Extended Dynamic Generalized Linear Models: the two-parameter exponential family
We develop a Bayesian framework for estimation and prediction of dynamic models for observations from the two-parameter exponential family. Different link functions are introduced to model both the mean and the precision in the exponential family all…
Authors: Mariana Albi de Oliveira Souza, Helio dos Santos Migon
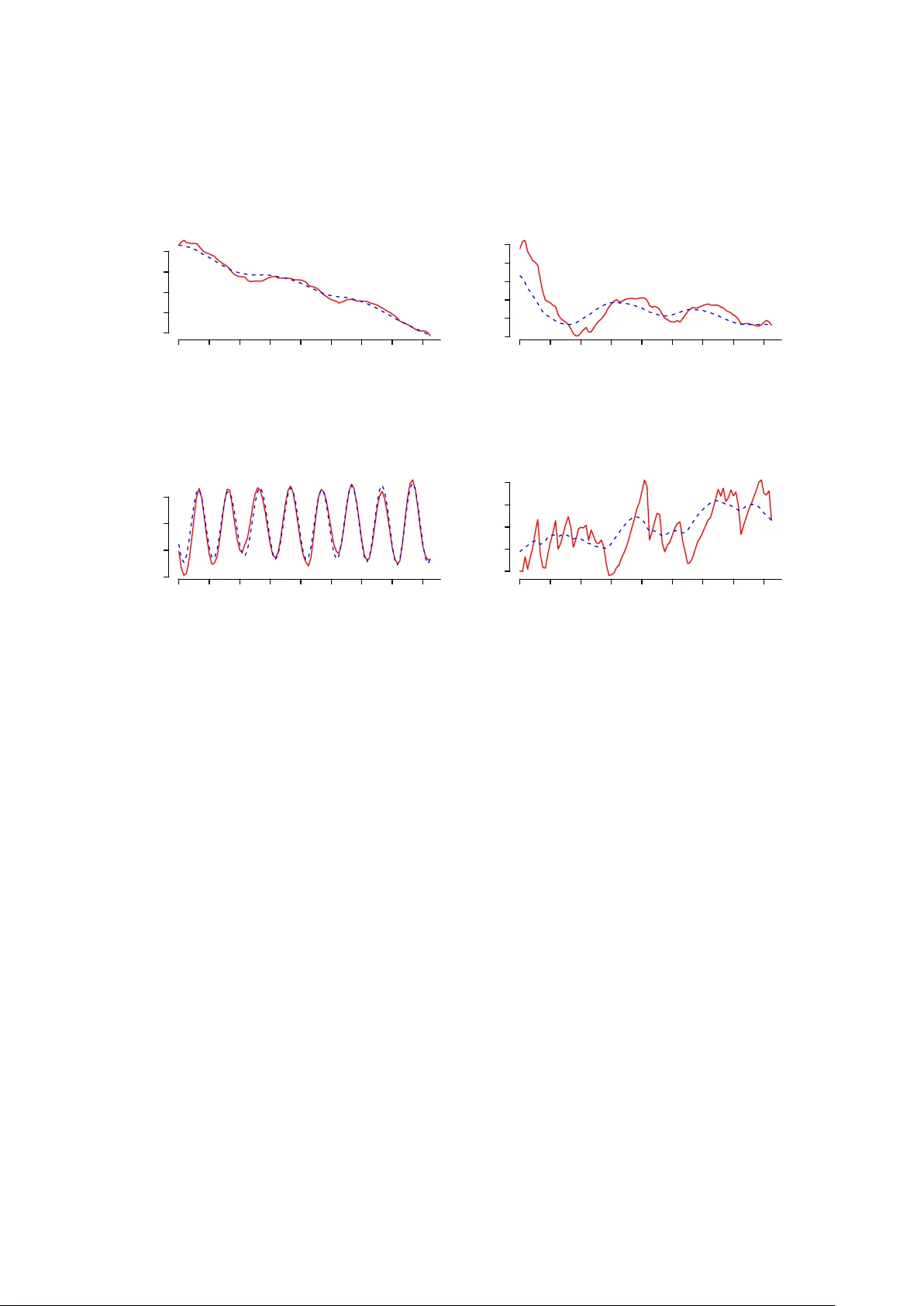
Extended Dynamic Generalized Linear Mo dels: the t w o-parameter exp onen tial family MARIANA A. O. SOUZA ∗ Univ ersidade F ederal Fluminense HELIO S. MIGON † Univ ersidade F ederal Rio de Janeiro Septem b er 26, 2018 Abstract W e dev elop a Bay esian framew ork for estimation and prediction of dynamic models for observ ations from the tw o-parameter exp onen tial family . Differen t link functions are introduced to model b oth the mean and the precision in the exponential family allo wing the introduction of cov ariates and time series comp onen ts. W e explore conjugacy and analytical approximations under the class of partial sp ecified mo dels to k eep the computation fast. The algorithm of W est et al. (1985) is extended to cope with the t w o- parameter exp onential family mo dels. The methodological no velties are illustrated with tw o applications to real data. The first, considers unemploymen t rates in Brazil and the second some macro economic v ariables for the United Kingdom. 1 In tro duction Generalized linear mo dels (GLMs) ha ve b ecome a standard class of mo dels in the data analyst’s to olbox. Prop osed b y Nelder and W edderburn (1972), GLMs are widely used in man y areas of knowledge. They allo w mo delling data of man y different natures via the probabilistic description as an element of the exp onen tial family and relating the resp onse mean and the linear predictor in a non-linear form. The ∗ A ddr ess for c orr esp ondenc e : Mariana Albi O. Souza, Departamento de Estat ´ ıstica, Instituto de Matem´ atica e Estat ´ ıstica, Universidade F ederal Fluminense, Rua Mario Santos Braga s/n, 7o. andar, Centro, Niter´ oi, RJ, Brazil. CEP 24020-140. E-mail : mariana@im.uff.br. † E-mail : migon@im.ufrj.br. 1 GLM class is a useful alternative for data analysis since it accommodates sk ewness and heterosk edasticit y , b esides allowing analysis using the data in their original scale. The ev olution of these mo dels as w ell as details regarding inference, fitting, mo del c hecking, etc., is documented in the seminal bo ok of McCullagh and Nelder (1989) and many others in the recent literature. The main criticism of the use of the one-parameter exp onential family in certain applications is that samples are often found to b e to o heterogeneous to b e explained by a one-parameter family of mo dels in the sense that the implicit mean-v ariance relationship in such a family is not supp orted by the data. T o ov ercome this limitation Gelfand and Dalal (1990) and Dey et al. (1997) introduced the class of tw o- parameter exp onen tial family , which includes the ones presented by Efron (1986) and Lindsay (1986) as sp ecial cases. They argue that the introduction of a second parameter allows taking into accoun t the o ver-dispersion usually present in the data, an issue that has b een recognized by data analysts for man y y ears. During the 1990s, special attention was devoted to mo delling the mean and the v ariance sim ultaneously . T aguc hi t yp e metho ds led to some efforts to jointly mo del the mean and the disp ersion from designed experiments, av oiding the data transformation that is usually necessary to satisfy the assumptions of traditional linear mo dels Nelder and Lee (2001). The pro cess of quality improv emen t aims to minimize the pro duct v ariation caused b y different t yp es of noise. Qualit y impro vemen t must b e implemented in the design stage via exp erimen ts to assess the sensitivity of different control factors that affect the v ariabilit y and mean of the pro cess. Nelder and Lee (2001) discussed how the main ideas of a GLM can b e extended to analyse T aguchi’s exp erimen ts. F rom a static p oin t of view, the Bay esian inference for this class of mo dels is fully discussed in the pap ers previously cited, while some alternative asp ects of MCMC are discussed in Cep eda and Gamerman (2005) and Cep eda et al. (2011). Our aim in this article is to extend the class of mo dels introduced by Gelfand and Dalal (1990) and Dey et al. (1997) to deal with time series data and to prop ose a fast algorithm for estimation and prediction of this class of mo dels. T o reach this ob jective we prop ose an algorithm based on analytical appro ximations, for example, based on Laplace approximations. This w a y we are extending the conjugate up dating metho d prop osed in W est et al. (1985). The remainder of the manuscript is organized as follows. Section 2 introduces the class of mo dels w e are fo cused on. In Section 3 the conjugate up dating of W est et al. (1985) is extended to the tw o- parameter exp onential family . Section 4 illustrates the prop osed metho d with tw o case studies: the first one mo dels unemplo yment rates in Brazil and the second one mo dels some data on the UK econom y as b eta distributed data. Section 5 concludes with a discussion and p ossible future research directions. 2 2 Extended Dynamic Generalized Linear Mo dels In this section we in tro duced the class of extended dynamic generalized linear mo dels (EDGLM). First we briefly revise the tw o-parameter exp onen tial family and the dynamic generalized linear mo dels, mainly aiming to fix the notation to b e used in this pap er. A special parametrization of the t w o- parameter exponential family is presented in this section. It is very useful to deal with data analysis when heterogeneit y in the sample is greater than that explained by the v ariance function in the one- parameter exp onen tial family . The distributions in this family are often used in many applications in the curren t literature, not only to deal with the topic of extra v ariability . The tw o-parameter exp onen tial family has the form p ( y | θ, φ ) = a ( y ) exp { φ [ θ d 1 ( y ) + d 2 ( y )] − ρ ( θ , φ ) } , y ∈ Υ ⊂ I R (1) where a ( · ) is a non-negative function, d 1 ( · ) and d 2 ( · ) are kno wn real functions, ( θ , φ ) ∈ Θ × Φ ⊆ I R × I R + and exp {− ρ ( θ , φ ) } = Z a ( y ) exp { φ [ θ d 1 ( y ) + d 2 ( y )] } dy < ∞ . This is a suitable reparameterization of the general tw o-parameter exp onen tial family as defined in Bernardo and Smith (1994). This class includes man y con tinuous distributions, suc h as the normal with unknown mean and v ariance, the in verse Gaussian and the beta distributions, parameterized by its mean and precision factor. The expression for the v ariances, as we will see in section 3.3, make clear the relev ance of the precision parameter, φ , to control the mo del v ariance. Large v alues of φ corresp onds to more precise data or equiv alently with smaller v ariance. Some discrete distributions are also included in this class, such as the binomial (with the sample size known) and Poisson distributions, taking the scale parameter as fixed and equal to one. Among other interesting features of this class of distributions, we stress the existence of a joint prior distribution for the parameters ( θ , φ ) in the form p ( θ , φ | τ ) = κ ( τ ) exp { φ [ θ τ 1 + τ 2 ] − τ 0 ρ ( θ , φ ) } , where τ = ( τ 0 , τ 1 , τ 2 ) 0 and κ ( τ ) − 1 = Z Z exp { φ [ θ τ 1 + τ 2 ] − τ 0 ρ ( θ , φ ) } dθ dφ . Let ψ = ( θ , φ ) ∈ Ψ = Θ × Φ , to make the notation easier. Its prior mo de and observed curv ature matrix can be straigh tforwardly obtained differentiating the expression ab o ve with resp ect to the parameters vector ψ . More sp ecifically , the mo de and curv ature matrix satisfy the equations ˜ ψ = arg max ψ ∂ ∂ ψ log( p ( ψ | τ )) and J ( ψ ) = − ∂ 2 ∂ ψ 0 ∂ ψ log( p ( ψ | τ )) . Then it follows, after some algebra, that φτ 1 − τ 0 ∂ ∂ θ ρ ( ψ ) θ τ 1 + τ 2 − τ 0 ∂ ∂ φ ρ ( ψ ) = 0 0 and J ( ψ ) = − τ 0 t ∂ 2 ∂ θ 2 ρ ( ψ ) τ 1 − τ 0 ∂ 2 ∂ θ ∂ φ ρ ( ψ ) τ 1 − τ 0 ∂ 2 ∂ θ ∂ φ ρ ( ψ ) − τ 0 ∂ 2 ∂ φ 2 ρ ( ψ ) . 3 The predictive distribution is also defined in closed form, as p ( y | τ ) = a ( y ) κ ( τ ) κ ( τ ∗ ) , y ∈ Υ , where τ ∗ = ( τ 0 + 1 , τ 1 + d 1 ( y ) , τ 2 + d 2 ( y )) 0 . (2) No w that the basic notation is clearly stated, we can progress to the dynamic version of the extended generalized linear mo del. Let y 1 , · · · , y T b e conditionally indep endent observ ations from the tw o- parameter exp onential family and for each t ∈ { 1 , ..., T } , denote E [ y t | ψ t ] = µ t . Let us supp ose that b oth the mean µ t and the precision φ t can be describ ed b y explanatory v ariables through p ossibly differen t non-linear link functions, denoted by g 1 and g 2 . Therefore, giv en the prior moments of the laten t states β t , the class of mo dels to be considered in this pap er is describ ed by three comp onen ts. The first is a conditional conjugate model describing observ ations in the tw o-parameter exp onential family with its prior distribution: y t | ψ t ∼ E f ( y t | ψ t ) and ψ t | D t − 1 ∼ C E f ( τ t ) , ∀ t = 1 , · · · , T , (3) where E f ( y t | ψ t ) denotes a distribution in the t wo-parameter exponential family (1), C E f ( τ t ) represents its conjugate prior distribution and D t − 1 denotes all the information av ailable up to time t − 1. A general link function is introduced to relate the linear predictors with the mean and precision of the observ ational distribution ev aluated as functions of ψ : η t = g ( ψ t ) = F 0 t β t and β t = G t β t − 1 + ω t , ω t ∼ [ 0 , W t ] , (4) with g : I R × I R + → I R 2 , g ( ψ t ) = ( g 1 ( µ t ) , g 2 ( φ t )), F t is a p × 2 matrix, where p = p 1 + p 2 , with p i = dim β ti and β ti = ( β ti 1 , · · · , β tip i ) 0 , i = 1 , 2, the latent v ariables vector related to µ t and φ t . Dep ending on the sp ecification of F t a broad class of mo dels can be entertained. If F t = diag( F t 1 , F 2 t ), different time series comp onen ts and cov ariates are used to describe the time ev olution of µ t and φ t through the link functions. Of course, they can also share some common regressors. The state parameters’ evolution is describ ed b y a partially sp ecified distribution, with ω t ∼ [ 0 , W t ], where [ a, b ] denotes a distribution sp ecified just b y its first and second moments. The state parameters’ initial information, β 0 | D 0 ∼ [ m 0 , C 0 ], is also partially sp ecified with prior momen ts m 0 and C 0 . Therefore equations in (3) and (4), together with the state parameters’ initial information, define a class of partially sp ecified mo dels, where only the first and second prior moments are defined for the v ector of latent comp onen ts. 4 3 Inference in EDGLM The class of mo dels describ ed by (3) and 4) extends the mo dels treated in W est et al. (1985) not only allo wing the scale parameter to v ary in time, but also mo delling it through an additional link function. This extension implies that the original algorithm is not immediately applicable. The conjugate updating algorithm of W est et al. (1985) is extended, making estimation in this class of mo dels feasible. The estimation is still based in the conjugate distribution and linear Ba yes estimation, up dating sequentially the state vector distributions at each time t , as in the original algorithm. At the end of this pro cess, we obtain b oth the first and second p osterior momen ts of laten t states vectors and the p osterior distribution of ( ψ t | D t ) for each instant t . In the next subsections, we review the main steps in v olved in the conjugate up dating algorithm mainly to set up the notation, and prop ose a strategy to reduce the system dimension. W e also discuss the forecasting distribution and conclude with some examples. 3.1 Extended Conjugate Up dating The conjugate up dating algorithm is based on the steps: ev olution, moments equating and up dating. The ev olution step in volv es obtaining the first and second moments of the state v ectors prior distribution, a t := E [ β t | D t − 1 ] = G t m t − 1 and R t := V ar ( β t | D t − 1 ) = G t C t − 1 G 0 t + W t , giv en the p osterior mean and v ariance at time t − 1, m t − 1 , C t − 1 and the state evolution v ariance W t . The prior momen ts for the linear predictors follow immediately as: f t := E [ η t | D t − 1 ] = F 0 t a t and Q t := V ar ( η t | D t − 1 ) = F 0 t R t F t . Alternativ ely , the prior moments of the linear predictor, η t = g ( ψ t ), can b e obtained as functions of parameters defining the conjugate prior. Denote these prior momen ts as: E [ η t | D t − 1 ] = h ( τ t ) and V ar ( η t | D t − 1 ) = H ( τ t ), where h : I R 3 → I R 2 , H : I R 3 → M and M is a set of symmetric p ositiv e definite 2 × 2 matrices and τ = ( τ 0 , τ 1 , τ 2 ) 0 is the parameters vector of the conjugate prior. W e are facing a similar problem to the one p osed by Poole and Raftery (2000) in the con text of computer simulation mo dels. There are tw o prior on the same quantit y but based on differen t sources of information. This also o ccurs in the context of reaching consensus in the presence of multiple exp ert opinions. The analytic expressions of the abov e moments need to b e equated to the linear predictors’ n umerical momen ts, previously obtained as functions of the prior moments of the states, providing the non-linear system of equations: h ( τ t ) = f t and v ec( H ( τ t )) = v ec( Q t ) . (5) where vec( M ) denotes the vectorization of the upp er triangular matrix of a symmetric M . Note that the dimension of the inv olved vectors and matrices leads to a non-linear system with more equations than unknown quantities, so the system (5) do es not provide a unique solution for the parameter 5 v ector τ t . Therefore it is necessary to in tro duce some criterion to reduce this large set of solutions to one compromise solution. A prop osal to deal with this sort of dimension incompatibilit y in system (5) is treated in Section 3.2. This aims to answer the follo wing query: What is the “b est conjugate prior distribution” corresp onding to the partially sp ecified predictive distribution with mean f t and v ariance Q t ? After observing a new datum, the prior parameters are straigh tforwardly updated. It follows from conjugacy that τ t can b e up dated according to expressions in (2), giving a new parameter vector τ ∗ t . The linear predictors’ p osterior momen ts can b e obtained analogously to the system equations (5), given f ∗ t = h ( τ ∗ t ) and Q ∗ t = H ( τ ∗ t ), or analogously , vec( Q ∗ t ) = v ec( H ( τ ∗ t )). The observ ed information is propagated to the state vector using linear Ba yes estimation (W est and Harrison (1997), Chapter 4), since its distribution is only partially sp ecified. Then, w e obtain the p osterior moments of β t , m t = E [ β t | D t ] = a t + R t F t Q t − 1 ( f ∗ t − f t ) and C t = V ar ( β t | D t ) = R t + R t F t Q − 1 t [ Q ∗ t − Q t ] Q − 1 t F 0 t R t . The smo othed posterior moments of the latent states can b e obtained in the same wa y as m t and C t , using linear Bay es estimation, as detailed in Souza (2013), resulting to expressions, m s t = E [ β t | D T ] = m t + C t G 0 t +1 R − 1 t +1 ( m s t +1 − a t +1 ) and C s t = V ar ( β t | D T ) = C t + C t G 0 t +1 R − 1 t +1 ( C s t +1 − R t +1 ) R − 1 t +1 G t +1 C t , where m s T := m T and C s T := C T . 3.2 Dimensionalit y Reduction T o ensure the uniqueness of the vector τ t at each time considered in the algorithm, we need to reduce the dimensionality of the system (5). Several p ossibilities can b e explored for this reduction, including arbitrary solutions suc h as ignoring some equations of the system (5). T o a void suc h arbitrariness we prop ose an alternative inspired on the generalized method of momen ts (Yin (2009)). Our main ob jectiv e is to match the linear predictors’ momen ts and the conjugate prior momen ts preserving as muc h information pro vided b y the system as possible. An optimum solution is obtained by minimizing the quadratic distance b et ween the functional form that represents the difference b et w een the numerical moments and the moment conditions describ ed by its parameter vector, weigh ted by a weigh ts matrix Ω k (where k is the dimension of the system) and zero. So, an optimum choice for the parameter vector τ t is the one that minimizes the function ∆ k ( τ t ; f t , Q t ) 0 Ω k ∆ k ( τ t ; f t , Q t ) , (6) where ∆ k ( τ t ; f t , Q t ) = ( f t − h ( τ t ) , vec( Q t ) − v ec( H ( τ t )) ) is a vectorial function and Ω k a p ositiv e definite weigh t matrix that sp ecifies the imp ortance of each equation condition in the estimation pro cess. Actually , since the weigh t matrix Ω k determines how eac h condition is weigh ted in the system solution, a simple choice is to take Ω k = I k (iden tity matrix of dimension k ), which corresp onds to considering all 6 the equations in system (5) on equal footing. Of course other choices for the matrix Ω k can be considered. In tuitively , the more accurate equations should b e weigh ted more than the less accurate ones. A t wo-stage iterativ e pro cedure, describ ed in Yin (2009), can b e implemented to determine the “optimal” Ω k taking in to account the observed data. In summary , the prop osed pro cedure can b e implemen ted following the algorithm b elo w: Extended Conjugate Up dating Algorithm: A t each time t Step 1. ev olution: giv en m t − 1 and C t − 1 , a t = G t m t − 1 and R t G t C t − 1 G 0 t + W t f t = F 0 t a t and Q t = F 0 t R t F t . Step 2. prior momen t equating: obtain the prior parameter v ector τ t , solution of arg min τ t { ∆ k ( τ t ; f t , Q t ) 0 Ω k ∆ k ( τ t ; f t , Q t ) } . Step 3. p osterior momen ts updating and equating: obtain τ ∗ t using equation (2) and calculate f ∗ t and Q ∗ t using τ ∗ t in equations (5). Step 4. state up dating: obtain ( m t , C t ) via Linear Ba yes estimation taking m t = a t + R t F t Q t − 1 ( f ∗ t − f t ) and C t = R t + R t F t Q − 1 t [ Q ∗ t − Q t ] Q − 1 t F 0 t R t . 3.3 Some Illustrativ e Examples In this section we present examples inv olving the normal, the inv erse Gaussian and the gamma distribution, leaving the discussion of the beta model to the next section. Our aim is to show the main functions inv olved in the E f definition and their constraints. 3.3.1 Normal distribution with unkno wn mean and precision Consider mo del (3), where p ( y t | µ t , φ t ) represen ts the density function of normal distribution with mean µ t = θ t and v ariance φ − 1 t . In this case, d 1 ( y t ) = y t , d 2 ( y t ) = − y 2 t 2 and ρ ( θ t , φ t ) = 1 2 µ 2 t φ t − log( φ t ) , and the conjugate prior distribution takes the form p ( µ t , φ t | D t − 1 ) ∝ exp { φ t [ µ t τ 1 t + τ 2 t ] − τ 0 t ρ ( µ t , φ t )] } , µ t ∈ I R , φ t ∈ I R + 7 whic h represents the kernel of the densit y function of the normal-gamma distribution with parameters τ 1 t τ 0 t , τ 0 t , τ 0 t + 1 2 and − τ 2 1 t 2 τ 0 t − τ 2 t . Using the natural link functions η 1 t = g 1 ( µ t ) = µ t and η 2 t = g 2 ( φ t ) = log ( φ t ), and the crude appro ximation of the digamma function, ψ ( x ) = l og ( x ) + O ( x ) , x > x 0 , to ev aluate the moments of the linear predictor η 2 t , it follows that moment conditions are represented as in the functional form ∆ k ( τ t ; f t , Q t ) = f 1 t − τ 1 t τ 0 t , f 2 t − log τ 0 t + 1 2 − τ 2 1 t 2 τ 0 t − τ 2 t − 1 ! , q 11 t − − τ 2 1 t 2 τ 0 t − τ 2 t τ − 1 0 t τ 0 t + 1 2 − 1 − 1 , q 22 t − 2 τ 0 t + 1 ! . (7) Therefore τ t is obtained as the solution that minimizes the asso ciated quadratic form. Note that in this example the prior cov ariance of the linear predictors ( η 1 t , η 2 t ), at eac h time t , are zero, whic h indicates that Q t is a diagonal matrix. In fact, it means that η 1 is orthogonal to η 2 giv en D t − 1 , so the system reduces to four equations. Nevertheless solving system (7) is not a trivial minimization problem since we need to ensure that all inv olved moments are w ell defined, in the sense that at each algorithm’s iteration, τ 0 t , τ 1 t and τ 2 t generate non-negative v ariances. In this particular example, the minimization with respect to the v ector τ t m ust satisfy the restrictions τ 0 t > 1 and τ 2 t < − τ 2 1 t 2 τ 0 t , assuming that the first and second moments of expression (7) are well defined. 3.3.2 In verse Gaussian distribution Supp ose that p ( y t | µ t , φ t ) represents the density function of in verse normal distribution with mean µ t and v ariance µ 3 t φ t in mo del (3). It is very ease to show that this mo del is a member of the exp onen tial family , taking d 1 ( y t ) = − y t , d 2 ( y t ) = − 1 2 y t , ρ ( µ t , φ t ) = − φ t µ t + 1 2 log( φ t ) and a ( y ) = (2 π y 3 t ) − 1 / 2 . In this case, the conjugate prior distribution for the observ ational mo del is p ( µ t , φ t | D t − 1 ) ∝ exp − φ t 1 2 µ 2 t τ 1 t + 1 2 τ 2 t + τ 0 t ρ ( µ t , φ t ) , µ t > 0 , φ t > 0 . (8) As explained in Banerjee and Bhattac haryya (1979), conditional to φ t , µ − 1 t follo ws a normal distribution truncated at zero; and, conditional to µ t , φ t follo ws a gamma distribution. On the other hand, p ( µ t , φ t | D t − 1 ) do es not hav e an analytically known form, as far as we know, so we approximate its mean and v ariance by the mo de ( ˜ µ t , ˜ φ t ) 0 and the inv erse curv ature matrix ˜ V t of the conjugate prior distribution (8) ev aluated at the mo de p oin t, resp ectiv ely , getting ˜ µ t ˜ φ t = τ 1 t /τ 0 t τ 0 t τ 2 t − τ 2 0 t τ 1 t − 1 and ˜ V t = ˜ µ 3 t τ 0 t ˜ φ t 0 0 2 ˜ φ 2 t τ 0 t . 8 Using the link functions g 1 ( µ t ) = log( µ t ) and g 2 ( φ t ) = log( φ t ), and taking first-order T aylor appro ximations of these functions around ( ˜ µ t , ˜ φ t ) 0 , we obtain the mode and curv ature of the linear predictors. Then to equate the n umerical momen ts of the linear predictors with those obtained using their conjugate prior we must solve the system of equations ∆ k ( τ t ; f t , Q t ) = f 1 t − log( τ 1 t ) + log( τ 0 t ) , f 2 t − log τ 0 t τ 1 t τ 1 t τ 2 t − τ 2 0 t , q 11 t − τ 1 t τ 2 t τ 3 0 t + 1 τ 0 t , q 22 t − 2 τ 0 t . (9) The optimization problem (7), based on ∆ k lik e in (9), must satisfy the constraints τ 2 t > τ 0 t τ 1 t with τ 0 t , τ 1 t > 0 in order to ensure that all v ariances are p ositive. 3.3.3 Gamma distribution Let y t | µ t , φ t denote the density function of the gamma distribution, with mean µ t and v ariance µ 2 t φ t . The quantities defining this member of the t wo-parameter exp onen tial family are: θ t = 1 µ t , d 1 ( y t ) = − y t , d 2 ( y ) = log ( y t ) and ρ ( θ t , φ t ) = log(Γ( φ t )) − φ t log φ t µ t and, therefore, its conjugate prior distribution is given by p ( µ t , φ t | D t − 1 ) ∝ exp φ t − 1 µ t τ 1 t + τ 2 t − τ 0 t ρ ( θ t , φ t ) , µ t > 0 , φ t > 0 . (10) Since the prior distribution do es not represent a known distribution, as far as we know, we opt to use its mo de and the inv erse curv ature matrix of the conjugate prior distribution (10) in place of its mean and v ariance. Using the logarithmic link functions for b oth parameters, we get E ( η 1 t | D t − 1 ]) ≈ log ( τ 1 t ) − log( τ 0 t ) and E ( η 2 t | D t − 1 ]) ≈ log τ 0 t 2 h τ 0 t log τ 1 t τ 0 t − τ 2 t i V ar ( η 1 t | D t − 1 ) ≈ 2 τ 2 0 t τ 0 t log τ 1 t τ 0 t − τ 2 t and V ar ( η 2 t | D t − 1 ) ≈ 2 τ 0 t . (11) Moreo ver, taking a first order T aylor approximation of the function g ( µ t , φ t ) = (log ( µ t ) log( φ t )) around the mo de of (10), w e obtain the cov ariance of the linear predictors as C ov ( η 1 t , η 2 t | D t − 1 ) ≈ log ( ˜ µ t ) log( ˜ φ t ) − [log( ˜ µ t )][log( ˜ φ t )] = 0 . Comparing the numerical moments obtained for linear predictors through the dynamic mo del with those obtained by conjugation (expressions (11), we obtain the functional form ∆ k ( τ t ; f t , Q t ) = f 1 t − log τ 1 t τ 0 t , f 2 t − log τ 0 t 2 h τ 0 t log τ 1 t τ 0 t − τ 2 t i , q 11 t − 1 τ 0 t ˜ φ t , q 22 t − 2 τ 0 t , (12) 9 whose quadratic distance with resp ect to zero (p ossibly weigh ted by a weigh ts matrix Ω k ) can b e minimized by imp osing the constraints τ 0 t > 0, τ 1 t > 0 and τ 2 t τ 0 t > f 1 t , which ensures that the moments up to second order asso ciated with the conjugate prior distribution (10) are well defined. 3.4 F orecasting Assume that our interest is to forecast some future observ ation, for example, at instant t + h (for some integer h ), based on all observ ations until instant t . Making use of exp onen tial family’s proprieties, it follows from conjugacy that p ( y t + h | D t ) = a ( y t + h ) κ ( τ t + h ) κ ( τ ∗ t + h ) , (13) where κ ( τ t + h ) and κ ( τ ∗ t + h ) are the normalization constants inv olv ed in the definition of the prior and the p osterior distribution of the vector ( θ t + h , φ t + h ), resp ectiv ely . Here, the parameter vector τ t + h = ( τ 0 ,t + h , τ 1 ,t + h , τ 2 ,t + h ) can b e obtained analogously to that discussed in Section 3.2, by solving the optimization problem arg min τ t + h { ∆ k ( τ t + h ; f t ( h ) , Q t ( h )) 0 Ω k ∆ k ( τ t + h ; f t ( h ) , Q t ( h )) } , (14) giv en the recursive relation b et ween the linear predictor momen ts η t | D t ∼ [ f t ( h ) , Q t ( h )] , f t ( h ) = F 0 t + h a t ( h ) , Q t ( h ) = F 0 t + h R t ( h ) F t + h , with a t ( h ) = G t + h a t ( h − 1) , a t (0) = m t , R t ( h ) = G t + h R t ( h − 1) G 0 t + h + W t + h and R t (0) = C t . Note that the v ector τ ∗ t + h = ( τ ∗ 0 ,t + h , τ ∗ 1 ,t + h , τ ∗ 2 ,t + h ) is directly obtained like in the relations represented in (2). In cases in which the constants κ ( · ) do not hav e known analytical form, we must use some numerical in tegration method to approximate them. In this work, Laplace appro ximations are used to solv e suc h in tegrals. All metho ds are implemented with the aid of routines av ailable in the free softw are R (T eam (2011)), like the optimization function nlminb and the function fdHess which numerically approximate gradien t and Hessian functions. F urthermore, to improv e the quality of the approaches, we use a new parameterization for the inv olv ed prior distributions in terms of their linear predictors η 1 t and η 2 t , in tegrating new parameters along the real line. See the next section for an example. 10 4 Case Studies In this section, tw o applications are presented to illustrate the p erformance of the prop osed metho d. In b oth cases w e suppose that the observ ations follow a b eta distribution. The first one mo dels unemplo yment rates in Brazil, using a data set that presents a trend comp onen t and a stable seasonal pattern. Our main in terest in this first application is to illustrate the imp ortance of dynamically modelling the precision parameter. The second one considers some macro economic v ariables of the United Kingdom, view ed as comp ositional data. In this example our aim is to show the imp ortance of mo delling the data in their original scale. T o start this section, we show the main developmen ts concerning the b eta mo del used in b oth applications. The implementations are carried out through the R softw are and more details is discussed b elow. 4.1 Dynamic b eta mo del comp onen ts Consider now p ( y t | µ t , φ t ) as the densit y function of a b eta distribution in mo del (3), parameterized in terms of its mean µ t and its v ariance µ (1 − µ ) φ . In this case, using conjugacy in the exp onen tial family , p ( µ t , φ t | D t − 1 ) ∝ exp { φ t [ µ t τ 1 t + τ 2 t ] + τ 0 t ρ ( µ t , φ t ) } , 0 < µ t < 1 , φ t > 0 . (15) where ρ ( µ t , φ t ) = − log Γ( φ t ) Γ( φ t µ t )Γ( φ t (1 − µ t ) . T aking g 1 ( µ t ) = logit( µ t ) and g 2 ( φ t ) = log ( φ t ) and appro ximating first and second momen ts of (15), resp ectiv ely , by the mo de ( ˜ µ t , ˜ φ t ) 0 and the inv erse curv ature matrix ev aluated at the mo de, we get E ( η 1 t | D t − 1 ) ≈ logit( ˜ µ t ) = τ 1 t τ 0 t and V ar ( η 1 t | D t − 1 ) ≈ 1 τ 0 t ˜ µ t (1 − ˜ µ t ) ˜ φ t E [ η 2 t | D t − 1 ] ≈ log ( ˜ φ t ) = log τ 0 t 2 { τ 0 t log(1 − ˜ µ t ) − τ 2 t } and V ar ( η 2 t | D t − 1 ) ≈ 2 τ 0 t . (16) The functional form (7) to b e minimized dep ends on the v ector function ∆ k ( τ t ; f t , Q t ) = f 1 t − τ 1 t τ 0 t , f 2 t − log τ 0 t 2 { τ 0 t log(1 − ˜ µ t ) − τ 2 t } , q 11 t − 1 τ 0 t ˜ µ t (1 − ˜ µ t ) ˜ φ t , q 22 t − 2 τ 0 t , (17) whose minimum must b e obtained by imp osing restrictions τ 0 t > 0 and τ 2 t > − τ 0 t log(1 + exp { f 1 t } ), since we are imp osing the condition that C ov ( η 1 t , η 2 t | D t − 1 ) = 0, such as in the gamma case. It is worth noting that although the b eta distribution has a conjugated prior represented in equation (15), it do es not hav e a known analytical form, as far as we know. So, to find its normalization constant w e need to approximate the integral κ ( τ 0 t , τ 1 t , τ 2 t ) − 1 = Z ∞ 0 Z 1 0 exp { φ t [ µ t τ 1 t + τ 2 t ] + τ 0 t ρ ( µ t , φ t ) } dµ t φ t , 11 b y using a Laplace approximation for its expression. In fact, by c hanging the v ariables of the integral in (18) in terms of η 1 t and η 2 t , we can approximate it as κ ( τ 0 t , τ 1 t , τ 2 t ) − 1 = Z ∞ −∞ Z ∞ −∞ exp e η 2 t e η 1 t 1 + e η 1 t τ 1 t + τ 2 t − τ 0 t ρ 0 ( η 1 t , η 2 t ) dη 1 t η 2 t ≈ √ 2 π | ˜ V t | 1 2 exp { L t ( ˜ η 1 t , ˜ η 2 t ) } , where ρ 0 ( η 1 t , η 2 t ) = log (Γ( e η 2 t )) − log Γ e η 2 t e η 1 t 1 + e η 1 t Γ e η 2 t 1 1 + e η 1 t , L t ( η 1 t , η 2 t ) = e η 2 t h e η 1 t 1+ e η 1 t τ 1 t + τ 2 t i + τ 0 t ρ 0 ( η 1 t , η 2 t ) and ˜ V t = − ∇ 2 L t ( η 1 t , η 2 t ) − 1 ( η 1 t ,η 2 t )=( ˜ η 1 t , ˜ η 2 t ) is the Hessian matrix of L t ( η 1 t , η 2 t ), applied in its mo de ( ˜ η 1 t , ˜ η 2 t ). Using the R soft ware, the mo de ( ˜ η 1 t , ˜ η 2 t ) and the Hessian matrix ˜ V t can b e easily obtained using, resp ectiv ely , the functions nlminb and fdHess , using the expression L t ( η 1 t , η 2 t ) as the argument. 4.2 Unemplo yment rates in Brazil The data for this example was collected by the Brazilian Institute of Geography and Statistics (IBGE: h ttp://www.ibge.gov.br/) through its Mon thly Emplo yment Surv ey and deals with mon thly unemplo yment rates of working-age p eople in the ma jor metropolitan regions of Brazil, namely the metrop olitan areas of Recife, Salv ador, Belo Horizonte, Rio de Janeiro, S˜ ao Paulo and Porto Alegre. The mon thly unemplo yment rates of working-age p eople from Marc h 2002 to December 2011, in a total of 118 observ ations, can b e seen in Figure 1. This time series clearly exhibits comp onents of trend and seasonalit y . month unemplo yment rate (%) 2002.03 2004.03 2006.03 2008.03 2010.03 0.06 0.10 0.14 Figure 1: Unemplo yment rates of w orking-age p eople in the ma jor metrop olitan regions of Brazil from Marc h 2002 to December 2011. It is well known that the yearly seasonal b eha viour in this time series is mainly due to temp orary jobs created b y holida y seasons and school v acations, as men tioned b y da Silv a et al. (2011). Considering these 12 factors, we analysed the data set through a dynamic b eta mo del, where the observ ational mean evolv e as a second-order p olynomial mo del with seasonal effect. Unlik e da Silv a et al. (2011), we assume a more parsimonious mo del, where seasonality is represen ted by a one-harmonic mo del and we assume that the precisions can ev olve dynamically in time. Additionally , we assume that the latent v ariables asso ciated with means and precisions ev olv e in time independently , taking the matrices F 0 t , G t , W t and C 0 as block diagonal matrices of the form F 0 t = diag( F 0 1 t , F 0 2 t ), G t = diag( G 1 t , G 2 t ), W t = diag( W 1 t , W 2 t ) and C 0 = diag( C 10 , C 20 ), where the matrices related to the dynamics of the observ ational means are given b y F 1 t = (1 , 0 , 1 , 0) 0 and G 1 t = J 2 (1) 0 0 J 2 (1 , ω ) , ∀ t, where J 2 (1) = 1 1 0 1 and J 2 (1 , ω ) = cos( ω ) sin( ω ) − sin( ω ) cos( ω ) , ω = 2 π 12 . T o mo del the disp ersions, we assume a first order dynamic mo del, taking F 2 t = G 2 t = 1, ∀ t , in order to allow precision parameter φ t to v ary in time through the introduction of a random error. W e chose to specify the error ev olution co v ariance matrices, W t , t ∈ { 1 , ..., t } , through the use of multiple discoun t factors assuming W t to b e a block diagonal matrix whose blo c ks are associated with mean lev el and trend and seasonal comp onen ts, and a precision level component, taking D = blo c kdiag { δ − 1 / 2 µ,lt I 2 , δ − 1 / 2 µ,s I 2 , δ − 1 / 2 φ,l } , where δ µ,lt , δ µ,s and δ φ,l are discoun t factors associated with the resp ectiv e blo c ks of comp onents by replacing the expression of R t in the evolution step of the algorithm with the form R t = D G t C t − 1 G 0 t D . Differen t combinations of discoun t factors w ere tried and we selected the one that pro vided the b est performance according to some alternativ e mo del selection criteria lik e the mean squared error (MSE)based on one-step-ahead forecasting, the joint log-likelihoo d (LL) and the log-observed predictive densit y (LPD), excluding the first 18 observ ations, taken as a learning perio d. Using the selected discount factors, namely , δ µ,lt = 0 . 90, δ µ,s = 0 . 95 and δ φ,l = 0 . 90, we obtained the mo del parameter estimates and the one-step-ahead predictive distributions for the unemplo yment rates during the perio d from September 2003 to Decem b er 2011 at eac h instan t, using expression (13) as discussed in the previous subsection with the aid of the R routines nlminb and fdHess . In Figure 2, it is p ossible to observe the filtered ( E [ β t | D t − 1 ]) and the smo othed estimated state v ariable means ( E [ β t | D T ]) related to the observ ational mean components, describing lev el, trend and seasonalit y , resp ectiv ely; and the state v ariable asso ciated with the observ ational precision. In fact, there is a clearly decreasing trend in the data as w ell as a seasonal b eha viour like observed in Figure 1. 13 Regarding the precision structure, the small growth of the state v ariable β 5 t o ver time can indicate that as new information is incorp orated in the estimation pro cess, the accuracy of the mo del increases. month β 1t 2002.03 2004.03 2006.03 2008.03 2010.03 −2.8 −2.4 −2.0 (a) level month β 2t 2002.03 2004.03 2006.03 2008.03 2010.03 −0.015 0.000 (b) trend month β 3t 2002.03 2004.03 2006.03 2008.03 2010.03 −0.10 0.00 (c) seasonality month β 5t 2002.03 2004.03 2006.03 2008.03 2010.03 7.0 8.0 9.0 (d) precision Figure 2: Filtered (solid line) and smo othed (dashed line) laten t states means for application using unemplo yment data. It can b e seen in Figures 3 and 4 that the metho d generated satisfactory results, since b oth estimated means (the filtered ones E [ µ t | D t ],) and one-step-ahead predictive distribution means ( E [ y t | D t − 1 ]) follow the b eha vior of the real data series, as illustrated by Figures 3 and 4, resp ectiv ely . Also note that the estimated 95% HPD credibilit y interv als for the one-step-ahead predictive distributions, represented by the dashed red lines in Figure 4, are well concentrated and contain the true v alue of the observ ations in all considered instances. The p oin t and interv al estimates for the predictive distributions considered in the last six instants can b e seen in T able 1. T o illustrate the imp ortance of dynamic mo delling for the precision parameter mo del, w e completed this application by comparing its results with those obtained using a similar mo del in whic h we assumed that φ t = φ , ∀ t , taking null precision evolution errors in matrix W t . Figure 4 compares the interv al estimates for the one-step-ahead predictiv e distribution obtained considering both mo dels. Note that 14 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● month unemplo yment rate (%) 2002.03 2004.03 2006.03 2008.03 2010.03 0.06 0.10 0.14 Figure 3: Filtered estimated observ ational means (solid line) based on laten t states p osterior means obtained for application using unemploymen t data. The gray p oin ts represent the true observ ations. Mon th y t Mean Mo de IC 95% 2011.07 0 . 060 0 . 062 0 . 061 [0 . 054 , 0 . 070] 2011.08 0 . 060 0 . 059 0 . 058 [0 . 052 , 0 . 066] 2011.09 0 . 060 0 . 056 0 . 056 [0 . 050 , 0 . 063] 2011.10 0 . 058 0 . 055 0 . 055 [0 . 048 , 0 . 061] 2011.11 0 . 052 0 . 054 0 . 055 [0 . 048 , 0 . 061] 2011.12 0 . 047 0 . 054 0 . 054 [0 . 048 , 0 . 060] T able 1: P oin t and interv al estimates of unemploymen t rates for the p eriod from July 2011 to December 2011, based on the predictive distributions p ( y t | D t − 1 ). in terv als based on a mo del with φ fixed in time (represen ted b y the shaded area in the graph) are less concen trated, indicating that there was a gain with resp ect to accuracy of the predictive distributions in this case, in which we considered the dynamic mo delling of the precision structure. 4.3 Exp enditure shares in the U.K. econom y As a second illustration of the prop osed metho dology , we apply the new metho d to a real data set concerning exp enditures in the UK economy for the p eriod 1955 to 2012. The quarterly data, obtained from the U.K. Office of National Statistics w eb page (h ttp://www.statistics.gov.uk/), deal with the costs of the economy , whose comp osition is describ ed by consumption ( c ), in vestmen t ( i ), gov ernmen t exp enditure ( g ) and exp ort ( e ) shares of U.K. gross final exp enditure. 15 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● month unemplo yment rate (%) 2002.03 2004.03 2006.03 2008.03 2010.03 0.00 0.10 0.20 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Figure 4: One-step-ahead predictiv e interv als from Septem b er 2003 to Decem b er 2011, based on the predictiv e distributions p ( y t | D t − 1 ) of alternativ e mo dels: the shaded region represen ts the 95% HPD predictiv e credibility interv als based on a mo del with φ fixed in time, whereas the solid lines represent the predictive distribution credibility in terv als based on a model with a dynamic precision parameter structure. The gray p oin ts are the observed unemploymen t rates. Despite the comp ositional nature of the data, in order to use the class of mo dels discussed in this article, which includes only univ ariate observ ational distributions in the exp onen tial family , w e analysed eac h of the rate series separately through a generalized dynamic mo del whose observ ations follow the b eta distributions, and for whic h w e assumed different mean and precision structures. W e denote the prop osed mo dels b y the mnemonic V ar( l ) and Pol( l ), meaning a v ectorial autorregressive component and a p olynomial trend, respectively , where l is the order of the correspondent mo del. This mo dels w ere com bined to mo del the transformed observ ational mean and the transformed observ ational precision in differen t forms. F or eac h case, as in the previous application, we assumed that the latent v ariables asso ciated with means and precisions mo del evolv e in time indep enden tly , taking the matrices F 0 t , G t , W t and C 0 as blo c k diagonal matrices. Under this hypothesis, three different structures were considered for the class of mo dels represen ted by (3) and (4): • V ar(2)P ol(0) - Second order V AR mo del for the transformed observ ational mean and constant for the transformed observ ational precision: F or the means structure, we assumed that eac h series can b e explained b y all the other series, taking 16 t wo lags in time, assuming a second-order V AR mo del. F or the precision structure, we assumed that each series has a constant accuracy in time, taking F 1 t = 1 , x c ,t − 1 , x g ,t − 1 , x i ,t − 1 , x e ,t − 1 , x c ,t − 2 , x g ,t − 2 , x i ,t − 2 , x e ,t − 2 0 , G 1 t = I 9 , W 1 t = 0 , and F 2 t = G 2 t = 1 , W 2 t = 0 , ∀ t ∈ { 1 , ..., T } , where x c ,. , x g ,. , x i ,. , x e ,. , represent, resp ectiv ely , the rates of consumption, gov ernment exp enditure, inv estmen t and exp orts in previous instants. • V ar(2)P ol(1) - T ransformed observ ational mean mo delled by a second order V AR and precision with a first order dynamic structure: As in the previous case, we assumed means explained by a second-order V AR mo del, but in this case we allow ed the precisions to v ary in time according to a first order p olynomial mo del taking F 1 t = 1 , x c ,t − 1 , x g ,t − 1 , x i ,t − 1 , x e ,t − 1 , x c ,t − 2 , x g ,t − 2 , x i ,t − 2 , x e ,t − 2 0 , G 1 t = I 9 , W 1 t = 0 , and F 2 t = G 2 t = 1 , W 2 t 6 = 0 , ∀ t ∈ { 1 , ..., T } , where, again, x c ,. , x g ,. , x i ,. , x e ,. , represent, resp ectiv ely , the rates of consumption, gov ernment exp enditure, inv estmen t and exp orts in previous instants. • P ol(2)P ol(1) - Polynomial mo dels for b oth mean and precision structures: F or the means w e assumed a second-order mo del in which we considered lev el and trend for each of the series and a first-order structure for the precisions, taking F 1 t = 1 0 , G 1 t = J 2 (1) = 1 1 0 1 , W 1 t 6 = 0 and F 2 t = G 2 t = 1 , W 2 t 6 = 0 ∀ t ∈ { 1 , ..., T } . As in the previous application, w e chose to sp ecify the co v ariance matrices through the use of m ultiple discoun t factors, assuming blo c k diagonal matrices, whose blocks are asso ciated with the respective comp onen ts (lev el and trend in the case of second-order mo del and lev el in the order 1 mo del) in p olynomial mo dels. More sp ecifically , considering, for example, the P ol(2)Pol(1) structure, w e used a blo ck diagonal discount matrix of the form D = blo c kdiag { δ − 1 / 2 µ,lt I 2 , δ − 1 / 2 φ,l } , where δ µ,lt is the discount factor asso ciated with mean level and trend components and δ φ,l is the discount factor associated with 17 precision level comp onen ts, substituting the expression of R t in the evolution step of the algorithm for the form R t = D G t C t − 1 G 0 t D , as discussed in Chapter 6 of W est and Harrison (1997). F or each of the rate series and for each of the dynamic structures assumed, different combinations of discount factors v alues w ere used, so we selected the one that provided the b est data fit according to the mean squared error (MSE) based on one-step-ahead forecasting, the joint log-likelihoo d (LL) and the log-observed predictive density (LPD) of eac h series, excluding the first 31 observ ations (tak en as learning sample). F or this application, differen t combinations of v alues 0 . 90, 0 . 95 and 0 . 98 were tak en for the discount factors and, for all assumed dynamic structures, mo dels with smaller v alues, namely δ µ,lt = δ φ,l = 0 . 90, outp erformed. T able 2 rep orts adjustmen t measures for the different dynamic mo dels. It can b e seen that, according to the criteria used, the mo del that supp oses a second-order V ar structure for the mean and a first order structure for the precision p erforms b etter with low er MSE and v alues and higher LL and LPD v alues, whic h makes sense since the V ar structure capturing the relationship b et ween the different rate series and allows the precision mo del structure to v ary in time, giving greater flexibility to the mo del. Mo del V AR(2)P ol(0) V AR(2)P ol(1) P ol(2)Pol(1) consumption MSE LL LPD 0 . 400e − 4 745 . 507 724 . 151 0 . 400e − 4 759 . 776 725 . 504 0 . 838e − 4 706 . 711 653 . 134 in vestmen t MSE LL LPD 0 . 525e − 4 714 . 757 694 . 131 0 . 505e − 4 730 . 774 698 . 827 1 . 083e − 4 691 . 014 636 . 617 Mo del V ar(2)Pol(0) V ar(2)Pol(1) P ol(2)Pol(1) go vernmen t exp enditure MSE LL LPD 0 . 105e − 4 881 . 688 857 . 297 0 . 101e − 4 899 . 035 862 . 609 0 . 453e − 4 761 . 649 707 . 335 exp ort MSE LL LPD 0 . 495e − 4 726 . 010 702 . 890 0 . 463e − 4 745 . 200 710 . 554 1 . 127e − 4 676 . 193 621 . 606 T able 2: MSE based on one-step-ahead forecasting, joint log-lik eliho o d (LL) and log-observed predictive densit y (LPD) based on consumption, in vestmen t, go vernmen t exp enditure and export rates for the p eriod from 1963.2 to 2012.3, obtained from differen t mo dels. 18 Once the V ar(2)P ol(1) model w as selected, w e estimated the parameters and the one-step-ahead predictiv e distributions for the four rate series during the p erio d 1963.2 to 2012.3, as represented by Figures 5 and 6, resp ectiv ely . In Figure 5 it is possible to observ e the p oin t estimates for the observ ational means of each series (the filtered ones E [ µ t | D t ]. Note that for all analysed series, the estimated means closely parallel the b eha viour of the data series. Similar b ehaviour can also b e observ ed for the estimated predictiv e mean’s ( E [ y t | D t − 1 ]), shown in Figure 6. It can also b e seen that the estimated 95% HPD credibilit y interv als for the one-step-ahead predictive distributions are w ell concentrated, containing the true observ ation v alues in most cases. P oint and in terv al predictive estimates for inv estment rates for some considered instants can b e seen in T able 3. ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● quar ter consumption share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.45 0.50 0.55 (a) consumption ( c ) ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● quar ter inv estment share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.12 0.16 (b) inv estment ( i ) ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● quar ter consumption share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.45 0.50 0.55 (c) gov ernment exp enditure ( g ) ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● quar ter export share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.16 0.20 0.24 (d) exp ort ( e ) Figure 5: Filtered estimated observ ational mean (solid line) based on latent states p osterior means for the quarterly shares of U.K. gross final exp enditure for the perio d from 1955.1 to 2012.3. The p oin ts represen t the true data set. The smo othed p osterior mean estimates ( E [ µ t | D T ]) for all data series are represen ted in Figure 7. Although we treated each time series separately the estimates obtained are consistent, in the sense that, at each instant, the sum of the estimated means are appro ximately one. This b eha viour indicates that, 19 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● quar ter consumption share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.45 0.50 0.55 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● (a) consumption ( c ) ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● quar ter inv estment share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.10 0.14 0.18 ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● (b) inv estment ( i ) ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● quar ter gov. e xpenditure share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.14 0.17 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ●● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ●● ● ● ●● ● ● ● ● ●● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● (c) gov ernment exp enditure ( g ) ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● quar ter export share (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.14 0.20 0.26 ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● (d) exp ort ( e ) Figure 6: One-step-ahead prediction for the quarterly shares of U.K. gross final exp enditure for the p erio d from 1963.2 to 2012.3. The solid line represents the predictive distribution means ( E [ y t | D t − 1 ]) and the shaded region the 95% HPD predictive credibility in terv als. The p oin ts represent the true data set in eac h case. despite the simplicity of the mo del used in this application, the b eha viour of the series is w ell captured b y the prop osed mo del. A subsets of the data set use d in this application hav e already b een analyzed by Mills (2010). Under a classical point of view, Mills (2010) estimated an order 2 V AR mo del, using a m ultiv ariate normal distribution to mo del a transformation of the original data as log c e , log i e and log g e , (18) where c , i , g and e represent consumption, in vestmen t, gov ernment expenditure and exp ort rates, resp ectiv ely . In order to ascertain whether there is any adv an tage in analysing the data in their original scale we reanalysed these data set transforming them as prop osed by Mills (2010) (according to equations (18)), replacing the observ ational b eta distributions with univ ariate normal distributions for each series. Again 20 quarter ( t ) 2011.1 2011.2 2011.3 2011.4 2012.1 2012.2 2012.2 in vestmen t y t mean mo de IC 95% 0 . 106 0 . 117 0 . 117 [0 . 105 , 0 . 131] 0 . 112 0 . 112 0 . 111 [0 . 098 , 0 . 126] 0 . 116 0 . 113 0 . 113 [0 . 101 , 0 . 126] 0 . 110 0 . 116 0 . 116 [0 . 103 , 0 . 130] 0 . 107 0 . 114 0 . 114 [0 . 102 , 0 . 127] 0 . 110 0 . 110 0 . 110 [0 . 097 , 0 . 124] 0 . 109 0 . 112 0 . 111 [0 . 100 , 0 . 125] T able 3: Poin t and in terv al estimates of the quarterly in vestmen t ( i ) shares of U.K. gross final expenditure based on the predictive distributions p ( y t | D t − 1 ). quar ter U.K. e xpenditure shares (%) 1955.1 1965.1 1975.1 1985.1 1995.1 2005.1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ●● ● ● ●● ● ● ●● ●● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● c e g i Figure 7: Smo othed posterior estimates for the observ ational means for quarterly consumption ( c ), in vestmen t ( i ), gov ernmen t expenditure ( g ) and exp ort ( e ) shares concerning expenditure in the UK econom y ov er the p eriod 1955.1 to 2012.3. Gra y con tinuous lines represent true observ ations. w e chose to model each series separately using analogous structures to those adopted in the b eta case and assuming different discount factors for cases that include dynamics for the latent v ariables. According to the mo del comparison criteria used in this article, the b est fitted standard model was the one in whic h we assumed a second-order V AR model for the observ ational means and a first-order model for the precisions, 21 consumption in vestmen t go v. exp enditure V AR(2)P ol(1) b eta mo del MSE LL LPD 0 . 400e − 4 759 . 776 725 . 504 0 . 505e − 4 730 . 774 698 . 827 0 . 101e − 4 899 . 035 862 . 609 V AR(2)P ol(1) normal mo del MSE LL LPD 0 . 061 472 . 727 474 . 535 0 . 112 591 . 338 374 . 790 0 . 101 591 . 906 440 . 599 T able 4: Mean square error (MSE) based on one-step-ahead forecasting, joint log-likelihoo d (LL) and log-observ ed predictive densit y (LPD) based on consumption, inv estment, gov ernment exp enditure and exp ort rates for the p eriod from 1963.2 to 2012.3, obtained from differen t mo dels. assuming a discoun t factor equal to 0 . 90 to sp ecify the error evolution cov ariance matrices of the latent v ariables asso ciated with precision structure. T o compare the p erformance of the b est b eta mo del with the corresp onding normal one (both with V ar(2)Pol(1)), we recalculated the normal mo del fit measures correcting each measure through the Jacobian of the transformation, in order to obtain adjustment measures in a same scale. The results for the fit measures for the different mo dels can b e seen in T able 4. Its p ossible to see that all the criteria that take into accoun t one-step-ahead predictive distribution estimates of each of the series indicate a b etter p erformance of the b eta mo del. Indeed, for the three considered series, the b eta mo del had low er MSE and higher LL and LPD for all cases, giving evidence that the mo delling of the data in their original scale has adv antages regarding the predictive abilit y of the mo del. 5 Conclusions and Additional Commen ts In this pap er w e prop ose a method for estimation and prediction of dynamic mo dels whose observ ations follo w distributions of the tw o-parameter exp onen tial family . The estimation in the prop osed partially sp ecified mo del class, represented b y equations (3) and (4), is based on a extension of the conjugate up dating algorithm of W est et al. (1985). The main idea of this new metho d is to explore prop erties of conjugacy in the exp onential family and linear Bay es estimation, allowing the quick up dating of b oth mean and precision mo del parameters through analytical strategies, av oiding computationally intensiv e metho ds such as those based on Monte Carlo estimation. Our algorithm stands out mainly for t wo reasons: first it treats a very general class of mo dels with observ ations in the exp onential family , whic h allows mo delling data in their original scale, such as in 22 McCullagh and Nelder (1989)’ MLG. Second, the introduction of a second link function in the mo del allo ws treatment of ov erdispersion and heteroscedasticity in data, and allows the precision structure of the mo del to b e dynamically treated, efficien tly capturing the data b eha viour even through the use of partially sp ecified mo dels. Sim ulated studies presented b y Souza (2013), assuming differen t observ ational models in the tw o- parameter exponential family , show that the prop osed metho d generated satisfactory results b oth as regards obtaining point and interv al estimates for the parameters, as in steps-ahead forecasting. The applications to real data presented in Section 4 of this pap er also illustrate the go o d p erformance of the prop osed algorithm and demonstrate the relev ance of mo delling data in their original scale. Although use of MMG has b een shown to b e a go od alternative to reduce the dimensionality of the system treated in Section 3.2, we in tend to study other alternatives for reducing the system (5). Also with resp ect to the use of the generalized metho d of moments, we intend to study the choice of weigh ts matrix Ω k with the aim of chec king whether there is any gain in quality of estimates by introducing an iterativ e choice of weigh ts matrix Ω k , as discussed in Newey (1993) and Hamilton (1994). As the main extension of this work we intend to extend the conjugate up dating algorithm in order to treat classes of multi-parameter and m ultiv ariate mo dels, such as mo dels whose observ ations follow Diric hlet or multinomial distributions, the parameters of whic h can b e explained by different link functions. References Banerjee, A. K. and Bhattacharyy a, G. K. (1979) Bay esian Results for the Inv erse Gaussian Distribution with Application. T e chnometrics , 21 , 247–251. Bernardo, J. M. and Smith, A. F. M. (1994) Bayesian The ory . John Wiley & Sons. Cep eda, E. C. and Gamerman, D. (2005) Ba yesian metho dology for mo deling parameters in the t wo parameter exp onential family . R evista Estad ´ ıstic a , 57 , 93–105. Cep eda, E. C., Migon, H. S., Achcar, J. A. and Garrido, L. (2011) Generalized linear models with random effects in the tw o parametric exp oencial family . T e ch. r ep. , Universidade F ederal do Rio de Janeiro. Dey , D. K., Gelfand, A. E. and P eng, F. (1997) Overdispersed generalized linear mo dels. Journal of Statistic al Planning and Infer enc e , 64 , 93–107. Efron, B. (1986) Double exp onencial families and their use in generalized linear regression. Journal of the Americ an Statistic al Asso ciation , 81 , 709–721. 23 Gelfand, A. and Dalal, S. (1990) A note on ov erdisp ersed exp onen tial families. Biometrika , 77 , 55–64. Hamilton, J. (1994) Time series analysis . Princeton Universit y Press. Lindsa y , B. G. (1986) Exp onencial family mixture mo dels. The Annals of Statistics , 14 , 124–137. McCullagh, P . and Nelder, J. A. (1989) Gener alize d line ar mo dels . Chapman & Hall. Mills, T. (2010) F orecasting comp ositional time series. Qual Quant , 44 , 673–690. Nelder, J. A. and Lee, Y. (2001) Generalized linear mo dels for the analysis of taguchi-t yp e exp erimen ts. J. Pr ob ab. Stat. , 14 , 207–221. Nelder, J. A. and W edderburn, R. W. M. (1972) Generalized linear models. Journal of the R oyal Statistic al So ciety. Series A (Gener al) , 135 , 370–384. New ey , W. (1993) Efficien t estimation of mo dels with conditional momen t restrictions. Handb o ok of Statistics , 11 , 419–454. P o ole, D. and Raftery , A. E. (2000) Inference for Deterministic Sim ulation Models: The Ba yesian Melding Approac h. Journal of the Americ an Statistic al Asso ciation , 95 , 1244–1255. da Silv a, C. Q., Migon, H. S. and Correia, L. T. (2011) Dynamic Bay esian b eta mo dels. Computational Statistics & Data Analysis , 55 , 2074–2089. Souza, M. A. O. (2013) Apr oxima¸ c˜ oes anal ´ ıtic as e inferˆ encia em mo delos na fam ´ ılia exp onencial bip ar am ´ etric a . Ph.D. thesis, Universidade F ederal do Rio de Janeiro. T eam, R. D. C. (2011) R: A L anguage and Envir onment for Statistic al Computing . R F oundation for Statistical Computing. URL http://www.R- project.org/ . W est, M. and Harrison, J. (1997) Bayesian F or e c asting and Dynamic Mo dels . Springer V erlag. W est, M., Harrison, P . and Migon, H. (1985) Dynamic generalized linear models and Bay esian forecasting (with discussion). Journal of the Americ an Statistic al Asso ciation , 80 , 7397. Yin, G. (2009) Bay esian Generalized Metho d of Moments. Bayesian A nalysis , 4 , 191–208. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment