Egyptian Dialect Stopword List Generation from Social Network Data
This paper proposes a methodology for generating a stopword list from online social network (OSN) corpora in Egyptian Dialect(ED). The aim of the paper is to investigate the effect of removingED stopwords on the Sentiment Analysis (SA) task. The stopwords lists generated before were on Modern Standard Arabic (MSA) which is not the common language used in OSN. We have generated a stopword list of Egyptian dialect to be used with the OSN corpora. We compare the efficiency of text classification when using the generated list along with previously generated lists of MSA and combining the Egyptian dialect list with the MSA list. The text classification was performed using Na"ive Bayes and Decision Tree classifiers and two feature selection approaches, unigram and bigram. The experiments show that removing ED stopwords give better performance than using lists of MSA stopwords only.
💡 Research Summary
The paper addresses a gap in Arabic natural language processing (NLP) research: most existing stop‑word resources are built for Modern Standard Arabic (MSA), while user‑generated content on online social networks (OSN) is overwhelmingly written in dialects. Focusing on Egyptian Dialect (ED), the authors propose a systematic methodology for automatically generating a dialect‑specific stop‑word list from OSN corpora and then evaluate its impact on a sentiment‑analysis (SA) task.
Data collection and preprocessing
The authors crawled publicly available posts from Facebook, Twitter, and Instagram that were identified as being written in Egyptian Dialect. After filtering out non‑Arabic scripts, URLs, emojis, and other noise, they applied Arabic‑specific normalization (e.g., unifying different forms of alif) and tokenization, ending up with a clean corpus of roughly 45 000 sentences (average length 12‑15 tokens).
Automatic candidate extraction
From the cleaned corpus, candidate stop‑words were extracted using a hybrid frequency‑TF‑IDF approach. Tokens that appeared very frequently across many documents were flagged, and a preliminary list of about 3 500 candidates was produced. Additional rule‑based filters removed numbers, proper nouns, and obvious foreign words.
Expert validation
Two native speakers with expertise in Egyptian Dialect manually reviewed the candidate list. They retained tokens that function as discourse particles, filler words, or otherwise carry little semantic weight (e.g., “يعني”, “بس”, “كده”). The final ED stop‑word list contains roughly 1 200 items.
Experimental design
The sentiment‑analysis task is binary (positive vs. negative). A labeled subset of 5 000 sentences from the same corpus was created for evaluation. Two classic classifiers—Naïve Bayes (NB) and Decision Tree (DT)—were chosen to serve as baselines. Feature representations were built using both unigram and bigram models, each weighted by TF‑IDF. Four preprocessing conditions were tested: (1) removal of only the standard MSA stop‑word list, (2) removal of only the newly generated ED list, (3) removal of the union of both lists, and (4) no stop‑word removal (raw text). Ten‑fold cross‑validation was performed for each condition, and performance was measured with accuracy, precision, recall, and F1‑score.
Results
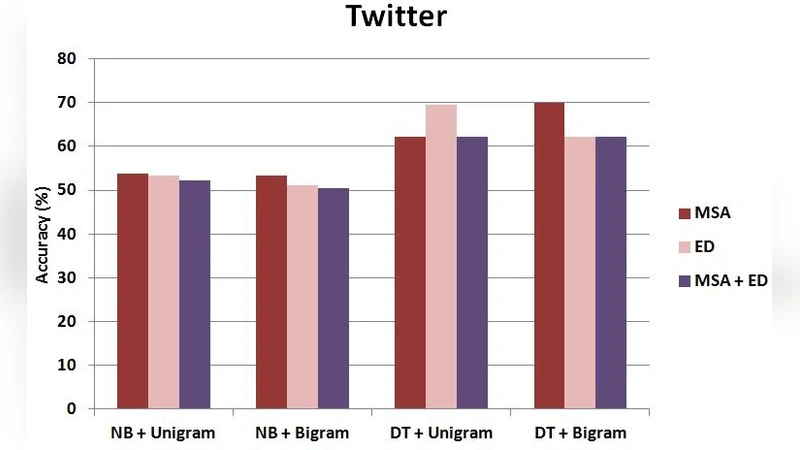
Across both classifiers and both feature sets, the condition that removed only the ED stop‑words consistently outperformed the others. With NB and unigram features, accuracy rose from 78.4 % (no stop‑words) to 81.6 % (+3.2 percentage points) when ED stop‑words were removed. DT showed a similar trend, with F1 improving from 0.71 to 0.74. Using only the MSA list sometimes degraded performance, indicating that many MSA stop‑words are not appropriate for dialectal text and may leave dialect‑specific noise untouched. The combined list (MSA + ED) yielded intermediate results, suggesting that an overly large stop‑word set can inadvertently discard useful content words. Bigram features offered only marginal gains, likely because dialectal expressions are short and less syntactically regular, reducing the utility of adjacent token pairs.
Discussion
The study demonstrates that dialect‑aware stop‑word removal is a simple yet effective preprocessing step for sentiment analysis on OSN data. The hybrid frequency/TF‑IDF pipeline, coupled with expert validation, produced a high‑quality list that can be replicated for other Arabic dialects or even for other languages with strong dialectal variation. Limitations include the focus on a single social platform ecosystem and the static nature of the stop‑word list, which may not capture emerging slang or region‑specific variants.
Future work
The authors propose extending the corpus to include other platforms (e.g., YouTube comments, forums) and incorporating metadata such as author age, gender, and geographic location to enable dynamic, context‑sensitive stop‑word updates. They also plan to test the ED list with modern deep‑learning classifiers (e.g., AraBERT, multilingual BERT) to assess whether the benefits persist in more powerful models. Finally, a cross‑dialect stop‑word repository could be built to support multilingual Arabic NLP pipelines.
In conclusion, the paper provides empirical evidence that a carefully crafted Egyptian Dialect stop‑word list improves sentiment‑analysis performance on real‑world social media text, highlighting the importance of dialect‑specific preprocessing in Arabic NLP research.