Class Vectors: Embedding representation of Document Classes
Distributed representations of words and paragraphs as semantic embeddings in high dimensional data are used across a number of Natural Language Understanding tasks such as retrieval, translation, and classification. In this work, we propose “Class Vectors” - a framework for learning a vector per class in the same embedding space as the word and paragraph embeddings. Similarity between these class vectors and word vectors are used as features to classify a document to a class. In experiment on several sentiment analysis tasks such as Yelp reviews and Amazon electronic product reviews, class vectors have shown better or comparable results in classification while learning very meaningful class embeddings.
💡 Research Summary
The paper introduces “Class Vectors,” a novel framework that learns a dense vector representation for each document class in the same embedding space as word and paragraph vectors. By treating class labels as special tokens that co‑occur with every word in documents belonging to that class, the authors extend the standard skip‑gram objective with an additional term that maximizes the likelihood of class‑word pairs. This joint training yields class vectors that are semantically aligned with the most characteristic words of their respective classes.
Three inference strategies are explored. The first, called “CV Score,” aggregates the log‑probabilities of all words in a test document under each class’s soft‑max distribution and selects the class with the highest total score. The second, “CV‑LR,” computes, for each word, the difference between its log‑probability under the positive and negative class vectors; these differences form a feature vector that is fed to a logistic‑regression classifier. The third, “norm CV‑LR,” normalizes both class and word vectors and uses the raw inner‑product difference as features, eliminating the need for a soft‑max normalization step.
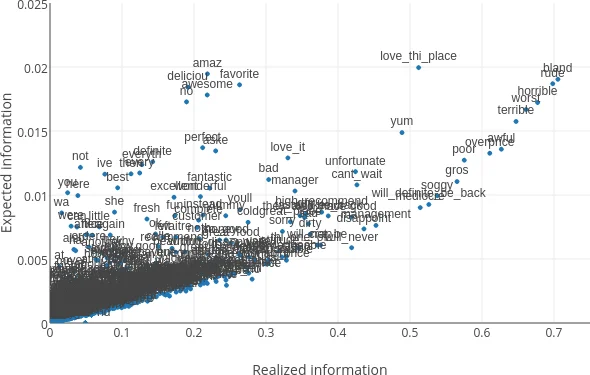
Beyond classification, the authors propose a feature‑selection scheme based on information theory. By interpreting the inner product between a class vector and a word vector as the conditional probability p(class | word), they compute conditional entropy and mutual information for each word. This approach highlights low‑frequency but highly discriminative words that traditional TF‑IDF weighting often overlooks.
Experiments are conducted on two large sentiment‑analysis corpora: Amazon electronic product reviews (≈196 K training examples, 25 K test) and Yelp restaurant reviews (≈154 K training, 20 K test). Both datasets are binary‑labeled (positive vs. negative) after mapping star ratings (1–2 → negative, 4–5 → positive). Pre‑processing includes lower‑casing, punctuation removal, and discarding words with frequency ≤ 5. Additionally, the authors extract salient multi‑word phrases using a method from Kumar et al. (2014) and annotate the corpora, which improves downstream performance.
Baseline and state‑of‑the‑art comparators include: traditional bag‑of‑words (binary, TF, IDF, TF‑IDF), Naïve Bayes followed by Logistic Regression (NB‑LR), a variant of word2vec (“W2V inversion”), Convolutional Neural Networks (CNN), and Paragraph Vectors (PV‑DBOW). All models are trained with comparable hyper‑parameters; the class‑vector system uses a window size of 10, 5 negative samples, a minimum word count of 5, and λ = 1 for the class‑word term.
Results show that on Yelp, the normalized class‑vector logistic regression (norm CV‑LR) attains the highest accuracy (94.91 %), closely followed by CV‑LR (94.83 %). On Amazon, the best overall method is bag‑of‑words with IDF weighting (93.98 %), but CV‑LR still achieves a competitive 91.70 % accuracy, outperforming Paragraph Vectors (90.07 %) and CNN (92.86 %). The authors also report that class vectors have high cosine similarity with prototypical sentiment words: positive class vectors align with “very very good,” “fantastic,” etc., while negative class vectors align with “awful,” “terrible,” etc., confirming that the vectors capture intuitive class semantics.
Ablation studies reveal that shuffling the entire corpus during training is crucial; learning class vectors on a per‑class subset degrades discriminative power, underscoring the importance of joint learning across all classes. Visualization of expected versus realized information (Figure 2) demonstrates that class‑vector based feature selection surfaces informative low‑frequency terms that TF‑IDF misses.
In conclusion, Class Vectors provide a lightweight yet powerful way to embed class semantics directly into the same space as word embeddings, enabling simple linear classifiers to achieve strong performance while offering interpretable class representations. The paper suggests several future directions: initializing class vectors with pre‑trained word embeddings for low‑resource settings, extending the approach to n‑gram embeddings via compositional models (e.g., recursive neural networks), and exploring generative models that condition on class vectors for tasks such as clustering or data augmentation.
Comments & Academic Discussion
Loading comments...
Leave a Comment