Efficient Learning for Undirected Topic Models
Replicated Softmax model, a well-known undirected topic model, is powerful in extracting semantic representations of documents. Traditional learning strategies such as Contrastive Divergence are very inefficient. This paper provides a novel estimator to speed up the learning based on Noise Contrastive Estimate, extended for documents of variant lengths and weighted inputs. Experiments on two benchmarks show that the new estimator achieves great learning efficiency and high accuracy on document retrieval and classification.
💡 Research Summary
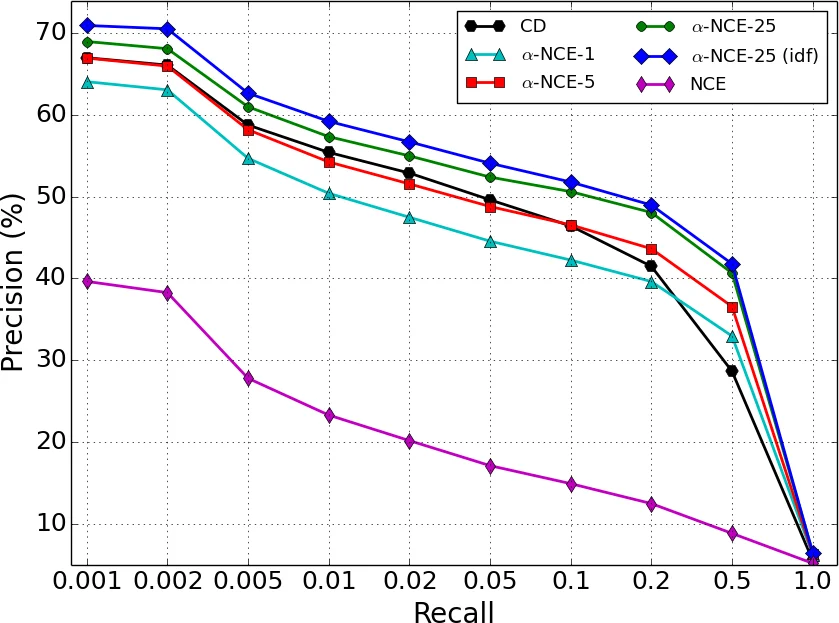
The paper tackles the long‑standing inefficiency of training the Replicated Softmax Model (RSM), a popular undirected topic model that represents documents as bag‑of‑words with softmax visible units and binary hidden units. Traditional learning methods such as Contrastive Divergence (CD) are ill‑suited for RSM because each Gibbs step requires multinomial sampling over a vocabulary that can easily reach tens of thousands of words, leading to prohibitive linear‑time costs per iteration. To overcome this bottleneck, the authors propose a novel estimator called α‑NCE (Partial Noise Uniform Contrastive Estimate), which builds on Noise Contrastive Estimation (NCE) but adapts it to the specific challenges of document‑level modeling.
The core ideas are twofold. First, they introduce Partial Noise Sampling (PNS), a document‑level noise generation scheme. For a document of length D, a fraction α (0 < α < 1) of the words is kept unchanged (the “retained” set), while the remaining D − αD words are replaced by samples drawn from the empirical unigram distribution ˜p. This creates noise documents that are neither completely random nor identical to the data, satisfying the NCE recommendation that the noise distribution be close to the data for effective learning. Because ˜p is fixed, the sampling can be performed efficiently using the alias method, and the resulting noise log‑probabilities can be computed analytically, avoiding the costly Gibbs steps required by CD.
Second, the authors address the variable‑length nature of documents by proposing Uniform Contrastive Estimate (UCE). Standard NCE computes a log‑ratio X(V)=log
Comments & Academic Discussion
Loading comments...
Leave a Comment