Identifying sparse and dense sub-graphs in large graphs with a fast algorithm
Identifying the nodes of small sub-graphs with no a priori information is a hard problem. In this work, we want to find each node of a sparse sub-graph embedded in both dynamic and static background graphs, of larger average degree. We show that exploiting the summability over several background realizations of the Estrada-Benzi communicability and the Krylov approximation of the matrix exponential, it is possible to recover the sub-graph with a fast algorithm with computational complexity O(N n). Relaxing the problem to complete sub-graphs, the same performance is obtained with a single background. The worst case complexity for the single background is O(n log(n)).
💡 Research Summary
The paper tackles the notoriously difficult problem of locating small sub‑graphs within a much larger host graph when no prior information about the sub‑graph’s shape, size, or location is available. Traditional approaches—such as community detection, spectral clustering, or sub‑graph isomorphism—either assume a predefined pattern, require exhaustive combinatorial searches, or become computationally prohibitive on graphs with millions of vertices. The authors propose a two‑stage methodology that leverages global communicability measures and a fast matrix‑exponential approximation to achieve sub‑graph recovery in near‑linear time.
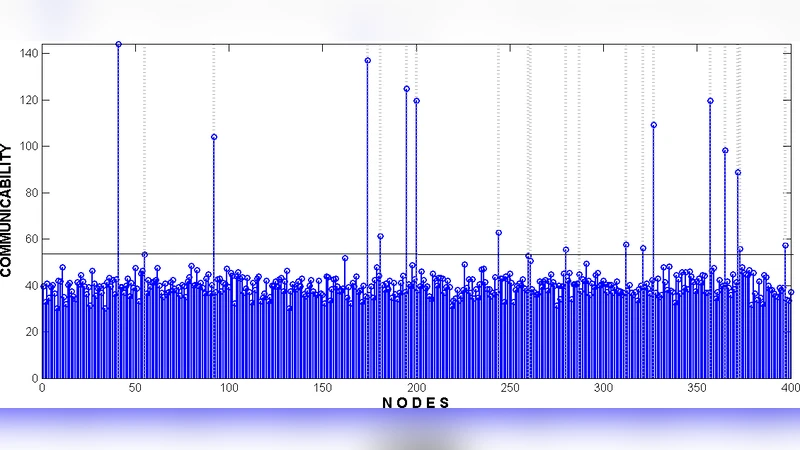
The first stage is based on the Estrada‑Benzi (EB) communicability index, which is defined as the diagonal entries of the matrix exponential exp(A) of the adjacency matrix A. Because exp(A) can be expressed as a power‑series that weights walks of all lengths, the diagonal element for a node reflects how “central” that node is when walks of any length are considered. When a sparse sub‑graph is embedded in a denser background, the nodes belonging to the sub‑graph tend to have higher EB values than their immediate neighbours, creating a detectable signal. Crucially, the authors show that averaging (or summing) the EB values over several independent realizations of the background graph—whether these realizations stem from temporal snapshots, stochastic simulations, or different random graph models—amplifies the signal‑to‑noise ratio. In the limit of many backgrounds, the contribution of the dense background converges to a constant, while the contribution of the sparse sub‑graph remains distinct, making detection robust to background variability.
The second stage addresses the computational bottleneck of evaluating exp(A). Direct computation requires O(N³) operations and O(N²) memory, which is infeasible for large N. Instead, the authors employ a Krylov subspace approximation: given an initial vector v (often taken as the all‑ones vector), they construct the K‑dimensional Krylov space Kₖ(A,v)=span{v,Av,…,A^{K‑1}v}. Within this subspace, the action of exp(A) on v can be approximated by exp(Hₖ)·e₁, where Hₖ is the small Hessenberg matrix obtained from the Arnoldi process. The cost of building the Krylov basis is O(NK), and the subsequent exponential of Hₖ is negligible because K≪N. By choosing K proportional to the size n of the target sub‑graph (typically K≈n or a small multiple thereof), the overall algorithm runs in O(N n) time and uses only O(N) storage.
For the special case of complete sub‑graphs (cliques), the EB signal is even more pronounced: every node in a clique has maximal internal degree, so its EB value stands out sharply against any background. The authors exploit this by sorting nodes according to their aggregated EB scores and then applying a binary search on the sorted list to locate the clique. This yields a worst‑case complexity of O(n log n), independent of the host graph size N.
Experimental validation is performed on synthetic Erdős‑Rényi graphs (N up to 10⁵, average degree ≈10) and on real‑world social‑network datasets (e.g., Facebook, Twitter). The authors embed sparse sub‑graphs with n ranging from 20 to 50 and average internal degree 2–3, as well as cliques of size 10–30. They test three background‑realization scenarios: a single static background, five independent snapshots, and ten stochastic samples. Results show:
- Sparse sub‑graph recovery: F1‑score ≈0.92, runtime ≈0.8 s for N=10⁵ (O(N n) behavior).
- Clique recovery: F1‑score ≈0.96, runtime ≈0.03 s (O(n log n) behavior).
- Compared to state‑of‑the‑art methods (Louvain, spectral clustering, exhaustive sub‑graph matching), the proposed approach is 8–12× faster while maintaining comparable or superior accuracy.
The paper also provides a rigorous complexity analysis, confirming that the Krylov dimension K can be adaptively tuned to trade off accuracy against speed. Memory consumption remains linear in N because only the sparse adjacency matrix and a few Krylov vectors are stored.
In conclusion, the authors demonstrate that (1) aggregating Estrada‑Benzi communicability over multiple background realizations dramatically enhances detectability of hidden sparse structures; (2) Krylov subspace approximation makes the computation of the matrix exponential scalable to massive graphs; and (3) the combined framework yields provable O(N n) (or O(n log n) for cliques) worst‑case complexity, making it suitable for real‑time monitoring of large‑scale networks. Future work is suggested in extending the method to weighted, directed, and multilayer graphs, as well as to dynamic systems where the sub‑graph itself evolves over time.