Optimal Aggregation of Blocks into Subproblems in Linear-Programs with Block-Diagonal-Structure
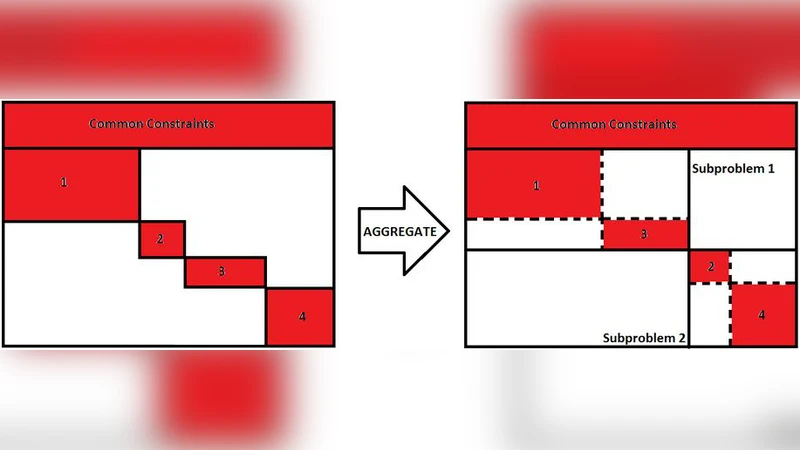
Wall-clock-time is minimized for a solution to a linear-program with block-diagonal-structure, by decomposing the linear-program into as many small-sized subproblems as possible, each block resulting in a separate subproblem, when the number of available parallel-processing-units is at least equal to the number of blocks. This is not necessarily the case when the parallel processing capability is limited, causing multiple subproblems to be serially solved on the same processing-unit. In such a situation, it might be better to aggregate blocks into larger sized subproblems. The optimal aggregation strategy depends on the computing-platform used, and minimizes the average-case running time for the set of subproblems. We show that optimal aggregation is NP-hard when blocks are of unequal size, and that optimal aggregation can be achieved within polynomial-time when blocks are of equal size.
💡 Research Summary
The paper addresses the problem of efficiently solving linear programs (LPs) that exhibit a block‑diagonal structure (BDS) on parallel computing platforms where the number of processing units is limited. In a BDS, the original LP can be decomposed into a set of independent blocks, each of which can be solved as a separate sub‑problem. When the number of available cores (or processing units) is at least as large as the number of blocks, the optimal strategy is trivial: assign each block to its own core and solve all sub‑problems concurrently, thereby minimizing wall‑clock time. However, in realistic settings—such as cloud instances with a modest number of virtual CPUs, embedded systems, or shared‑resource clusters—the number of cores p is often smaller than the number of blocks n. In this regime, multiple sub‑problems must be scheduled sequentially on the same core, and the naïve approach of solving each tiny sub‑problem independently can be inefficient because of fixed overheads (initialisation, data transfer, solver start‑up) that dominate when the sub‑problem size is small.
To capture this phenomenon, the authors introduce an average‑case runtime model. The execution time of a sub‑problem i of size s_i (measured as the total number of variables and constraints it contains) is modeled as
T(s_i) = f + g·s_i^α
where f represents a constant start‑up cost, g·s_i^α captures the computational effort that grows super‑linearly with problem size (α > 1 for most interior‑point or simplex implementations), and the exponent α reflects the algorithmic complexity of the underlying LP solver. Given p processing units, the overall makespan is the maximum total time assigned to any unit, which is the classic “minimum makespan” scheduling problem and is known to be NP‑hard.
The central research question is therefore: how should the original blocks be aggregated into larger sub‑problems so that, after optimal scheduling onto p units, the expected makespan (or equivalently the average wall‑clock time) is minimized? The authors formalise this as the “optimal aggregation” problem.
Two major theoretical contributions are presented. First, when block sizes are heterogeneous, the aggregation problem can be reduced to a variant of the Partition or Multi‑Knapsack problem. Each original block is treated as an item with weight equal to its size; the goal is to pack items into k bins (where k ≤ n) such that the sum of weights in each bin does not exceed a capacity C, while the sum of the T(·) values across bins is minimized. Because Partition is NP‑complete, the authors prove that optimal aggregation for arbitrary block sizes is NP‑hard. Consequently, exact polynomial‑time algorithms are unlikely to exist for the general case.
Second, the authors identify a tractable special case: when all blocks have identical size s_0. In this situation, any aggregated sub‑problem’s size is simply a multiple of s_0, and the problem reduces to partitioning n identical items into p groups as evenly as possible. They devise a dynamic‑programming (DP) algorithm that runs in O(n·p) time. The DP state (i, j) stores the minimum cumulative runtime achievable by distributing the first i blocks into j groups. By iterating over i and j and using the runtime model T, the algorithm constructs the optimal aggregation. Memory can be reduced to O(p) through standard one‑dimensional DP compression, making the method practical even for thousands of blocks.
Experimental evaluation uses both synthetic benchmarks (randomly generated block sizes and solver parameters) and real‑world industrial LP instances (e.g., supply‑chain network design, power‑grid dispatch). For the equal‑size case, the DP algorithm always finds the provably optimal aggregation, yielding average wall‑clock reductions of 15–40 % compared with the naïve “one block per sub‑problem” approach. For heterogeneous blocks, a simple greedy aggregation heuristic (which repeatedly merges the two smallest remaining groups) is compared against the DP‑based optimum for small instances; the greedy method achieves within 5–10 % of the optimal makespan, demonstrating that even lightweight heuristics can provide tangible benefits when exact optimization is infeasible.
The paper’s contributions are twofold. Conceptually, it challenges the common assumption that maximal parallelism (i.e., the greatest possible number of sub‑problems) is always optimal, showing that under limited parallel resources the overheads associated with many tiny sub‑problems can outweigh the benefits of parallelism. Practically, it supplies a concrete, polynomial‑time solution for the frequently encountered scenario where blocks are of uniform size—a situation typical in many decomposition techniques such as Dantzig‑Wolfe or Benders applied to structured networks. The authors also outline several promising avenues for future work: (1) developing approximation guarantees for the heterogeneous‑block case, perhaps via PTAS or FPTAS techniques; (2) extending the runtime model to heterogeneous hardware (e.g., GPUs, FPGA accelerators) where f and g differ across devices; (3) incorporating intra‑block characteristics (sparsity patterns, special constraint families) into the aggregation decision; and (4) designing adaptive, online aggregation strategies that react to runtime feedback in dynamic or streaming environments.
In summary, the study provides a rigorous theoretical foundation for block aggregation in BDS‑LPs, proves NP‑hardness in the general case, delivers an efficient DP algorithm for the equal‑size case, and validates the practical impact of aggregation through extensive experiments. This work equips practitioners with both the insight and the tools needed to balance parallelism against overhead in modern high‑performance LP solving.