Logical Concurrency Control from Sequential Proofs
We are interested in identifying and enforcing the isolation requirements of a concurrent program, i.e., concurrency control that ensures that the program meets its specification. The thesis of this paper is that this can be done systematically starting from a sequential proof, i.e., a proof of correctness of the program in the absence of concurrent interleavings. We illustrate our thesis by presenting a solution to the problem of making a sequential library thread-safe for concurrent clients. We consider a sequential library annotated with assertions along with a proof that these assertions hold in a sequential execution. We show how we can use the proof to derive concurrency control that ensures that any execution of the library methods, when invoked by concurrent clients, satisfies the same assertions. We also present an extension to guarantee that the library methods are linearizable or atomic.
💡 Research Summary
**
The paper tackles the fundamental problem of determining and enforcing the isolation requirements of a concurrent program. Its central thesis is that the necessary concurrency control can be derived systematically from a proof of correctness for the program in a purely sequential setting. To demonstrate this, the authors focus on the concrete scenario of converting a sequential library—one that is correct when used by a single thread—into a thread‑safe version that can be safely invoked by multiple concurrent clients.
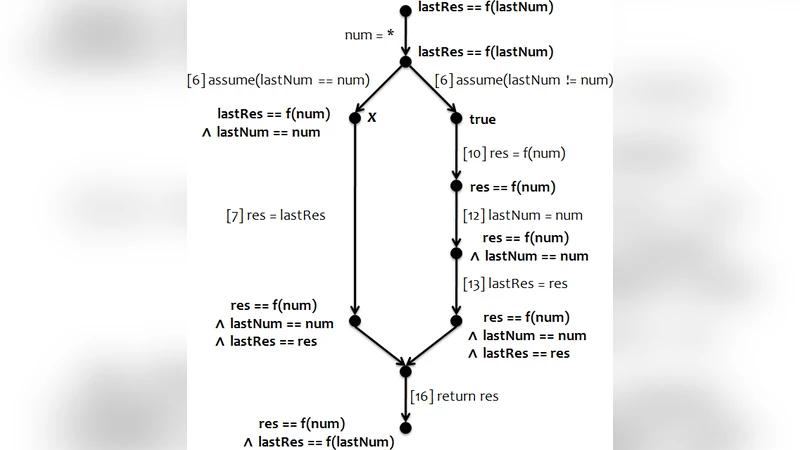
The authors formalize a library as a set of procedures, each represented by a control‑flow graph (CFG) with a unique entry and exit node, together with a set of global variables. A sequential proof is assumed to be available: for every node u in the CFG an invariant μ(u) is attached, expressing the logical condition that must hold whenever execution reaches u in order for all assertions in the library to be satisfied. The invariant can be viewed as a conjunction of elementary predicates; the collection of predicates required at u is denoted pm(u).
From these invariants the authors construct a locking scheme. The key observations are:
- State requirements are local – a thread at node u only needs the predicates in pm(u) to be true; any other thread may freely modify the rest of the state.
- Interference is logical, not merely data‑centric – a statement s executed by another thread is dangerous for the current thread only if s can falsify a predicate that the current thread requires at its current node.
- Locks correspond to predicates – for each predicate p a lock ℓₚ is introduced. When a thread reaches a node where p becomes required (i.e., p ∈ pm(v) \ pm(u) for an edge u→v) it acquires ℓₚ before executing the edge; when p ceases to be required (i.e., p ∈ pm(u) \ pm(v)) it releases ℓₚ after the edge.
- Statement‑level protection – if a particular statement can invalidate a predicate p that is required somewhere else, the algorithm inserts acquire(ℓₚ) before the statement and release(ℓₚ) after it, unless the predicate is already held at the statement’s source or destination node.
- Procedure entry/exit handling – at procedure entry the thread acquires all locks for pm(entry); at exit it releases all locks for pm(exit). This guarantees that the whole call respects the required logical state.
- Deadlock avoidance – the algorithm analyses the lock acquisition order induced by the CFG and merges locks when a potential cycle is detected, thus guaranteeing a deadlock‑free schedule.
- Optimisation – redundant locks are eliminated (e.g., when ℓ₁ always implies ℓ₂) and unnecessary acquisitions are removed when static analysis shows that two statements cannot be interleaved.
The authors implement the technique by feeding an existing software model checker (such as Boogie) with the sequential library to obtain the invariants automatically. The locking synthesis algorithm then produces a version of the library with lock statements inserted as comments in the source code. They evaluate the approach on several small examples, including a cache‑like procedure Compute that memoises the result of an expensive function f. In the original sequential code, a race condition could cause a thread to return a stale value after another thread overwrites the cached result. The synthesized locking scheme inserts locks only around the critical updates of the cache, allowing multiple threads to evaluate f concurrently while preserving the specification return f(num). The generated code matches what an expert programmer would write.
In the second part of the paper the authors extend the method to guarantee linearizability. Linearizability requires that each concurrent method call appear to take effect atomically at some point during its execution. To achieve this, the authors annotate each method with a linearization point and ensure that the lock set required at that point is held throughout the method’s execution. By doing so, the concurrent execution of the library appears indistinguishable from some sequential execution that respects the original specification.
The paper’s contributions can be summarised as follows:
- A systematic technique for extracting logical interference information from a sequential proof.
- An algorithm that translates this information into a minimal, deadlock‑free lock‑based concurrency control.
- An extension that upgrades the safety guarantee from simple assertion preservation to full linearizability.
- An implementation that demonstrates the practicality of the approach on realistic library examples.
- A conceptual shift from data‑centric interference (read/write conflicts) to logical‑centric interference, enabling more permissive yet safe concurrency.
Overall, the work shows that once a sequential correctness proof is available, the same logical reasoning can be repurposed to synthesize correct concurrent implementations automatically. This bridges the gap between sequential verification and concurrent programming, offering a promising path for building thread‑safe libraries without hand‑crafted synchronization code.
Comments & Academic Discussion
Loading comments...
Leave a Comment