Random mappings designed for commercial search engines
We give a practical random mapping that takes any set of documents represented as vectors in Euclidean space and then maps them to a sparse subset of the Hamming cube while retaining ordering of inter-vector inner products. Once represented in the sparse space, it is natural to index documents using commercial text-based search engines which are specialized to take advantage of this sparse and discrete structure for large-scale document retrieval. We give a theoretical analysis of the mapping scheme, characterizing exact asymptotic behavior and also giving non-asymptotic bounds which we verify through numerical simulations. We balance the theoretical treatment with several practical considerations; these allow substantial speed up of the method. We further illustrate the use of this method on search over two real data sets: a corpus of images represented by their color histograms, and a corpus of daily stock market index values.
💡 Research Summary
The paper proposes a practical random mapping that converts any collection of high‑dimensional Euclidean vectors into a sparse binary representation suitable for commercial text‑based search engines. The authors observe that while text documents naturally fit the “bag‑of‑words” model—high‑dimensional, sparse, integer vectors—many important data types such as images, video, audio, biometric measurements, and bio‑informatic profiles are expressed as dense real‑valued vectors. Existing large‑scale search infrastructures (e.g., Elasticsearch, Solr) are heavily optimized for the sparse, discrete structure of text data, but they cannot be directly applied to dense Euclidean vectors.
Mapping scheme.
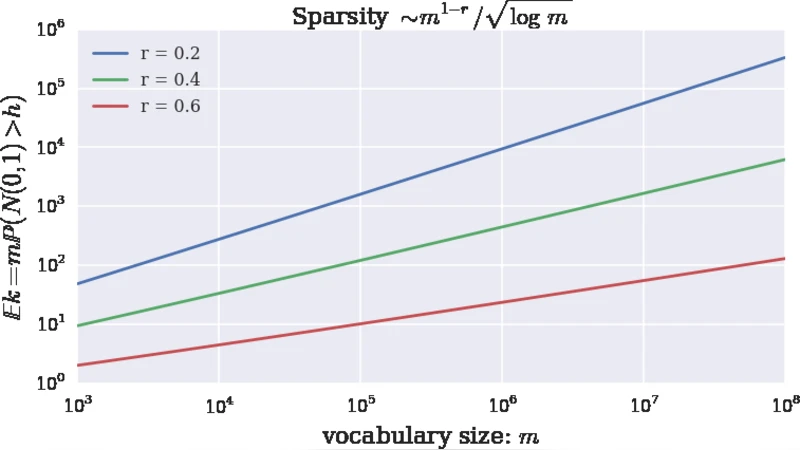
Given a corpus X ⊂ S^{d‑1} (the unit sphere in ℝ^d), the method draws m independent standard‑normal vectors a_1,…,a_m ∈ ℝ^d. For a chosen threshold h>0, each document x∈X is transformed to a binary vector b(x)∈{0,1}^m via
b_i(x)=1_{⟨a_i,x⟩≥h}, i=1,…,m.
The threshold is parameterized as h(m,r)=√{2r log m} with a sparsity parameter r∈(0,1). Because ⟨a_i,x⟩∼N(0,1), the probability of a “1” in any coordinate is P(N≥h)≈e^{−h²/2}/(h√{2π})≈m^{−r}/√{4πr log m}. Consequently the expected number of non‑zero entries is E
Comments & Academic Discussion
Loading comments...
Leave a Comment