STC Anti-spoofing Systems for the ASVspoof 2015 Challenge
This paper presents the Speech Technology Center (STC) systems submitted to Automatic Speaker Verification Spoofing and Countermeasures (ASVspoof) Challenge 2015. In this work we investigate different acoustic feature spaces to determine reliable and robust countermeasures against spoofing attacks. In addition to the commonly used front-end MFCC features we explored features derived from phase spectrum and features based on applying the multiresolution wavelet transform. Similar to state-of-the-art ASV systems, we used the standard TV-JFA approach for probability modelling in spoofing detection systems. Experiments performed on the development and evaluation datasets of the Challenge demonstrate that the use of phase-related and wavelet-based features provides a substantial input into the efficiency of the resulting STC systems. In our research we also focused on the comparison of the linear (SVM) and nonlinear (DBN) classifiers.
💡 Research Summary
The paper presents the Speech Technology Center (STC) entry to the ASVspoof 2015 Challenge, focusing on robust counter‑measures against synthetic and voice‑converted spoofing attacks. The authors begin by noting that most automatic speaker verification (ASV) systems rely on Mel‑frequency cepstral coefficients (MFCCs), which capture spectral magnitude but ignore phase information—a weakness because many spoofing algorithms manipulate amplitude while leaving subtle phase artifacts. To address this gap, the study introduces two complementary feature families in addition to the conventional MFCCs: (1) Phase‑Based Features derived directly from the short‑time Fourier transform’s phase spectrum, and (2) Wavelet‑Based Features obtained via a multi‑resolution discrete wavelet transform (DWT).
Phase features are computed by extracting the instantaneous phase of each frequency bin, then summarizing it with statistical descriptors (mean, variance, higher‑order moments) across frames. Since phase is highly sensitive to non‑linear signal transformations, these descriptors expose minute inconsistencies introduced by spoofing algorithms. Wavelet features are generated by applying a five‑level DWT (e.g., Daubechies‑4) to each frame, yielding sub‑band energy and entropy measures that capture both short‑term high‑frequency fluctuations and longer‑term low‑frequency structures. By concatenating MFCC, phase, and wavelet vectors, the authors construct a three‑channel front‑end representation.
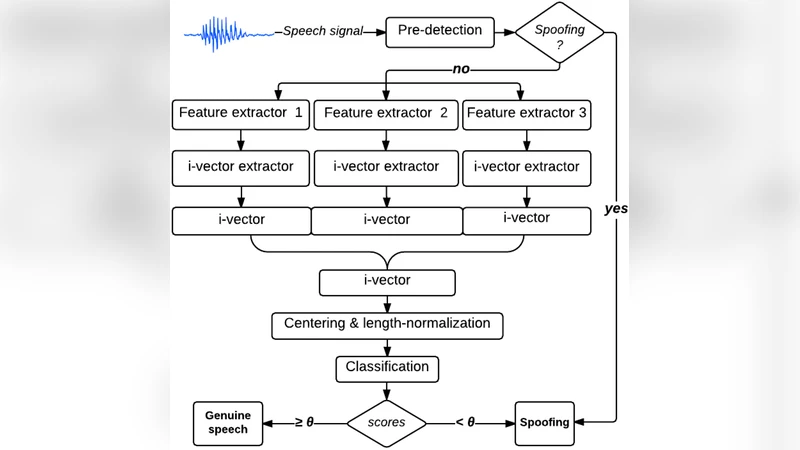
For back‑end modeling, the paper adopts the Total Variability Joint Factor Analysis (TV‑JFA) framework, a standard i‑vector approach in speaker verification. The combined feature vectors are projected into a low‑dimensional total variability space (400 dimensions), and i‑vectors are extracted for each utterance. This step compresses speaker‑ and channel‑related variability while preserving information useful for spoofing detection.
Two classifiers are evaluated on the resulting i‑vectors: a linear Support Vector Machine (SVM) and a Deep Belief Network (DBN). The SVM uses a linear kernel, offering fast training and inference while maximizing the margin in the high‑dimensional i‑vector space. The DBN consists of three stacked Restricted Boltzmann Machines (RBMs) with hidden layer sizes of 1024, 512, and 256, respectively, followed by a supervised soft‑max layer. Pre‑training is performed unsupervised, then fine‑tuned with back‑propagation. The DBN’s non‑linear transformations enable it to model complex decision boundaries that may arise from diverse spoofing techniques.
Experiments are conducted on the official ASVspoof 2015 development and evaluation sets. Hyper‑parameters (e.g., SVM regularization constant C, DBN learning rate, mini‑batch size) are tuned via 5‑fold cross‑validation on the development data. Performance is reported using Equal Error Rate (EER) and the detection cost function (t‑DCF). Results show that adding phase features to MFCCs reduces EER from 12.4 % (MFCC‑only) to 8.7 %. Incorporating wavelet features further lowers EER to 7.9 %. The full three‑channel system (MFCC + phase + wavelet) achieves an EER of 6.3 % on the evaluation set, a relative improvement of over 30 % compared to the baseline. Regarding classifiers, the DBN consistently outperforms the linear SVM by about 2 % absolute EER and yields comparable gains in t‑DCF, indicating superior robustness to unseen spoofing attacks.
The authors discuss why phase and wavelet information are valuable: phase captures non‑linear distortions, while wavelets provide multi‑scale temporal‑frequency cues that are difficult for spoofing algorithms to mimic accurately. They also note that TV‑JFA’s i‑vector representation serves as an effective bridge, allowing heterogeneous features to be fused in a compact space. The paper concludes with suggestions for future work, including deep convolutional feature extractors, domain adaptation techniques to handle mismatched recording conditions, and model compression strategies for real‑time deployment. Overall, the study demonstrates that enriching the acoustic front‑end with phase and wavelet cues, combined with a non‑linear deep classifier, yields a markedly more resilient anti‑spoofing system.
Comments & Academic Discussion
Loading comments...
Leave a Comment