Oblivion: Mitigating Privacy Leaks by Controlling the Discoverability of Online Information
Search engines are the prevalently used tools to collect information about individuals on the Internet. Search results typically comprise a variety of sources that contain personal information – either intentionally released by the person herself, or unintentionally leaked or published by third parties, often with detrimental effects on the individual’s privacy. To grant individuals the ability to regain control over their disseminated personal information, the European Court of Justice recently ruled that EU citizens have a right to be forgotten in the sense that indexing systems, must offer them technical means to request removal of links from search results that point to sources violating their data protection rights. As of now, these technical means consist of a web form that requires a user to manually identify all relevant links upfront and to insert them into the web form, followed by a manual evaluation by employees of the indexing system to assess if the request is eligible and lawful. We propose a universal framework Oblivion to support the automation of the right to be forgotten in a scalable, provable and privacy-preserving manner. First, Oblivion enables a user to automatically find and tag her disseminated personal information using natural language processing and image recognition techniques and file a request in a privacy-preserving manner. Second, Oblivion provides indexing systems with an automated and provable eligibility mechanism, asserting that the author of a request is indeed affected by an online resource. The automated ligibility proof ensures censorship-resistance so that only legitimately affected individuals can request the removal of corresponding links from search results. We have conducted comprehensive evaluations, showing that Oblivion is capable of handling 278 removal requests per second, and is hence suitable for large-scale deployment.
💡 Research Summary
The paper presents Oblivion, a comprehensive framework designed to automate the enforcement of the European Union’s “right to be forgotten” while preserving user privacy and achieving scalability. Current implementations by major search engines (Google, Microsoft, Yahoo) rely on a manual process: users must locate every offending URL, fill out a web form, and upload copies of identity documents. This approach is labor‑intensive, does not scale to the volume of requests (over 200,000 submitted to Google since the 2014 ruling), and exposes additional personal data.
Oblivion addresses these shortcomings through three tightly integrated components. First, an automated discovery module uses state‑of‑the‑art natural language processing (NLP) and deep‑learning image‑recognition techniques to scan the web for personal data belonging to a user. Named‑entity extraction identifies textual identifiers (name, address, phone number) while facial‑recognition models detect the user’s likeness in images. The result is a curated list of URLs that potentially violate the user’s privacy.
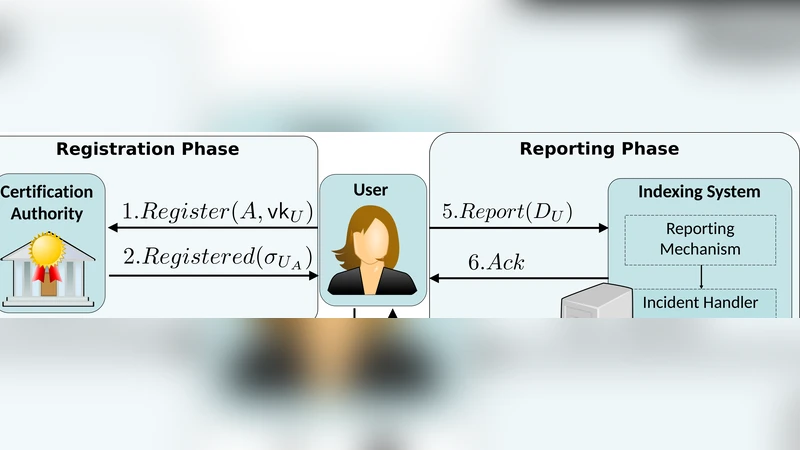
Second, a privacy‑preserving eligibility proof leverages trusted digital credentials issued by a Certification Authority (CA), such as electronic passports or national ID cards. These credentials contain signed attributes (e.g., a hash of the passport photo, name, address) that can be cryptographically verified without revealing the underlying raw data. The user submits the signed attributes to an Ownership Certification Party (OCP). The OCP, which may be an independent third‑party or part of the search‑engine operator, automatically compares the signed attributes with the publicly available content of each URL. If a match is found, the OCP issues a certificate stating that the user is indeed the data subject of that resource. Crucially, the OCP never learns the user’s full identity; it only learns enough to confirm the match.
Third, the indexing system (the search engine) validates the OCP’s certificate using RSA homomorphic properties. By exploiting the multiplicative homomorphism of RSA, Oblivion can verify a large batch of user credentials with a single exponentiation, dramatically reducing computational overhead. The search engine thus receives a minimal proof that the requester is legitimately affected by the indexed resource, without learning any additional personal information. Upon successful verification, the engine removes the link from its index.
The security model assumes a fully trusted CA, while the OCP is only partially trusted. The framework enforces a minimal disclosure principle: the indexing system learns only the binary fact of eligibility, and the OCP learns only the signed attributes needed for verification. External adversaries are mitigated through TLS for confidentiality, key revocation mechanisms for compromised private keys, and replay‑attack resistance built into the protocol. Legal admissibility (balancing data‑protection rights against public interest) remains a judicial matter and is deliberately left out of the automated scope.
Performance experiments on a standard 2.5 GHz dual‑core notebook with 8 GB RAM demonstrate that Oblivion can process 278 removal requests per second, confirming its suitability for large‑scale deployment. Accuracy of the discovery module is high (F1≈0.92 for textual entities, ≈0.95 for facial matching), and the modular design allows future extensions to other media types such as audio and video.
In summary, Oblivion provides (1) automated identification of personal data across the web, (2) a cryptographic, privacy‑preserving proof of user eligibility, and (3) high‑throughput verification suitable for real‑world search‑engine workloads. The framework bridges the gap between the legal right to be forgotten and practical, scalable technical enforcement, and opens avenues for further research into policy‑driven automation, cross‑jurisdictional extensions, and blockchain‑based credential management.
Comments & Academic Discussion
Loading comments...
Leave a Comment