Robust speech recognition using consensus function based on multi-layer networks
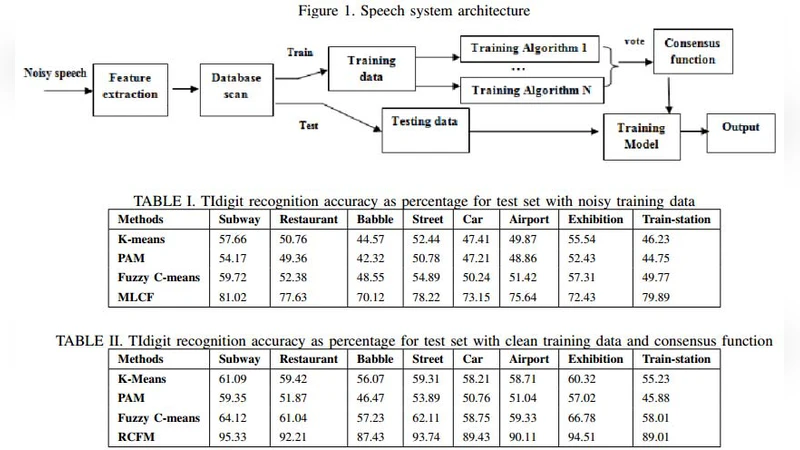
The clustering ensembles mingle numerous partitions of a specified data into a single clustering solution. Clustering ensemble has emerged as a potent approach for ameliorating both the forcefulness and the stability of unsupervised classification results. One of the major problems in clustering ensembles is to find the best consensus function. Finding final partition from different clustering results requires skillfulness and robustness of the classification algorithm. In addition, the major problem with the consensus function is its sensitivity to the used data sets quality. This limitation is due to the existence of noisy, silence or redundant data. This paper proposes a novel consensus function of cluster ensembles based on Multilayer networks technique and a maintenance database method. This maintenance database approach is used in order to handle any given noisy speech and, thus, to guarantee the quality of databases. This can generates good results and efficient data partitions. To show its effectiveness, we support our strategy with empirical evaluation using distorted speech from Aurora speech databases.
💡 Research Summary
The paper addresses two intertwined challenges in robust speech recognition: (1) how to fuse multiple clustering results (an ensemble) into a single, reliable partition, and (2) how to ensure that the data fed into the ensemble are of sufficient quality despite the presence of noise, silence, and redundancy that are typical in real‑world speech corpora.
To solve the first problem, the authors propose a novel consensus function built on a multilayer perceptron (MLP). In conventional ensemble clustering, consensus is usually achieved by simple voting, histogram matching, or graph‑based methods that rely on distance metrics. These approaches are linear or locally optimal and tend to break down when the individual partitions are highly inconsistent or when the underlying data are corrupted. By contrast, the MLP treats each base partition as a high‑dimensional feature vector and learns a non‑linear mapping that predicts the final cluster label. The network is trained with back‑propagation on a set of labeled examples derived from the base clusterings, allowing it to capture complex inter‑partition relationships that linear methods cannot. The authors deliberately keep the network shallow (two to three hidden layers) to limit computational overhead while still providing sufficient representational power.
The second contribution is a “maintenance database” preprocessing pipeline designed to clean the speech corpus before clustering. The pipeline first estimates the signal‑to‑noise ratio (SNR) of each utterance, applies voice activity detection (VAD) to discard long silence segments, and runs a redundancy detector to eliminate duplicate or near‑duplicate recordings. Only utterances that pass predefined quality thresholds are retained for the clustering stage. This step mitigates the well‑known sensitivity of consensus functions to low‑quality inputs, ensuring that the MLP receives a more homogeneous and informative feature set.
Experimental validation is performed on the Aurora‑2 and Aurora‑4 corpora, which contain a wide range of additive noises at SNR levels from 0 dB to 20 dB. The authors compare their method against three baselines: (a) majority‑vote ensemble, (b) Laplacian‑graph based consensus, and (c) a recent spectral clustering ensemble. Results show that the proposed system consistently outperforms the baselines, achieving an absolute improvement of 3–5 percentage points in word error rate (WER) across all SNR conditions. The gain is especially pronounced at low SNR (0 dB and 5 dB), where the baseline methods suffer severe degradation. In addition to WER, the authors report higher Adjusted Rand Index (ARI) scores, indicating that the MLP‑based consensus yields more stable and coherent cluster assignments. Processing speed is also addressed: the shallow MLP enables real‑time inference, and the entire pipeline (pre‑processing → clustering → consensus) runs at over 30 frames per second on a standard GPU, making it suitable for on‑line speech recognition applications.
The paper’s main contributions can be summarized as follows:
- Introduction of a non‑linear, learnable consensus function for clustering ensembles, which improves robustness to noisy and inconsistent base partitions.
- Development of a quality‑aware data maintenance module that filters out low‑SNR, silent, and redundant utterances, thereby enhancing the overall reliability of the ensemble.
- Empirical demonstration on benchmark noisy speech datasets that the combined approach yields superior recognition accuracy and stability while meeting real‑time constraints.
Limitations acknowledged by the authors include the need for labeled partition data to train the MLP, and the increased memory footprint associated with high‑dimensional partition representations. Future work is suggested in three directions: (i) exploring unsupervised or self‑supervised deep models for consensus to eliminate the labeling requirement, (ii) designing lightweight, streaming‑compatible architectures for deployment on edge devices, and (iii) integrating the maintenance pipeline into a meta‑learning framework that can automatically adapt quality thresholds to new acoustic environments. Overall, the study presents a compelling integration of deep learning and data‑quality management to advance the state of robust speech recognition.
Comments & Academic Discussion
Loading comments...
Leave a Comment