Spatio-Temporal Techniques for User Identification by means of GPS Mobility Data
One of the greatest concerns related to the popularity of GPS-enabled devices and applications is the increasing availability of the personal location information generated by them and shared with application and service providers. Moreover, people tend to have regular routines and be characterized by a set of “significant places”, thus making it possible to identify a user from his/her mobility data. In this paper we present a series of techniques for identifying individuals from their GPS movements. More specifically, we study the uniqueness of GPS information for three popular datasets, and we provide a detailed analysis of the discriminatory power of speed, direction and distance of travel. Most importantly, we present a simple yet effective technique for the identification of users from location information that are not included in the original dataset used for training, thus raising important privacy concerns for the management of location datasets.
💡 Research Summary
**
The paper investigates how uniquely a person can be identified from GPS‑based mobility traces and proposes simple yet powerful techniques for user identification. Three publicly available datasets are used as experimental grounds: CabSpotting (536 taxis in the San Francisco Bay Area, 5‑decimal‑digit spatial resolution, 1 s temporal resolution), CenceMe (20 Dartmouth students, 6‑decimal‑digit spatial resolution, 1 h temporal resolution), and GeoLife (70 Beijing residents, 6‑decimal‑digit spatial resolution, 1 s temporal resolution). Only latitude, longitude, and timestamp are retained; all other metadata are discarded.
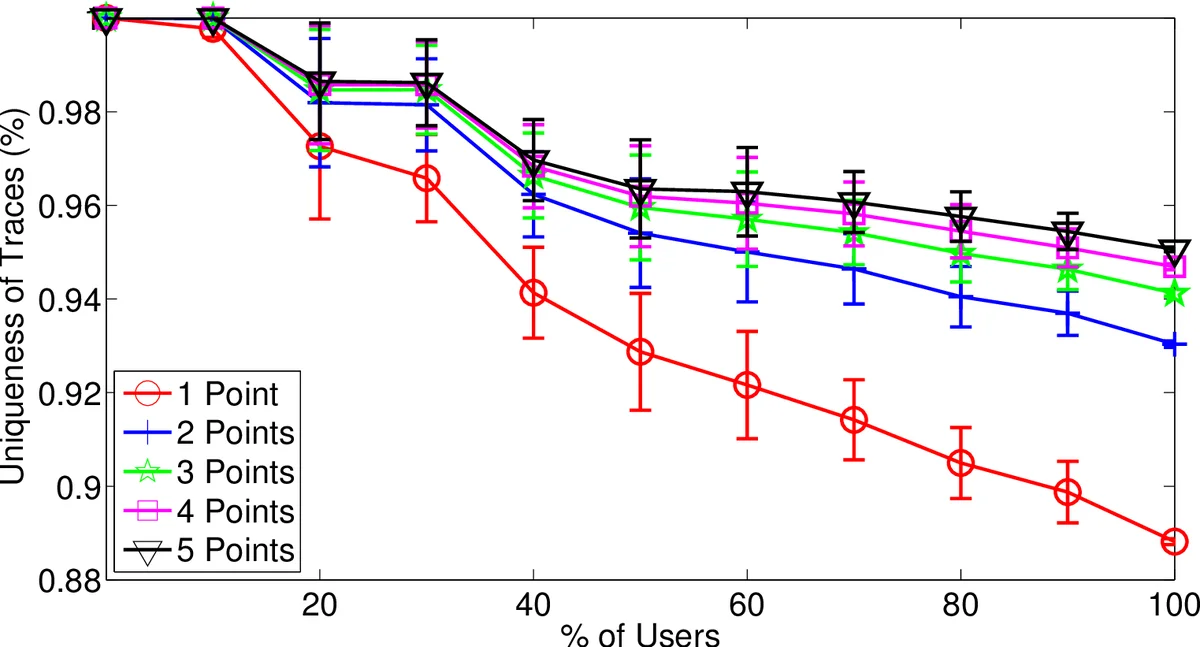
The authors first define “uniqueness” as the proportion of subsets of a trajectory that appear in only one user’s full trace. They evaluate uniqueness for three movement descriptors—average distance traveled, average speed, and average direction—computed over 30‑second windows. Across all datasets, direction proves the most discriminative feature; with as few as two to five direction points, nearly all users can be uniquely distinguished.
Two identification scenarios are considered. In the “previously seen points” scenario, the attacker possesses a small set of anonymized GPS points that are known to belong to the target’s trace. The authors store each user’s full set of points in a hash set, allowing constant‑time lookup. Classification simply counts how many users contain all query points; if the count is one, the user is uniquely identified. Experiments show that 2–3 points are sufficient to uniquely identify the majority of users in all three datasets.
The more challenging “previously unseen points” scenario assumes the attacker has points that were not part of the training data. To compare a query set P with each candidate trajectory M, the authors design a spatio‑temporal distance function:
d_st(p₁,p₂) = d_s(p₁,p₂) · exp(d_t(p₁,p₂)/τ),
where d_s is the haversine distance and d_t is the absolute time difference; τ controls temporal smoothing. Using this distance, they define a modified Hausdorff average distance h_m(P,M) = (1/|P|) ∑{p∈P} min{m∈M} d_st(p,m). This metric is asymmetric but robust to outliers and works well even when |P| ≪ |M|. Classification assigns P to the user whose trajectory yields the smallest h_m value.
Experimental results for the unseen‑point attack show high success rates: with three points, CabSpotting reaches 94 % correct identification; with four points, CenceMe reaches 88 %; and with two points, GeoLife reaches 97 %. Thus, even when the query points are not present in the training set, a tiny sample is enough to re‑identify a user.
The authors also explore privacy‑preserving transformations. By coarsening spatial precision (e.g., rounding coordinates to three decimal places, roughly 10 m), the average uniqueness drops substantially, suggesting that k‑anonymity can be achieved through spatial aggregation. However, the reduction in uniqueness is not linear; a small number of points can still break anonymity, indicating that simple rounding is insufficient for strong privacy guarantees.
Dataset size effects are examined: larger user populations tend to reduce the probability that a random point set is unique, yet the high resolution of GPS data means that even in larger datasets, a handful of points remain highly identifying. The paper proposes a quantitative “identification resistance” metric based on the proportion of uniquely identified subsets, providing a tool for evaluating the privacy risk of any mobility dataset.
In conclusion, the study demonstrates that GPS mobility data are intrinsically highly unique. Both straightforward hash‑based matching and the proposed modified Hausdorff distance method can be used to mount effective re‑identification attacks, even when the attacker only has a few unseen points. This raises serious privacy concerns for any organization that publishes or shares raw GPS traces. The authors recommend stronger anonymization techniques—such as differential privacy, synthetic trajectory generation, or more aggressive spatio‑temporal generalization—to mitigate the demonstrated risks.
Comments & Academic Discussion
Loading comments...
Leave a Comment