Traversing Knowledge Graphs in Vector Space
Path queries on a knowledge graph can be used to answer compositional questions such as “What languages are spoken by people living in Lisbon?”. However, knowledge graphs often have missing facts (edges) which disrupts path queries. Recent models for knowledge base completion impute missing facts by embedding knowledge graphs in vector spaces. We show that these models can be recursively applied to answer path queries, but that they suffer from cascading errors. This motivates a new “compositional” training objective, which dramatically improves all models’ ability to answer path queries, in some cases more than doubling accuracy. On a standard knowledge base completion task, we also demonstrate that compositional training acts as a novel form of structural regularization, reliably improving performance across all base models (reducing errors by up to 43%) and achieving new state-of-the-art results.
💡 Research Summary
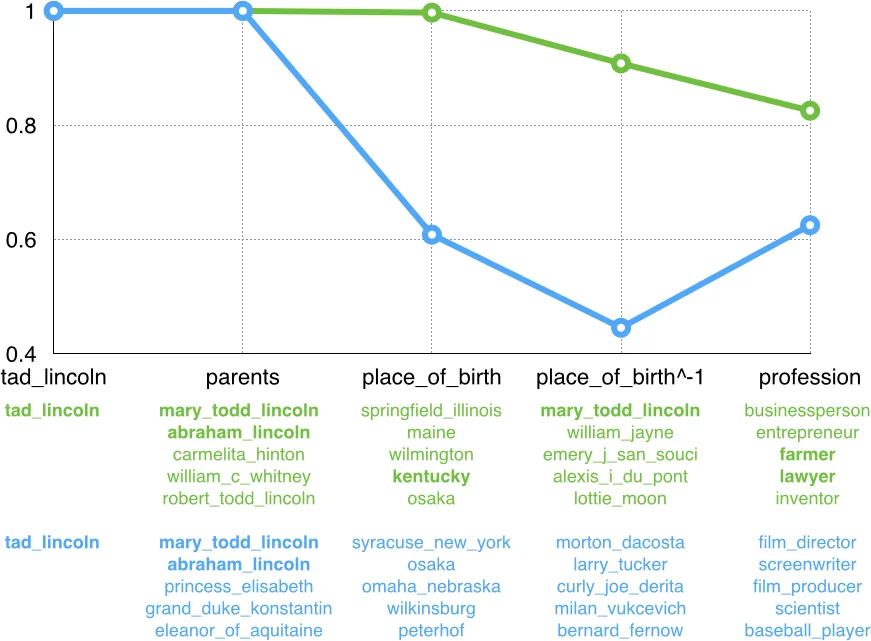
The paper addresses the problem of answering compositional path queries on knowledge graphs (KGs) that are inherently incomplete. Traditional knowledge base completion (KBC) models embed entities and relations into a low‑dimensional vector space and are trained only on single‑edge triples, which limits their ability to handle multi‑step queries because errors accumulate when the learned edge‑wise operators are applied recursively.
The authors propose a general “compositionalization” framework that reinterprets any KBC model whose scoring function can be written as score(s/r, t) = M(T_r(x_s), x_t) where T_r is a relation‑specific transformation (the traversal operator) and M is a membership function measuring similarity between a transformed source vector and a target vector. By repeatedly applying T_r for each relation in a path q = s/r₁/…/r_k, a “set vector” J_q^V is produced, and the final score for a candidate answer t is M(J_q^V, x_t). This view naturally extends single‑edge models to arbitrary‑length paths.
To train models that preserve useful information across successive traversals, the authors introduce a max‑margin compositional training objective. They generate a large corpus of path queries by performing random walks on the training graph, sampling both correct answers and a set of negative candidates. The loss J(Θ)=∑i∑{t’∈N(q_i)}
Comments & Academic Discussion
Loading comments...
Leave a Comment