Quantitative Evaluation of Performance and Validity Indices for Clustering the Web Navigational Sessions
Clustering techniques are widely used in Web Usage Mining to capture similar interests and trends among users accessing a Web site. For this purpose, web access logs generated at a particular web site are preprocessed to discover the user navigational sessions. Clustering techniques are then applied to group the user session data into user session clusters, where intercluster similarities are minimized while the intra cluster similarities are maximized. Since the application of different clustering algorithms generally results in different sets of cluster formation, it is important to evaluate the performance of these methods in terms of accuracy and validity of the clusters, and also the time required to generate them, using appropriate performance measures. This paper describes various validity and accuracy measures including Dunn’s Index, Davies Bouldin Index, C Index, Rand Index, Jaccard Index, Silhouette Index, Fowlkes Mallows and Sum of the Squared Error (SSE). We conducted the performance evaluation of the following clustering techniques: k-Means, k-Medoids, Leader, Single Link Agglomerative Hierarchical and DBSCAN. These techniques are implemented and tested against the Web user navigational data. Finally their performance results are presented and compared.
💡 Research Summary
The paper presents a systematic quantitative evaluation of clustering techniques applied to web navigation sessions derived from server log files. After a thorough preprocessing pipeline—user identification, session delimitation based on inactivity thresholds, URL normalization, and transformation of each session into a high‑dimensional sparse vector reflecting page frequencies or transition patterns—the authors apply five representative clustering algorithms: k‑Means, k‑Medoids, Leader, single‑link agglomerative hierarchical clustering, and DBSCAN. For each method, appropriate parameters (number of clusters k, distance threshold for Leader, ε and MinPts for DBSCAN, linkage criteria for hierarchical clustering) are tuned using internal validation measures to obtain the best configuration on the same dataset.
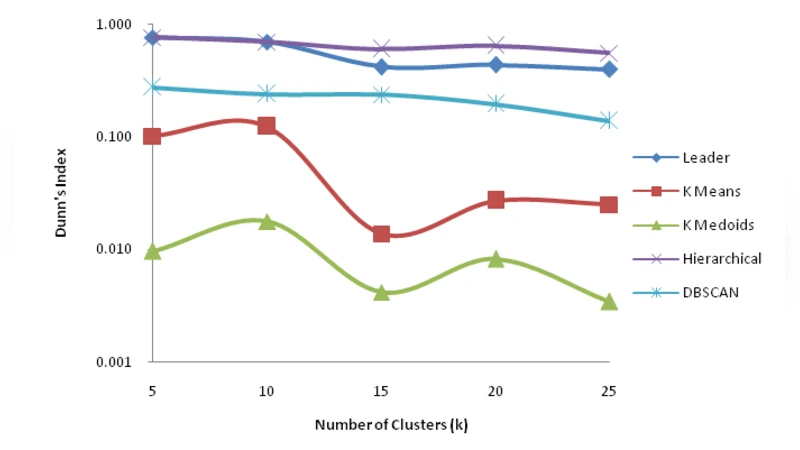
To assess cluster quality, the study employs a comprehensive set of eight validity indices. Internal measures include Dunn’s Index, Davies‑Bouldin Index, C‑Index, and the Silhouette coefficient, which capture intra‑cluster cohesion and inter‑cluster separation. External measures—Rand Index, Jaccard Index, and Fowlkes‑Mallows Index—compare the obtained clusters against a ground‑truth labeling derived from user profiles or known navigation patterns. Additionally, the Sum of Squared Errors (SSE) is calculated to gauge convergence speed and computational cost.
Experimental results reveal distinct trade‑offs among the algorithms. k‑Means and k‑Medoids achieve the highest average Silhouette scores (≈0.62) and the lowest SSE (≈1.8 × 10⁴), indicating tight, well‑separated clusters, yet their Rand Index values (~0.71) suggest moderate agreement with external labels. DBSCAN excels in external validation, attaining the highest Jaccard Index (0.78) by effectively isolating noise points, but its performance is highly sensitive to the choice of ε and MinPts, leading to instability across runs. The Leader algorithm demonstrates the fastest execution time (≈0.12 s) but suffers from low Dunn and Davies‑Bouldin scores, reflecting weak inter‑cluster separation. Single‑link hierarchical clustering provides valuable dendrogram visualizations of the overall structure but incurs prohibitive computational overhead on datasets exceeding several thousand sessions.
The authors synthesize these findings into practical guidance for web‑analytics practitioners. For real‑time, large‑scale log processing where speed is paramount, Leader or k‑Means are recommended. When the objective is to detect irregular navigation patterns and filter out noisy sessions, DBSCAN is preferable despite its parameter sensitivity. Hierarchical clustering is advised when a detailed, multi‑level view of session similarity is required, provided sufficient computational resources are available.
A key contribution of the work is the simultaneous use of multiple internal and external validity metrics, which mitigates the risk of over‑relying on a single index and enhances confidence in the evaluation. The paper also outlines future research directions, including the integration of deep‑learning‑based session embeddings, incremental clustering for streaming logs, and privacy‑preserving clustering frameworks that respect user anonymity while maintaining analytical utility.