Hierarchical networks of scientific journals
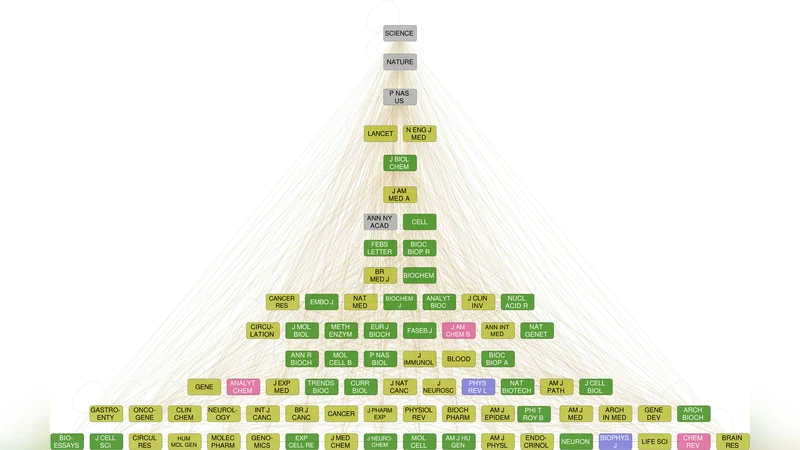
Scientific journals are the repositories of the gradually accumulating knowledge of mankind about the world surrounding us. Just as our knowledge is organised into classes ranging from major disciplines, subjects and fields to increasingly specific topics, journals can also be categorised into groups using various metrics. In addition to the set of topics characteristic for a journal, they can also be ranked regarding their relevance from the point of overall influence. One widespread measure is impact factor, but in the present paper we intend to reconstruct a much more detailed description by studying the hierarchical relations between the journals based on citation data. We use a measure related to the notion of m-reaching centrality and find a network which shows the level of influence of a journal from the point of the direction and efficiency with which information spreads through the network. We can also obtain an alternative network using a suitably modified nested hierarchy extraction method applied to the same data. The results are weakly methodology-dependent and reveal non-trivial relations among journals. The two alternative hierarchies show large similarity with some striking differences, providing together a complex picture of the intricate relations between scientific journals.
💡 Research Summary
The paper “Hierarchical networks of scientific journals” tackles the problem of evaluating scientific journals beyond the traditional one‑dimensional metrics such as impact factor. Using the complete Web of Science (WoS) citation data from 1975 to 2011, which comprises 35,372,038 papers published in 13,202 distinct journals, the authors construct two complementary hierarchical representations of the journal system.
The first hierarchy is a flow hierarchy derived from the concept of m‑reach centrality. For a given journal J, the m‑reach Cₘ(J) is defined as the number of distinct papers that can be reached in at most m citation steps when the direction of citation links is reversed (i.e., from a cited paper to the papers that cite it). The authors explore a range of m values and find that m = 3 provides a balance: it captures multi‑step influence without causing saturation that would mask differences among top journals. Journals with larger Cₘ values are placed higher in the hierarchy because they can disseminate knowledge more efficiently through the citation network. This measure is deliberately insensitive to the sheer volume of articles a journal publishes; it reflects the reach of the journal’s content irrespective of whether the reach is achieved by many low‑cited papers or a few highly cited ones.
The second hierarchy is a nested hierarchy obtained by adapting an automated tag‑hierarchy extraction algorithm (Tibély et al., 2013). Here each journal is treated as a “tag” and the algorithm analyses co‑occurrence patterns and inclusion relationships within the citation network to recursively group journals into larger clusters. The resulting tree has interdisciplinary, high‑impact journals at the root, while increasingly specialized journals form deeper branches. This representation emphasizes the structural containment of fields rather than the dynamic spread of information.
Both hierarchies are compared and found to be broadly consistent: the most influential journals (e.g., Nature, Science, Cell) occupy top positions in both trees. However, notable differences emerge. In the flow hierarchy, a journal’s position is driven by its ability to propagate citations across disciplines, so journals that act as bridges (e.g., PNAS, Proceedings of the National Academy of Sciences) rank highly. In the nested hierarchy, the emphasis is on disciplinary breadth; journals that publish a wide variety of topics but may not be the most “viral” appear near the root. Conference proceedings and technical reports, which receive few citations, consistently fall to the bottom of both hierarchies.
Methodologically, the authors avoid aggregating all papers of a journal into a single node for the flow analysis, because such aggregation can obscure memory effects (the tendency of papers to cite within the same discipline) and distort reach calculations. Instead, they work directly on the paper‑level citation network, then map the resulting Cₘ values back to journals. For journal identification they rely on an 11‑character abbreviated journal field, which eliminates variability caused by volume, issue, or year information in full journal titles.
The paper discusses several limitations. The choice of m influences the granularity of the flow hierarchy; different fields may have optimal m values. Citation data are inherently time‑biased, favoring recent publications, and the WoS coverage may miss certain disciplines or non‑English venues. Moreover, journal policies (e.g., open‑access transitions) can affect citation patterns over time. The authors suggest future work on dynamic hierarchies that evolve with time, field‑specific calibration of m, and cross‑validation with other bibliometric databases such as Scopus or PubMed.
In conclusion, by combining a diffusion‑oriented flow hierarchy with a structural nested hierarchy, the study provides a richer, multidimensional portrait of scientific journals. This dual perspective reveals non‑trivial relationships that single‑metric rankings overlook, offering researchers, librarians, and policymakers a more nuanced tool for journal selection, evaluation, and understanding of the knowledge‑production ecosystem.
Comments & Academic Discussion
Loading comments...
Leave a Comment