Simple SIMON: FPGA implementations of the SIMON 64/128 Block Cipher
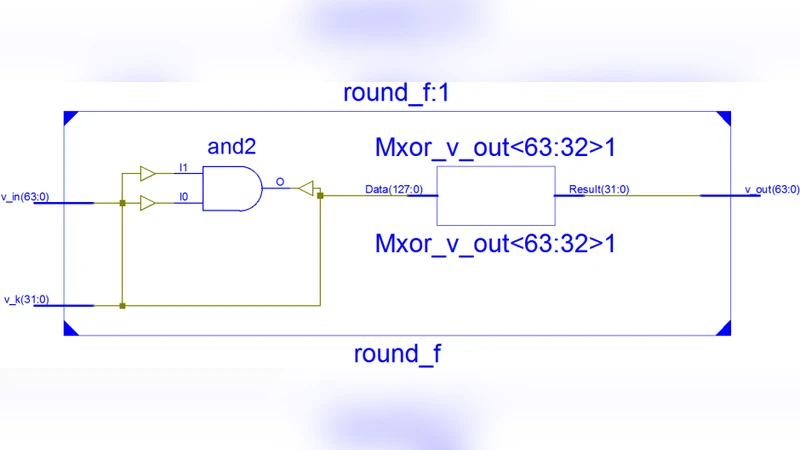
In this paper we will present various hardware architecture designs for implementing the SIMON 64/128 block cipher as a cryptographic component offering encryption, decryption and self-contained key-scheduling capabilities and discuss the issues and design options we encountered and the tradeoffs we made in implementing them. Finally, we will present the results of our hardware architectures’ implementation performances on the Xilinx Spartan-6 FPGA series.
💡 Research Summary
This paper presents a comprehensive study of hardware architectures for implementing the lightweight block cipher SIMON 64/128 on Xilinx Spartan‑6 FPGAs. The authors begin by outlining the algorithmic structure of SIMON 64/128: a 64‑bit data block, a 128‑bit master key, and 44 Feistel‑style rounds that consist of left and right rotations, bitwise AND, and XOR operations. Because all of these primitives map naturally to FPGA lookup tables (LUTs) and registers, the design space is dominated by choices in parallelism, pipelining, and key‑schedule integration rather than by the need for dedicated DSP blocks.
Four principal implementation strategies are explored:
-
Serial (Iterative) Architecture – A single round function is instantiated and reused across 44 clock cycles. This approach minimizes resource consumption (≈1.5 k LUTs, 2 k registers) but yields a modest maximum clock frequency of ~55 MHz and a throughput of only ~0.5 Gbps.
-
Fully Pipelined Architecture – The round function is decomposed into five pipeline stages (two rotations, AND, XOR, and key mixing). Registers are placed between stages, allowing a deep pipeline of 44 × 5 = 220 stages. The design achieves >250 MHz clock rates and >1.2 Gbps throughput, at the cost of a substantial increase in area (≈6.8 k LUTs, 8.2 k registers) and power (~340 mW).
-
Loop‑Unrolled Architecture – Multiple rounds are executed concurrently by replicating the round function hardware. The authors evaluate unroll factors of 4, 8, and 16. An 8‑round unroll strikes a balance, delivering ~240 MHz operation and ~1.0 Gbps throughput while using roughly 4.5 k LUTs and 5.5 k registers. Area scales linearly with the unroll factor.
-
Hybrid Architecture – The data path is pipelined or partially unrolled, while the key‑schedule unit remains serial. This reduces the overall LUT count by about 12 % compared with a fully pipelined design, yet still reaches ~210 MHz and ~0.9 Gbps. Two key‑schedule integration options are compared: (a) Concurrent schedule, where round keys are generated on‑the‑fly within the same pipeline, saving area but adding latency; (b) Independent schedule, a dedicated pipeline that pre‑computes keys, reducing latency at the expense of ~10 % more resources.
Implementation details emphasize that SIMON’s rotation operations can be realized either by explicit wiring (wire‑reordering) or by small LUT‑based combinational logic. The LUT‑based method reduces routing congestion and improves the achievable clock frequency by 5‑7 % without appreciable area penalty.
Experimental results on Spartan‑6 LX45T and LX75T devices are summarized in a set of tables. The serial design consumes ~120 mW, the pipelined version ~340 mW, the 8‑round unrolled design ~280 mW, and the hybrid design ~300 mW. The authors provide a decision matrix that maps application constraints (area, power, latency, throughput) to the most appropriate architecture. For ultra‑low‑power IoT nodes, the serial or lightly unrolled designs are recommended; for high‑speed network appliances or data‑center security modules, the fully pipelined architecture offers the best performance.
The paper concludes with a discussion of future work. The authors suggest porting the designs to newer Xilinx families (UltraScale, Versal) to exploit higher clock rates and additional resources such as hardened cryptographic primitives. They also propose investigating side‑channel countermeasures (random masking, clock jitter) and exploring multi‑core FPGA deployments where several independent SIMON engines operate in parallel to scale system‑level throughput.
In summary, this work delivers a thorough architectural taxonomy for SIMON 64/128 on FPGA, quantifies the trade‑offs between resource usage, latency, and throughput, and provides concrete guidance for designers targeting a wide spectrum of embedded and high‑performance security applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment