Maintaining prediction quality under the condition of a growing knowledge space
Intelligence can be understood as an agent’s ability to predict its environment’s dynamic by a level of precision which allows it to effectively foresee opportunities and threats. Under the assumption that such intelligence relies on a knowledge space any effective reasoning would benefit from a maximum portion of useful and a minimum portion of misleading knowledge fragments. It begs the question of how the quality of such knowledge space can be kept high as the amount of knowledge keeps growing. This article proposes a mathematical model to describe general principles of how quality of a growing knowledge space evolves depending on error rate, error propagation and countermeasures. There is also shown to which extend the quality of a knowledge space collapses as removal of low quality knowledge fragments occurs too slowly for a given knowledge space’s growth rate.
💡 Research Summary
The paper tackles a fundamental problem in any system that continuously acquires new information: how to keep the predictive quality of its internal knowledge base high while the amount of stored knowledge keeps expanding. The authors start by defining intelligence as the ability of an agent to forecast environmental dynamics with sufficient precision, and they model the agent’s “knowledge space” as a collection of discrete knowledge fragments. Each fragment can be either useful (high‑quality) or misleading (low‑quality). The proportion of high‑quality fragments is denoted by Q, while 1‑Q represents the fraction of erroneous fragments.
Three processes drive the evolution of Q over time. First, when new fragments are added, a fraction p_err of them contain errors. This is the error‑insertion rate. Second, because fragments are linked in a network‑like structure, errors can spread from a corrupted fragment to its neighbors with probability ε; this captures error propagation through logical dependencies, feature reuse, or shared assumptions. Third, the system can actively remove low‑quality fragments at a rate r, representing verification, pruning, or re‑training mechanisms.
Combining these processes yields a continuous‑time differential equation:
dQ/dt = –p_err·(1–Q) – ε·Q·(1–Q) + r·(1–Q)
The first term models the dilution of quality by newly introduced errors, the second term models the loss of quality due to error contagion, and the third term models the recovery of quality through pruning. Solving for the steady state (dQ/dt = 0) gives
Q* = (r – p_err) / (r + ε – p_err)
A positive steady‑state quality exists only when the pruning rate exceeds the raw error‑insertion rate (r > p_err). If r ≤ p_err, the denominator dominates and Q* collapses to zero, meaning the knowledge space becomes entirely corrupted.
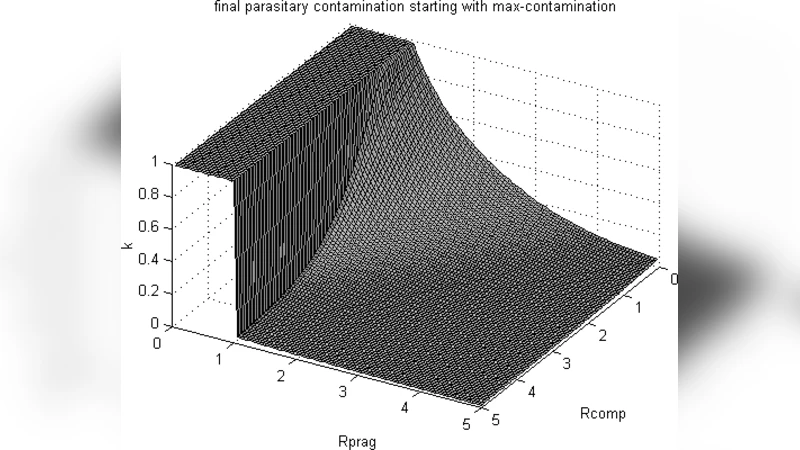
The authors further introduce a growth rate g, the speed at which new fragments are added. By defining the dimensionless ratio γ = r/g, they derive a critical pruning‑to‑growth threshold γ_c = (p_err + ε·Q)/g. When γ falls below γ_c, the system cannot keep up with the influx of noisy information, and the quality Q decays rapidly, often in a near‑exponential fashion.
To validate the analytical results, the paper presents extensive simulations across a wide parameter space. The simulations confirm that when pruning is sufficiently fast relative to both error insertion and propagation, Q stabilizes near the predicted Q*. Conversely, when pruning lags, especially under high ε (strong error propagation), the quality collapses abruptly. The authors illustrate this collapse with phase‑transition‑like plots showing a sharp boundary between “stable” and “unstable” regimes.
Beyond the mathematical treatment, the paper discusses practical implications for several domains. In continual‑learning AI systems, new data streams constantly augment model parameters; without regular data cleaning, label verification, and model distillation, noise can percolate through the network and degrade performance. In corporate knowledge‑management platforms, rapid document ingestion without systematic review can flood the repository with outdated or incorrect information, leading to decision‑making errors. The authors argue that any scalable knowledge‑growth strategy must embed automated or semi‑automated pruning pipelines, monitor error‑propagation pathways (e.g., through dependency graphs), and adjust the pruning intensity in proportion to the observed growth rate.
In summary, the paper provides a concise yet powerful quantitative framework that links three key rates—error insertion, error propagation, and pruning—to the long‑term health of a growing knowledge base. It demonstrates mathematically and empirically that maintaining high predictive quality is feasible only when the system’s corrective mechanisms scale at least linearly with the rate of knowledge acquisition, and that neglecting this balance inevitably leads to a catastrophic collapse of knowledge quality. This insight is broadly applicable to AI research, data engineering, and organizational information governance.