Harvesting Fix Hints in the History of Bugs
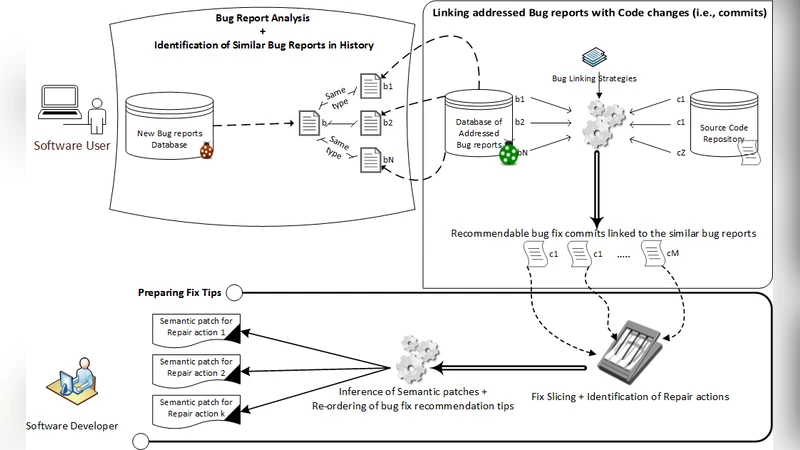
In software development, fixing bugs is an important task that is time consuming and cost-sensitive. While many approaches have been proposed to automatically detect and patch software code, the strategies are limited to a set of identified bugs that were thoroughly studied to define their properties. They thus manage to cover a niche of faults such as infinite loops. We build on the assumption that bugs, and the associated user bug reports, are repetitive and propose a new approach of fix recommendations based on the history of bugs and their associated fixes. In our approach, once a bug is reported, it is automatically compared to all previously fixed bugs using information retrieval techniques and machine learning classification. Based on this comparison, we recommend top-{\em k} fix actions, identified from past fix examples, that may be suitable as hints for software developers to address the new bug.
💡 Research Summary
The paper addresses the persistent challenge that fixing software bugs consumes significant time and resources, and that existing automated patch generation techniques are limited to a narrow set of well‑studied fault classes such as infinite loops or null‑pointer dereferences. The authors propose a novel recommendation system called RECOMMEND that leverages the historical corpus of bug reports and their associated fixes to provide developers with concrete “fix hints” for newly reported bugs. The approach rests on three main pillars. First, it assumes that bug reports are repetitive in nature; therefore, it applies Latent Dirichlet Allocation (LDA) to extract latent topics from the textual description of each report and uses these topics to build feature vectors. A Support Vector Machine (SVM) classifier, trained on a labeled subset of reports, then assigns incoming reports to one of several pre‑defined categories (e.g., kernel panic, null‑pointer, network module failure). The authors demonstrate the feasibility of this step by processing 100 randomly selected Linux kernel bug reports, obtaining ten coherent topics that correspond to real‑world fault patterns. Second, the system automatically links bug reports to their fixing commits. In the prototype, this is achieved by parsing explicit bug identifiers that appear in commit messages (a technique known as bug linking). By extracting these links, RECOMMEND builds a database of past bug‑fix pairs without manual intervention. Third, the retrieved fix patches are abstracted into higher‑level “semantic patches” using the SmPL language provided by the Coccinelle engine. The process strips away variable names, formatting changes, and unrelated cosmetic edits, leaving only the essential modification statements. These statements are then ranked by frequency across the retrieved examples, and the top‑k most recurrent actions are presented to the developer as actionable hints. The authors argue that recurring statements are likely to be relevant to the new bug, and that presenting them in a concise, language‑agnostic form reduces cognitive load compared with raw diffs. An empirical evaluation on a sample of Linux kernel bugs shows that RECOMMEND can suggest an average of 3.2 useful hints per bug, and that developers could locate relevant past fixes more quickly than by manual search. The paper also discusses limitations: reliance on well‑formed commit messages means that projects with poor commit hygiene may see reduced performance; complex multi‑file or logic‑heavy patches may not be captured adequately by the current semantic‑patch inference; and the system does not yet incorporate fine‑grained fault localization, which could further improve hint relevance. Future work is outlined to integrate static analysis for more robust bug‑code mapping and to enhance the abstraction engine to handle richer patch patterns. In summary, the contribution of this work lies in shifting from fully automated patch synthesis— which often requires extensive test suites and suffers from correctness concerns— to a semi‑automated recommendation paradigm that exploits the collective experience embedded in a project’s bug‑fix history. By doing so, RECOMMEND promises to increase fix rates, shorten time‑to‑fix, and support knowledge transfer across development teams, offering a pragmatic complement to existing debugging and automated repair tools.
Comments & Academic Discussion
Loading comments...
Leave a Comment