t he a v erage misclassification rate for classification t asks; “Std” is the corr espo nd- ing standard deviation. The p erformance comparison is based on statistical significance at 9 9 % lev el. Whenev er GCV provid es test error v alues statistically b etter than OCReP 24 T able 8: Co ndition num b er comparison for c la ssification datas ets Iris Wine Diab etes Segmen t µ ( H r eg ) /µ ( H + ) 0 . 00002 0 . 005 0 . 00 07 0 . 000005 µ ( H r eg ) /µ ( H C V ) 0 . 2 0 . 4 0 . 1 0 . 2 T able 9: GCV results at fixed num b er of hidden neuro ns for small datasets Iris Wine Machine Cpu M 50 Err. 2 . 47 3 . 66 33 . 03 Std 1 . 06 2 . 42 1 . 27 100 Err. 3 . 06 3 . 77 36 . 06 Std 1 . 08 2 . 44 1 . 13 (listed in T ab. 2, 3 and 4), they are mark ed in bold. W e remark that in all cases listed in T ab. 2 and 3 OCReP prov ides sta- tistically b etter results than GCV. The situation o f medium size data sets evidences a somewhat mixed b eha viour: with 50 hidden neurons, GCV wins; with 100 neurons, for three out of f our data sets (i.e. Abalone, Housing and Diab etes) the p erformance is statistically comparable. In all other cases of T ab. 4 OCReP a gain pro vides b etter statistical results than G CV. W e mak e t w o ot her comparisons, using the ridge estimates described in eq.(13) and eq.(9) of (Dorugade and Kashid, 201 0), and pr o p osed resp ec- tiv ely b y (Kibria, 2003) and (Ho erl and Kennard , 1970): T able 10: GCV results a t fixed n umber o f hidden neurons for large size da tasets Segmen t M 1000 Err. 11 . 3 9 Std 0 . 75 1500 Err. 14 . 7 2 Std 0 . 803 25 T able 11: GCV results at fixed n umber of hidden neurons for medium s ize datasets. F or Delta Ailer o ns, av er age er r ors and standard deviations ha ve to b e multiplied b y 10 − 4 . Abalone Housing Delta Ailerons D ia b etes M 50 Err. 2 . 13 4 . 89 1 . 60 25 . 2 Std 0 . 017 0 . 45 0 . 0103 1 . 22 100 Err. 2 . 15 5 . 05 1 . 63 26 . 66 Std 0 . 021 0 . 70 0 . 0297 1 . 39 200 Err. 2 . 32 6 . 78 1 . 74 27 . 73 Std 0 . 10 2 . 35 0 . 0892 1 . 27 300 Err. 2 . 98 8 . 07 2 . 20 27 . 14 Std 0 . 42 2 . 89 0 . 4054 1 . 15 γ K = 1 p p X 1 ˆ σ 2 ˆ α 2 i , (30) γ H K = ˆ σ 2 ˆ α 2 max . (31) Our exp erimen tation is made o nly fo r regression data sets b ecause the theoretical back gro und of (Dorugade and Kashid, 2 0 10), a nd of most of other w orks referred in section 2, directly applies to the case in whic h the quan tity Y in eq.(1) is a one column matrix. In our form ulation Y is the desired targ et T and it is a one-column matrix only for regression tasks. F o r eac h dataset w e a pplied b ot h metho ds described b y eq. 30 and 31; w e select the same fixed n um b ers of hidden units as in section 5 .1 and p erform 50 experimen ts with different configuration of input w eigh ts. Eac h step of pseudoin v ersion is regularized for each metho d with the corresp onding γ v alue. W e ev aluate the mean and standard deviation of the regularized test errors, r ep orted respective ly in T ables 12 and 13. Whenev er the methods pro vide test error v alues statistically better than OCReP (listed in T ab. 2 and 4), they are mark ed in b old. W e remark that the metho d by Kibria obtains a b etter p erformance in t w o cases ov er sixte en, while OCReP in 12 cases o v er sixteen. Besides, the metho d b y Ho erl and Kennard o btains a b etter p erformance in three cases 26 T able 12: Kibria estimate o f ridge parameter : res ults at fixed num b er o f hidden neuro ns for regr ession datasets. F or Delta Ailerons, average errors and s tandard deviations hav e to b e m ultiplied b y 1 0 − 4 . Abalone Housing Delta Ailerons Mac hine Cpu M 50 Err. 2 . 32 5 . 72 1 . 63 34 . 28 Std 0 . 37 0 . 84 0 . 027 4 . 67 100 Err. 2 . 38 5 . 45 1 . 64 32 . 40 Std 0 . 90 0 . 86 0 . 08 3 . 72 200 Err. 2 . 20 5 . 31 1 . 65 Std 0 . 13 0 . 76 0 . 15 300 Err. 2 . 34 5 . 46 1 . 62 Std 1 . 01 1 . 60 0 . 035 o v er sixteen, while OCReP in eight cases o v er sixteen. F or b oth metho ds, b etter p erformance is ac hiev ed only for the case of M = 50 neurons. It ma y b e noted that with resp ect to pro cessing requiremen ts OCReP has clear adv a n tages, since it requires only a SVD step for eac h determination of γ , while the ab ov e t w o metho ds require full spectral decomp o sition and an additional matrix in v ersion. 6.2. Alternative r e gularization metho ds A first comparison can b e done with the w ork b y Huang et al. (Huang et al. , 2012), whose tec hnique Extreme Learning Machine (ELM) uses a cost param- eter C that can b e considered as related to the in v erse o f our r egularization parameter γ . As a uthors state, in order to a chiev e g o o d generalization per- formance, C needs to b e c hosen appropriately . They do this b y tr ying 50 differen t v alues of this parameter: [2 − 24 , 2 − 23 , · · · 2 24 , 2 25 ]. A fair comparison can b e done on our classific atio n datasets, using their n um b er of hidden neurons, i.e. 1000. Our optimal choice o f γ allo ws to obta in a b etter p erfor ma nce on all datasets (with statistical significance assessed at the same confidence lev el that previous exp eriments). Deng et a l. (Deng et al. , 2009) propo se a Regularized Extreme Learning Mac hine (hereafter, RELM) in wic h the regularization parameter is se lected according t o a similar criterion a mong 100 v alues: [2 − 50 , 2 − 49 , · · · 2 50 ]. Be- cause their perfo rmance is optimized with resp ect to the n um b er o f hidden 27 T able 13: H-K estimate of ridge parameter: results at fixed num b er of hidden neuro ns for regres s ion datasets. F o r Delta Ailero ns, av era ge error s and standar d devia tions hav e to b e m ultiplied b y 10 − 4 . Abalone Housing Delta Ailerons Mac hine Cpu M 50 Err. 2 . 13 4 . 87 1 . 60 34 . 28 Std 0 . 016 0 . 44 0 . 01 2 . 37 100 Err. 2 . 14 4 . 98 1 . 62 37 . 39 Std 0 . 90 0 . 67 0 . 029 3 . 18 200 Err. 2 . 33 8 . 101 1 . 73 Std 0 . 10 2 . 83 0 . 08 300 Err. 2 . 95 29 . 06 2 . 21 Std 0 . 41 9 . 26 0 . 41 T able 14 : Comparison b etw een OCReP and E L M Iris Wine D iab etes Segment OCReP Err. 2 . 22 1 . 28 21 . 06 3 . 40 Std. 0 . 21 0 . 88 0 . 65 0 . 25 ELM Err. 2 . 4 1 . 53 22 . 05 3 . 9 3 Std 2 . 29 1 . 81 2 . 18 0 . 69 neurons, for the sak e of comparison w e use OCReP v alues fro m table 6. W e obtain a statistically significan t b etter p erformance on dataset Segmen t, while for Diab etes the metho d RELM p erforms better (see table 15). Comparing our results on the common regress ion dat a sets with the alter- nativ e metho d TROP-ELM prop osed b y Mic he et al. ( Mic he et al. , 201 1), w e note that OCReP achiev es alw ay s lo w er RMSE v alues 3 (with statistical significance), as can b e se en from table 16. Besides, in our opinion o ur method is sim pler, in the sense that it uses a single step of regularization rather than t w o. In (Martinez-Martinez et al. , 2011), an algorithm is prop o sed for pruning 3 In that work, perfor mance a nd related statistics are expressed in terms of MSE; we only derived the corresp onding RMSE for compariso n with our results. 28 T able 15 : Comparison b etw een OCReP and REL M Diab etes Segme nt OCReP Err. 25 . 53 2 . 50 Std. 0 . 51 0 . 32 ¯ M 291 760 RELM Err. 21 . 81 4 . 49 Std. 2 . 55 0 . 0074 ¯ M 15 200 T able 1 6: Compariso n between OCReP and TROP-ELM. F or Delta Ailerons, average error s and standard deviatio ns hav e to be m ultiplied b y 10 − 4 . Abalone Delta Ailerons Mac hine Cpu Housing OCReP Err. 2 . 12 1 . 58 31 . 22 4 . 25 Std. 0 . 32 0 . 0048 0 . 78 0 . 13 ¯ M 178 298 63 255 TR OP-ELM Err. 2 . 19 1 . 64 264 . 03 34 . 35 ¯ M 42 80 28 59 ELM netw o rks b y using regularized regression metho ds: the crucial step of regularization parameter determination is solv ed b y creating K differen t mo dels, eac h one based on a diff erent v alue of this parameter, among which the b est one is selecte d using a Bay esian information criterion. Authors state that a t ypical v alue for K is 100, th us an hea vy computational load is required, and the metho d is fo cused on regression tasks. 7. Conclusions In the con text of regularization tec hniques f or single hidden la ye r neural net w orks trained b y pseudoin ve rsion, w e pro vide a n optimal v a lue of the reg- ularization parameter γ by analytic deriv ation. This is ac hiev ed b y defining a con v enien t regularized mat r icial form ulation in the framew ork of Singular V alue Decomp osition, in whic h the regularization parameter is derive d un- der the constraint of condition n um b er minimization. The OCReP metho d 29 has b een tested on UCI data sets f or b oth regression and classification tasks. F o r all cases, regularizatio n implemen ted using the analytically derive d γ is pro v en to b e v ery effectiv e in terms of predictivit y , as evidence d b y compari- son with implemen tations of other approac hes from the literature, includin g cross-v alidat io n. OCReP av oids hun dreds of pseudoin v ersions usually needed b y most other me tho ds, i.e. it is quite computationally attractive . Ac knowled gemen ts The activit y has b een partially carried on in the con text of the Visiting Professor Program of the G rupp o Nazionale p er il Calcolo Scien tifico (GNCS) of the Italian Istituto Nazionale di Alta Matematica (INdAM). This w ork has b een partially supp o rted by ASI contracts (Gaia Mission - The Italian P articipation to DP AC ) I/058/ 10/0-1 and 20 14-025- R.0. References Ajorlo o, H., Manzuri-Shalmani, M. T., and L akdash ti, A. (2007) . Restoration of damag ed slices in images using matrix pse udo in v ersion. In Pr o c e e dings of the 22 nd I nternational symp osium on c omputer and i n formation sci- enc es , pag es 1–6. Bac he, K. and Lic hman, M. (20 1 3). UCI mac hine learning rep ository . Badev a, V. and Morozov , V. (1991). Pr obl` emes inc orr e ctement p os´ es: Th´ eorie et applic ations en ide n tific ation , filtr age o p timal, c ontrˆ ole op- timal, analyse et synth ` es e de syst` emes, r e c onnai s s anc e d’image s . S´ erie Automatique. Masson. Berger, J. (1976). Minimax estimation of a m ultiv a riate normal mean under arbitrary quadratic loss. J. Multivariate Analysis , 6 , 256–264 . Bishop, C. M. (2006). Pattern R e c o gnition a nd Machine L e arning (Informa- tion Scienc e and Statistics) . Springer-V erlag New Y o r k, Inc., Secaucus, NJ, USA. Bousquet, O. a nd Eliss eeff, A. (2002 ). Stabilit y and g eneralization. J. Mach . L e arn. R es. , 2 , 49 9 –526. 30 Cancelliere, R. (2001). A high parallel pro cedure t o initialize the output w eigh ts of a ra dia l basis function or bp neural net w ork. In Pr o c e e d i ngs of the 5th International Workshop on Applie d Par al lel Computing, New Par adigms for HPC in Industry and A c ademia , P ARA ’00, pages 384–390, London, UK, UK. Springer-V erlag. Deng, W., Zheng, Q., and Chen, L. ( 2 009). Regula r ised extreme learning mac hine. In Pr o c e e dings of the IEEE Symp osium on Computational Intel- ligenc e and Data Mining . Devro y e, L. P . and W ag ner, T. (19 79). Distribution-free p erformance b ounds for p oten tial function rules. Information The ory, IEEE T r ansactions o n , 25 (5), 601–604. Dorugade, A. and Ka shid, D . (2010). Alternativ e metho d fo r c ho osing ridge parameter for regress ion. Applie d Mathematic al Scienc es , 4 , 44 7–456. F u, W. (1998 ). P enalized regressions: the bridge vs. the lasso. Journal of Computational and Gr ap h ic al Statistics , 7 , 397– 416. F uhry , M. and Reiche l, L. ( 2 012). A new t ikhonov regularization metho d. Numeric al Algorithms , 59 (3), 433–445. Gallinari, P . and Cibas, T. (1 999). Practical complexit y con trol in m ultila ye r p erceptrons. Signal Pr o c essing , 74 , 29 –46. Geman, S., Bienensto c k, E., and Doursat, R. (199 2 ). Neural netw orks and the bias/v ariance dilemma. Neur al Computation , 4 , 1–58. Girosi, F., Jo nes, M., and Poggio, T. (1 995). Regularization Theory and Neural Net w orks Arc hitectures. Neur a l Com putation , 7 , 219–269. Golub, G., heath, M., a nd W ah ba, G . (1979). Generalized cross-v alida t ion as a metho d for c ho osing a go o d ridge parameter. T e chno m etrics , 21 , 215–223. Golub, G. H. a nd V an Loan, C. F. (19 96). Matrix c omputations (3r d e d.) . Johns Hopkins Univ ersity Press, Baltimore, MD, USA. Golub, G. H., Hansen, P . C., and O’Leary , D. P . (1999). Tikhono v regu- larization and to t a l least squares. SIAM J. Matrix Anal. Appl. , 21 (1), 185–194. 31 Hastie, T., Tibshirani, R., and F riedman, J. (2009). The elements of Statisti- c al L e arni n g: Data Mining , Infer enc e, and Pr e diction (2r d e d.) . Springer. Ha ykin, S. (1 999). Neur al Networks: A Compr ehensive F oundation . Inte r- national edition. Pren tice Hall. Helm y , T. and Rasheed, Z. (200 9). Multi-category bioinformatics dataset classification using extreme learning m achine. In Pr o c e e dings of the Eleventh c onfer enc e o n Congr ess on Evolutionary Computation , CEC’09, pages 3234–3240, Pisc at aw a y , NJ, USA. IEEE Press. Ho erl, A. (1962). Application of ridg e analysis to regression problems. Chem- ic al Engine ering Pr o gr ess , 58 , 54–59. Ho erl, A. and Kennard, R. (1970). Ridge regression: Biased estimation for nonorthogonal problems. T e chnometrics , 12 , 55–67 . Ho erl, A. and Kennard, R. (1976). Ridge regression: iterative estimation of the biasing parameter. Comm unic ations in Statistics , A5 , 77–8 8. Huang, G.-B., Zh u, Q.-Y., a nd Siew, C.-K. (2006). Extreme learning ma- c hine: theory and applications. Neur o c omputing , 70 (1), 489–501. Huang, G.-B., Zh u, Q.-Y., and Siew, C.-K. (2012). Extreme learning mac hine for regression and m ulticlass classification. IEEE T r a nsactions on Systems, Man, and Cyb erne tics– Part B: Cyb ernetics , 42 (2), 513–529. Kearns, M. and Ron, D. (1999). Algorithmic s tability and sanit y-c hec k b ounds for leav e-o ne-out cross-v alidation. Neur al Com p utation , 11 (6 ), 1427–145 3. Khalaf, G. and Sh ukur, G. (20 05). Cho osing ridge pa rameter for regression problem. Communic ations in Statistics – The ory an d metho ds , 34 , 1177– 1182. Kibria, B. (2 0 03). P erformance of some new r idge regression estimators. Communic ations in Statistics – Simulation and Computation , 32 , 419– 435. Kohno, K., Ka w amoto, M., and Inouy e, Y. (2 010). A matrix pseudoin v ersion lemma and its application to blo ck -ba sed adaptive blind decon v olution for mimo syste ms. T r ans. Cir. Sys. Part I , 57 (7), 1449–1462. 32 La wless, J. and W ang, P . (19 7 6). A sim ulation study of ridge and other regression estimators. Communic ations in Statistics , A5 , 307–324 . Mardiky an, S. and Cetin, E. (2008). Efficien t ch oice of biasing constan t for ridg e regression. Internation a l Journal of Con temp or ary Mathematic al Scienc es , 3 , 52 7–547. Martinez-Martinez, J., Escandell-Mon tero, P ., Soria-Oliv as, E., Martn- Guerrero, J., Magdalena-Benedito, R ., and Juan, G.- S. (2011) . Regula r ized extreme learning mac hine f or regression problems. Neur o c omputing , 74 , 3716–372 1. McDonald, G. and Galarneau, D. (1975). A mon te carlo ev alua tion of some ridge-t yp e estimators. J. A mer. Statist. Asso c. , 70 , 40 7–416. Mic he, Y., v an Heeswijk, M., Bas, P ., Sim ula, O., and Lendasse, A. (2011) . T rop-elm: A double-regularized elm using la rs and tikhonov regularization. Neur o c omputing , 74 (16), 2413 – 24 21. Mukherjee, S., Niy ogi, P ., Poggio, T., and Rifkin, R. (2003). Statistical learning: stability is sufficien t for generalization and necessary and suffi- cien t fo r consistency of empirical risk minimization. CBCL, Pap er 2 2 3 , Massachusetts I n stitute of T e chno lo gy . Mukherjee, S., Niy ogi, P ., P oggio , T., and Rifkin, R. (2006 ). Learning theory: stabilit y is sufficien t for generalization a nd necessary and sufficien t fo r consistency of empirical risk minimization. A dv anc es in Computational Mathematics , 25 (1-3), 161–193. Nguy en, T. D., Pham, H. T. B., and Dang, V. H. (2010). An efficien t pseudo in v erse matrix-based solution f or secure auditing. In Pr o c e e dings of the IEEE International Confer e n c e on Computing and Communic ation T e ch- nolo gies, R ese ar ch, In novation, and Visio n for the F utur e , IEEE In terna- tional Conference. Nordb erg, L. (1982). A pro cedure fo r determination of a go o d ridge param- eter in line ar regression. Communic ations in Statistics , A11 , 285–309. P enrose, R. and T o dd, J. A. ( 1956). On b est approximate solutions of linear matrix equations. Mathematic al Pr o c e e dings of the Cambridge Philosoph- ic al So ciety , n ull , 17–19. 33 P oggio, T. and Giro si, F . (1990a). Net w orks for appro ximation and learning. Pr o c e e dings of the IEEE , 78 (9), 1481–1497. P oggio, T. a nd Girosi, F. (1990b) . Regularization algorithms for learning that are eq uiv alen t to m ultilay er net w orks. S cienc e , 247 (4945), 978–982. P oggio, T., Rifkin, R., Mukhe rjee, S., and Niy ogi, P . (2004). General condi- tions for predic tivity in learning t heory . L etters to Natur e , 428 , 419/422. Rao, C. a nd Mitra, S. (1971 ). Gener alize d inverse o f matric es and its appli- c ations . Wiley series in probability and mathematical statistics: Applied probabilit y and statistics. Wiley . Saleh, A. and Kibria, B. (1993). Performances of some new preliminary test ridge r egr ession estimators and their properties. Communic ations in Statistics – The ory and metho ds , 22 , 2747–2764. Tibshirani, R . (1996). Regression shrink age and selection via the lasso. Jour- nal o f R oyal Statistic al So ciety , 58 , 267 –288. Tikhono v, A. and Arsenin, V. (1 9 77). S o lutions of il l-p o se d pr oblems . Scripta series in ma t hematics. Winston, W ashington DC. Tikhono v, A. N. (1963). Solution of incorrectly fo rm ulated problems and the regularization metho d. Soviet Math. Dokl. , 4 , 1035–1038. W ang, X. (2013) . Special issue on extreme learning mac hines with uncer- tain ty . Int. J. Unc. F uzz. Know l. Base d Syst. , 21 . W ang, X.-Z., D., W., and Huang, G .-B. (2012). Special issue on extreme learning mac hines. Sof t C omputing , 16 (9), 1461–1463. Y u, D. and Deng, L. ( 2012). Effi cien t and effectiv e algorithms f o r training single-hidden-la y er neural net w orks. Pattern R e c o gn. L ett. , 33 (5), 554–55 8 . 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment