Asymptotic Analysis of Distributed Bayesian Detection with Byzantine Data
In this letter, we consider the problem of distributed Bayesian detection in the presence of data falsifying Byzantines in the network. The problem of distributed detection is formulated as a binary hypothesis test at the fusion center (FC) based on …
Authors: Bhavya Kailkhura, Yunghsiang S. Han, Swastik Brahma
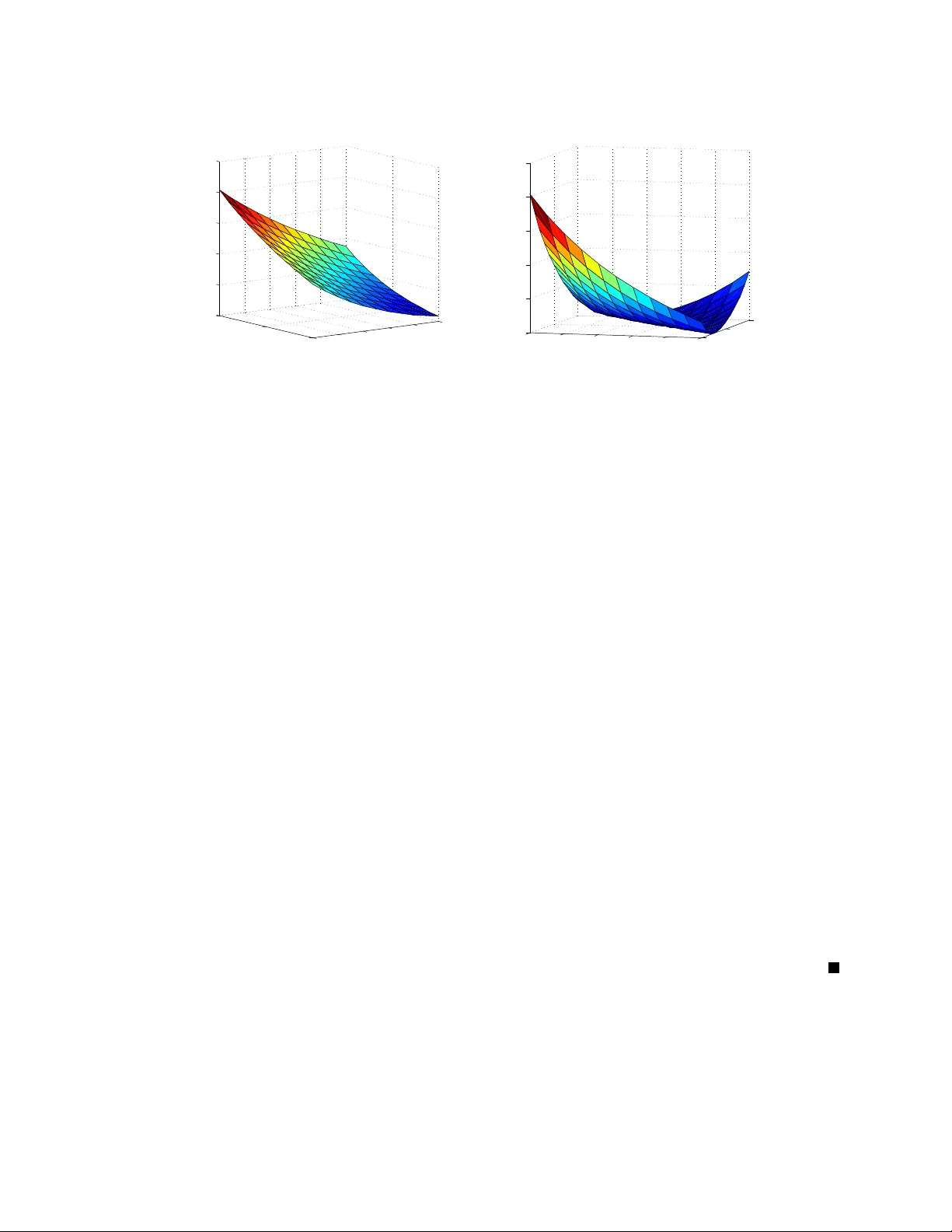
1 Asymptotic Analysis of Distrib uted Bayesian Detection with Byzantine Data Bha vya Kailkhura, Student Member , IEEE , Y unghsiang S. Han, F ellow , IEEE , Swastik Brahma, Member , IEEE , Pramod K. V arshney , F ellow , IEEE Abstract In this letter , we consider the problem of distributed Bayesian detection in the presence of data falsifying Byzantines in the netw ork. The problem of distributed detection is formulated as a binary hypothesis test at the fusion center (FC) based on 1-bit data sent by the sensors. Adopting Chernoff information as our performance metric, we study the detection performance of the system under Byzan- tine attack in the asymptotic regime. The expression for minimum attacking power required by the Byzantines to blind the FC is obtained. More specifically , we show that abo ve a certain fraction of Byzantine attackers in the network, the detection scheme becomes completely incapable of utilizing the sensor data for detection. When the fraction of Byzantines is not sufficient to blind the FC, we also pro vide closed form expressions for the optimal attacking strategies for the Byzantines that most degrade the detection performance. Index T erms Bayesian detection, Data falsification, Byzantine Data, Chernoff information, Distributed detection This work was supported in part by ARO under Grant W911NF-13-2-0040 and National Science Council of T aiwan, under grants NSC 99-2221-E-011-158 -MY3, NSC 101-2221-E-011-069 -MY3. Han’ s work was completed during his visit to Syracuse Univ ersity from 2012 to 2013. B. Kailkhura, S. Brahma and P . K. V arshney are with Department of EECS, Syracuse Univ ersity , Syracuse, NY 13244. (email: bkailkhu@syr .edu; skbrahma@syr .edu; varshne y@syr .edu) Y . S. Han is with EE Department, National T aiwan Univ ersity of Science and T echnology , T aiwan, R. O. C. (email: yshan@mail.ntust.edu.tw) DRAFT 2 I . I N T R O D U C T I O N Distributed detection is a well studied topic in the detection theory literature [1]–[3]. In distributed detection systems, due to bandwidth and energy constraints, the nodes often make a 1-bit local decision regarding the presence or absence of a phenomenon before sending it to the fusion center (FC). Based on the local decisions transmitted by the nodes, the FC makes a global decision about the presence or absence of the phenomenon of interest. The performance of such systems strongly depends on the reliability of the nodes in the network. The distributed nature of such systems makes them quite vulnerable to dif ferent types of attacks. One typical attack on such networks is a Byzantine attack. While Byzantine attacks (originally proposed by [4]) may , in general, refer to many types of malicious behavior , our focus in this letter is on data-falsification attacks [5]–[12]. Distributed detection in the presence of Byzantine attacks has been explored in the past in [7], [8], where the problem of determining the most ef fectiv e attacking strategy of the Byzantine nodes w as explored. In [7], the authors considered the Neyman-Pearson (NP) setup and determined the optimal attacking strategy which minimizes the detection error exponent. This approach, based on Kullback-Leibler div ergence (KLD), is analytically tractable and yields approximate results in non-asymptotic cases. They also assumed that the Byzantines know the true hypothesis, which obviously is not satisfied in practice b ut does pro vide a bound. In [8], the authors analyzed the same problem in the conte xt of collaborati ve spectrum sensing under Byzantine Attacks. They relaxed the assumption of perfect kno wledge of the hypotheses by assuming that the Byzantines determine the kno wledge about the true hypotheses from their o wn sensing observations. Schemes for Byzantine node identification ha ve been proposed in [8], [12]–[15]. Our focus in this letter is considerably different from Byzantine node identification schemes in that we do not try to authenticate the data; we determine the most effecti ve attacking strategies and distributed detection schemes that are robust against attacks. All the approaches discussed so far for distrib uted detection schemes robust to Byzantine attacks consider distributed detection under the Neyman-Pearson (NP) setup. In contrast, we focus on the impact of Byzantine nodes on distributed Bayesian detection, which has not been considered in the past. Adopting Chernof f information as our performance metric, we study the performance of distrib uted detection systems with Byzantines in the asymptotic regime. W e are DRAFT 3 H one s t B y z an ti ne v1 v1 v2 v2 vN-1 vN uN-1 vN Fig. 1. System Model interested in answering the follo wing questions. • From the Byzantines’ perspecti ve, what is the most ef fectiv e attacking strategy? • What is the minimum fraction of Byzantines needed to blind the FC? • From the FC’ s perspectiv e, kno wing the fraction of Byzantines in the network, or an upper bound thereof, what is the achiev able performance not kno wing the identities of compromised nodes? The signal processing problem considered in this letter is most similar to [8]. Our results, ho wev er , are not a direct application of those in [8]. While as in [8], we are also interested in the worst distribution pair , our objectiv e function and, therefore, the techniques to find them are dif ferent. In contrast to [8], where only optimal strategies to blind the FC were obtained, we also provide closed form expressions for the optimal attacking strategies for the Byzantines that most degrade the detection performance when the fraction of Byzantines is not suf ficient to blind the FC. Indeed, finding the optimal Byzantine attacking strate gies is only the first step toward designing a rob ust distributed detection system. The knowledge of optimal attack strategies can be further used to implement the optimal detector at the FC. I I . D I S T R I B U T E D D E T E C T I O N I N T H E P R E S E N C E O F B Y Z A N T I N E S Consider two hypotheses H 0 (signal is absent) and H 1 (signal is present). Also, consider a parallel network (see Figure 1), comprised of a central entity (known as the Fusion Center (FC)) and a set of N sensors (nodes), which faces the task of determining which of the two DRAFT 4 hypotheses is true. Prior probabilities of the two hypotheses H 0 and H 1 are denoted by P 0 and P 1 , respecti vely . The sensors observ e the phenomenon, carry out local computations to decide the presence or absence of the phenomenon, and then send their local decisions to the FC that makes a final decision after processing the local decisions. Observations at the nodes are assumed to be conditionally independent and identically distributed. A Byzantine attack on such a system compromises some of the nodes which may then intentionally send falsified local decisions to the FC to make the final decision incorrect. W e assume that a fraction α of the N nodes which observe the phenomenon ha ve been compromised by an attacker . W e consider the communication channels to be error-free. Next, we describe the modus-operandi of the nodes in detail. A. Modus Operandi of the Nodes Based on the observ ations, each node i mak es a one-bit local decision v i ∈ { 0 , 1 } regarding the absence or presence of the phenomenon using the likelihood ratio test p (1) Y i ( y i ) p (0) Y i ( y i ) v i =1 ≷ v i =0 λ (1) where λ is the identical threshold 1 used at all the sensors and p ( k ) Y i ( y i ) is the conditional probability density function (PDF) of observ ation y i under the hypothesis H k , where k = 0 , 1 . Each node i , after making its one-bit local decision v i , sends u i to the FC, where u i = v i if i is an uncompromised (honest) node, but for a compromised (Byzantine) node i , u i need not be equal to v i . W e denote the probabilities of detection and false alarm of each node i in the network by P d = P ( v i = 1 | H 1 ) and P f = P ( v i = 1 | H 0 ) , respectiv ely , which hold for both uncompromised nodes as well as compromised nodes. In this letter , we assume that each Byzantine decides to attack independently relying on its own observ ation and decision regarding the presence or absence of the phenomenon. Specifically , we define the following strategies P H j, 1 , P H j, 0 and P B j, 1 , P B j, 0 ( j ∈ { 0 , 1 } ) for the honest and Byzantine nodes, respecti vely: Honest nodes: P H 1 , 1 = 1 − P H 0 , 1 = P H ( x = 1 | y = 1) = 1 (2) 1 It has been shown that the use of identical thresholds is asymptotically optimal [16]. DRAFT 5 P H 1 , 0 = 1 − P H 0 , 0 = P H ( x = 1 | y = 0) = 0 (3) Byzantine nodes: P B 1 , 1 = 1 − P B 0 , 1 = P B ( x = 1 | y = 1) (4) P B 1 , 0 = 1 − P B 0 , 0 = P B ( x = 1 | y = 0) (5) where P H ( x = a | y = b ) ( P B ( x = a | y = b ) ) is the probability that an honest (Byzantine) node sends a to the FC when its actual local decision is b . From no w onwards, we will refer to Byzantine flipping probabilities simply by ( P 1 , 0 , P 0 , 1 ) . W e also assume that the FC is not aware of the identities of Byzantine nodes and considers each node i to be Byzantine with a certain probability α . B. P erformance Criterion The Byzantine attacker alw ays wants to degrade the detection performance at the FC as much as possible; in contrast, the FC wants to maximize the detection performance. The detection performance at the FC in the presence of the Byzantines, howe ver , cannot be analyzed eas- ily for the non-asymptotic case. T o gain insights into the degree to which an adversary can cause performance degradation, we consider the asymptotic regime and employ the Chernoff information [17] to be the network performance metric that characterizes detection performance. If u is a random vector ha ving N statistically independent and identically distributed com- ponents, u i s, under both hypotheses, the optimal detector results in error probability that obeys the asymptotics lim N →∞ ln P E N = − C ( π 1 , 1 , π 1 , 0 ) , (6) where the Chernof f information C is defined as C = max 0 ≤ t ≤ 1 − ln( X j ∈{ 0 , 1 } π t j 0 π 1 − t j 1 ) . (7) π j 0 and π j 1 in (7) are the conditional probabilities of u i = j giv en H 0 and H 1 , respecti vely . DRAFT 6 Specifically , π 1 , 0 and π 1 , 1 can be calculated as π 1 , 0 = α ( P 1 , 0 (1 − P f ) + (1 − P 0 , 1 ) P f ) + (1 − α ) P f (8) and π 1 , 1 = α ( P 1 , 0 (1 − P d ) + (1 − P 0 , 1 ) P d ) + (1 − α ) P d , (9) where α is the fraction of Byzantine nodes. From the Byzantine attack er’ s point of vie w , our goal is to find P 1 , 0 and P 0 , 1 that minimize Chernof f information C for a giv en v alue of α . Observe that, when α ≥ 0 . 5 , Chernoff information can be minimized by simply making posterior probabilities equal to prior probabilities (we discuss this in more detail later in the letter). Howe ver , for α < 0 . 5 , a closed form e xpression for Chernof f information is needed to find P 1 , 0 and P 0 , 1 that minimize C . I I I . C L O S E D F O R M E X P R E S S I O N F O R T H E C H E R N O FF I N F O R M A T I O N In this section, we deriv e a closed form expression for the Chernoff information, when α < 0 . 5 . 2 T o obtain the closed form expression for Chernof f information, the solution of an optimization problem is required: max 0 ≤ t ≤ 1 − ln( P j ∈{ 0 , 1 } π t j 0 π 1 − t j 1 ) . This is easy to ev aluate numerically because ( P j ∈{ 0 , 1 } π t j 0 π 1 − t j 1 ) is con vex in t . Howe ver , obtaining a closed form solution for this optimization problem can be tedious. Fortunately , we can find a closed form expression for the Chernof f information for α < 0 . 5 . Lemma 1. F or α < 0 . 5 , the Chernoff information between the distributions π 1 , 0 and π 1 , 1 (as given in (8) and (9) , r espectively) is given by C = − ln( P j ∈{ 0 , 1 } π t ∗ j 0 π 1 − t ∗ j 1 ) with t ∗ = ln ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ln (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 . (10) Pr oof: Observe that the problem of finding the optimal t ∗ in (7) is equi valent to min 0 ≤ t ≤ 1 ln( X j ∈{ 0 , 1 } π t j 0 π 1 − t j 1 ) (11) 2 Similar results can be derived for α ≥ 0 . 5 . DRAFT 7 which is a constrained minimization problem. T o find t ∗ , we first perform unconstrained mini- mization (no constraint on the value of t ) and later show that the solution of the unconstrained optimization problem is the same as the solution of the constrained optimization problem. In other words, the optimal t ∗ is the same for both cases. By observing that logarithm is an increasing function, the optimization problem as gi ven in (11) is equi valent to min t [ π t 1 , 0 π 1 − t 1 , 1 + (1 − π 1 , 0 ) t (1 − π 1 , 1 ) 1 − t ] . (12) No w , performing the first deriv ati ve test, we hav e d dt [ π t 1 , 0 π 1 − t 1 , 1 + (1 − π 1 , 0 ) t (1 − π 1 , 1 ) 1 − t ] = (1 − π 1 , 1 ) 1 − π 1 , 0 1 − π 1 , 1 t ln 1 − π 1 , 0 1 − π 1 , 1 + π 1 , 1 π 1 , 0 π 1 , 1 t ln π 1 , 0 π 1 , 1 . (13) The first deri vati ve (13) is set to zero to find the critical points of the function: (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 t = ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 . (14) After some simplification, t ∗ which satisfies (14) turns out to be t ∗ = ln ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ln (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 . (15) T o determine whether the critical point is a minimum or a maximum, we perform the second deri vati ve test. Since d 2 d 2 t [ π t 1 , 0 π 1 − t 1 , 1 + (1 − π 1 , 0 ) t (1 − π 1 , 1 ) 1 − t ] = (1 − π 1 , 1 ) 1 − π 1 , 0 1 − π 1 , 1 t ln 1 − π 1 , 0 1 − π 1 , 1 2 + π 1 , 1 π 1 , 0 π 1 , 1 t ln π 1 , 0 π 1 , 1 2 (16) is greater than zero, t ∗ as giv en in (15) minimizes (12). Since 0 ≤ t ∗ ≤ 1 (See proof in Appendix DRAFT 8 A), t ∗ as gi ven in (15) is also the solution of (11). I V . A S Y M P T O T I C A N A L Y S I S O F O P T I M A L B Y Z A N T I N E A T TAC K First, we will determine the minimum fraction of Byzantines needed to blind the decision fusion scheme. A. Critical P ower to Blind the Fusion Center In this section, we determine the minimum fraction of Byzantine nodes needed to make the FC “blind” and denote it by α blind . W e say that the FC is blind if an adversary can make the data that the FC recei ves from the sensors such that no information is con ve yed. In other words, the optimal detector at the FC cannot perform better than simply making the decision based on priors. Lemma 2. In Bayesian distributed detection, the minimum fraction of Byzantines needed to make the FC blind is α blind = 0 . 5 . Pr oof: The FC becomes blind if the probability of receiving a gi ven vector u is independent of the hypothesis present. Using the conditional i.i.d. assumption, under which observations at the nodes are conditionally independent and identically distributed, the condition to make the FC blind becomes π 1 , 1 = π 1 , 0 . This is true only when α [ P 1 , 0 ( P f − P d ) + (1 − P 0 , 1 )( P d − P f )] + (1 − α )( P d − P f ) = 0 . Hence, the FC becomes blind if α = 1 ( P 1 , 0 + P 0 , 1 ) . (17) α in (17) is minimized when P 1 , 0 and P 0 , 1 both take their largest values, i.e., P 1 , 0 = P 0 , 1 = 1 . Hence, α blind = 0 . 5 . Next, we find the optimal attacking strategies which minimize the Chernof f information. B. Minimization of Chernoff Information First, we minimize Chernoff information for α < 0 . 5 . Later in the section, we generalize our results for any arbitrary α . Since logarithm is an increasing function, the problem of minimizing the Chernof f information is equiv alent to the following problem: DRAFT 9 0 0.5 1 0 0.2 0.4 0.6 0.8 1 0 0.005 0.01 0.015 0.02 0.025 P 0,1 P 1,0 Chernoff information C (a) 0 0.2 0.4 0.6 0.8 1 0 0.5 1 0 0.005 0.01 0.015 0.02 0.025 P 0,1 P 1,0 Chernoff information C (b) Fig. 2. (a) Chernof f information as a function of ( P 1 , 0 , P 0 , 1 ) for α = 0 . 4 . (b) Chernoff information as a function of ( P 1 , 0 , P 0 , 1 ) for α = 0 . 8 . maximize P 1 , 0 ,P 0 , 1 π t ∗ 1 , 0 π 1 − t ∗ 1 , 1 + (1 − π 1 , 0 ) t ∗ (1 − π 1 , 1 ) 1 − t ∗ subject to 0 ≤ P 1 , 0 ≤ 1 0 ≤ P 0 , 1 ≤ 1 (P1) where α < 0 . 5 and t ∗ is as gi ven in (15). Let us denote ˜ C = π t ∗ 1 , 0 π 1 − t ∗ 1 , 1 + (1 − π 1 , 0 ) t ∗ (1 − π 1 , 1 ) 1 − t ∗ . Observe that, maximization of ˜ C is equiv alent to the minimization of Chernof f information C . Next, in Lemma 3 we present the properties of Chernoff information C (for the case when α < 0 . 5 ) with respect to ( P 1 , 0 , P 0 , 1 ) that enable us to find the optimal attacking strategies in this case. Lemma 3. Let α < 0 . 5 and assume that the optimal t ∗ is used in the expr ession for the Chernoff information. Then, the Chernof f information, C , is a monotonically decreasing function of P 1 , 0 for a fixed P 0 , 1 . Con versely , the Chernoff information is also a monotonically decr easing function of P 0 , 1 for a fixed P 1 , 0 . Pr oof: See Appendix B. Next, using Lemma 3, we present the optimal attacking strategies P 1 , 0 and P 0 , 1 that minimize the Chernof f information, C , for 0 ≤ α ≤ 1 . Theorem 1. The optimal attacking strate gy , ( P ∗ 1 , 0 , P ∗ 0 , 1 ) , which minimizes the Chernoff informa- DRAFT 10 tion is ( P ∗ 1 , 0 , P ∗ 0 , 1 ) ( p 1 , 0 , p 0 , 1 ) if α ≥ 0 . 5 (1 , 1) if α < 0 . 5 , wher e, ( p 1 , 0 , p 0 , 1 ) satisfy α ( p 1 , 0 + p 0 , 1 ) = 1 . Pr oof: The minimum value of C is zero and it occurs when π 1 , 1 = π 1 , 0 . By (8) and (9), π 1 , 1 = π 1 , 0 implies α ( P 1 , 0 + P 0 , 1 ) = 1 . (18) From (18), when α ≥ 0 . 5 , the attacker can always find flipping probabilities that make the Chernof f information equal to zero. When α = 0 . 5 , P 1 , 0 = P 0 , 1 = 1 is the optimal strategy . When α > 0 . 5 , any pair which satisfies P 1 , 0 + P 0 , 1 = 1 α is the optimal strategy . Howe ver , when α < 0 . 5 , (18) cannot be satisfied or in other words Byzantines can not make C = 0 since π 1 , 1 can not be made equal to π 1 , 0 . From Lemma 3, when α < 0 . 5 , the optimal attacking strategy , ( P 1 , 0 , P 0 , 1 ) , that minimizes the Chernof f information is (1 , 1) . Next, to gain insights into Theorem 1, we present some illustrati ve examples that corroborate our results. C. Illustrative Examples In Figure 2(a), we plot the Chernof f information as a function of ( P 1 , 0 , P 0 , 1 ) for ( P d = 0 . 6 , P f = 0 . 4) and α = 0 . 4 . It can be observed that for a fixed P 0 , 1 ( P 1 , 0 ) the Chernof f information C is a monotonically decreasing function of P 1 , 0 , P 0 , 1 (as has been shown in Lemma 3). In other words, when α = 0 . 4 , the attacking strategy , ( P 1 , 0 , P 0 , 1 ) , that minimizes the Chernoff information C is (1 , 1) . Similarly , in Figure 2(b), we consider the scenario when the fraction of Byzantines in the network is α = 0 . 8 . It can be seen from Figure 2(b) that the minimum value of the Chernof f information in this case is C = 0 . Notice that, the attacking strategy , ( P 1 , 0 , P 0 , 1 ) that makes C = 0 is not unique in this case. It can be verified that an y attacking strategy which satisfies P 1 , 0 + P 0 , 1 = 1 0 . 8 would make C = 0 . Thus, results presented in Figures 2(a) and 2(b) corroborate our theoretical result presented in Theorem 1. DRAFT 11 V . D I S C U S S I O N A N D F U T U R E W O R K W e considered the problem of distributed Bayesian detection with Byzantine data, and char - acterized the power of attack analytically . W e obtained closed form expressions for the optimal attacking strategies that most degrade the detection performance. The knowledge of optimal attack strategies can be further used to implement the optimal detector at the FC. Also in addition, if only an upper bound ˜ α on α is a vailable to the FC, then, optimal attack strate gies should be simply computed using the upper bound ˜ α . For any α ≤ ˜ α , the test designed with ˜ α achie ves an exponent no smaller than C ( ˜ α ) . In the future, we plan to extend our analysis to the non-asymptotic case. A P P E N D I X A P R O O F O F 0 ≤ t ∗ ≤ 1 First, we sho w that t ∗ ≤ 1 . W e start from the following equality: π 1 , 1 π 1 , 0 − 1 = 1 − π 1 , 0 π 1 , 0 − 1 − π 1 , 1 π 1 , 0 = 1 − π 1 , 0 π 1 , 0 1 − 1 − π 1 , 1 1 − π 1 , 0 . (19) By applying the logarithm inequality 1 − 1 x < ln( x ) < ( x − 1) , ∀ x > 0 , to (19), we have ln π 1 , 1 π 1 , 0 < π 1 , 1 π 1 , 0 − 1 = 1 − π 1 , 0 π 1 , 0 1 − 1 − π 1 , 1 1 − π 1 , 0 ≤ 1 − π 1 , 0 π 1 , 0 ln 1 − π 1 , 0 1 − π 1 , 1 . No w , ln π 1 , 1 π 1 , 0 ≤ 1 − π 1 , 0 π 1 , 0 ln 1 − π 1 , 0 1 − π 1 , 1 ⇔ ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ≤ (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 ⇔ ln ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ln (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 ≤ 1 ⇔ t ∗ ≤ 1 . DRAFT 12 Next, we sho w that t ∗ ≥ 0 . First we prove that the denominator of t ∗ is positi ve. Since π 1 , 1 > π 1 , 0 for P d > P f and α < 0 . 5 , we have π 1 , 1 > π 1 , 0 (20) ⇔ (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 > 1 (21) ⇔ ln (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 > 0 . (22) Next we pro ve that the numerator of t ∗ is nonne gati ve, and then t ∗ is nonne gati ve. W e start from the follo wing equality: 1 − π 1 , 0 π 1 , 1 = 1 − π 1 , 0 π 1 , 1 − 1 − π 1 , 1 π 1 , 1 = 1 − π 1 , 1 π 1 , 1 1 − π 1 , 0 1 − π 1 , 1 − 1 . (23) By applying the logarithm inequality 1 − 1 x < ln( x ) < ( x − 1) , ∀ x > 0 , to (23), we have ln π 1 , 1 π 1 , 0 > 1 − π 1 , 0 π 1 , 1 = 1 − π 1 , 1 π 1 , 1 1 − π 1 , 0 1 − π 1 , 1 − 1 ≥ 1 − π 1 , 1 π 1 , 1 ln 1 − π 1 , 0 1 − π 1 , 1 . No w , ln π 1 , 1 π 1 , 0 ≥ 1 − π 1 , 1 π 1 , 1 ln 1 − π 1 , 0 1 − π 1 , 1 ⇔ ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ≥ 1 ⇔ ln ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) π 1 , 1 1 − π 1 , 1 ≥ 0 . A P P E N D I X B P R O O F O F L E M M A 3 T o show that, for the optimal t ∗ and α < 0 . 5 , Chernoff information, C , is monotonically decreasing function of P 1 , 0 while keeping P 0 , 1 fixed is equiv alent to sho wing that ˜ C , is mono- tonically increasing function of P 1 , 0 while keeping P 0 , 1 fixed. Dif ferentiating both sides of ˜ C DRAFT 13 with respect to P 1 , 0 , we get d ˜ C P 1 , 0 = π t ∗ 1 , 0 π (1 − t ∗ ) 1 , 1 dt ∗ P 1 , 0 ln π 1 , 0 π 1 , 1 + (1 − t ∗ ) π 0 1 , 1 π 1 , 1 + t ∗ π 0 1 , 0 π 1 , 0 + (1 − π 1 , 0 ) t ∗ (1 − π 1 , 1 ) (1 − t ∗ ) dt ∗ P 1 , 0 ln 1 − π 1 , 0 1 − π 1 , 1 − (1 − t ∗ ) π 0 1 , 1 1 − π 1 , 1 − t ∗ π 0 1 , 0 1 − π 1 , 0 In the abov e equation, dt ∗ P 1 , 0 = ln π 1 , 1 π 1 , 0 + ln 1 − π 1 , 0 1 − π 1 , 1 G 0 G + π 0 1 , 1 π 1 , 1 + π 0 1 , 1 1 − π 1 , 1 − ln G + ln π 1 , 1 1 − π 1 , 1 π 0 1 , 1 π 1 , 1 − π 0 1 , 0 π 1 , 0 + π 0 1 , 1 1 − π 1 , 1 − π 0 1 , 0 1 − π 1 , 0 ln π 1 , 1 π 1 , 0 + ln 1 − π 1 , 0 1 − π 1 , 1 2 where G = ln( π 1 , 1 /π 1 , 0 ) ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) and G 0 G = ln 1 − π 1 , 0 1 − π 1 , 1 π 0 1 , 1 π 1 , 1 − π 0 1 , 0 π 1 , 0 − ln π 1 , 1 π 1 , 0 π 0 1 , 1 1 − π 1 , 1 − π 0 1 , 0 1 − π 1 , 0 ln π 1 , 1 π 1 , 0 ln 1 − π 1 , 0 1 − π 1 , 1 . Let us denote a 1 = ln G + ln( π 1 , 1 / (1 − π 1 , 1 )) , a 2 = ln( π 1 , 1 /π 1 , 0 ) + ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) , b 1 = ( π 0 1 , 1 /π 1 , 1 )+( π 0 1 , 1 / (1 − π 1 , 1 )) , b 2 = ( π 0 1 , 0 /π 1 , 0 )+( π 0 1 , 0 / (1 − π 1 , 0 )) , c 1 = π t ∗ 1 , 0 π 1 − t ∗ 1 , 1 ln( π 1 , 1 /π 1 , 0 ) , c 2 = (1 − π 1 , 0 ) t ∗ (1 − π 1 , 1 ) 1 − t ∗ ln((1 − π 1 , 0 ) / (1 − π 1 , 1 )) , d 1 = ((1 − t ∗ )( π 0 1 , 1 /π 1 , 1 ) + t ∗ ( π 1 , 0 /π 1 , 0 )) π t ∗ 1 , 0 π 1 − t ∗ 1 , 1 and d 2 = ((1 − t ∗ )( π 0 1 , 1 / (1 − π 1 , 1 )) + t ∗ ( π 1 , 0 / (1 − π 1 , 0 )))(1 − π 1 , 0 ) t ∗ (1 − π 1 , 1 ) 1 − t ∗ . No w , ˜ C , is monotonically increasing function of P 1 , 0 while keeping P 0 , 1 fixed if a 1 [ b 1 c 1 + b 2 c 2 ] + a 2 [ − ( G 0 /G ) c 1 + b 1 c 2 ] + a 2 2 d 1 > a 1 [ b 1 c 2 + b 2 c 1 ] + a 2 [ − ( G 0 /G ) c 2 + b 1 c 1 ] + a 2 2 d 2 ⇔ a 2 2 ( d 1 − d 2 ) > ( c 1 − c 2 )( a 1 ( b 2 − b 1 ) + a 2 (( G 0 /G ) + b 1 )) ⇔ a 2 2 ( d 1 − d 2 ) > 0 where the last inequality follo ws from the fact that ( c 1 − c 2 ) = 0 as giv en in (14). No w , to show that d ˜ C P 1 , 0 > 0 is equiv alent to show that ( d 1 − d 2 ) > 0 . In other words, t ∗ (1 − P f ) " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # + (1 − t ∗ )(1 − P d ) " π 1 , 0 π 1 , 1 t ∗ − 1 − π 1 , 0 1 − π 1 , 1 t ∗ # > 0 . (24) DRAFT 14 Note that, " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # ≥ 0; " π 1 , 0 π 1 , 1 t ∗ − 1 − π 1 , 0 1 − π 1 , 1 t ∗ # ≤ 0 . Hence, (24) can be simplified to, 1 − P f 1 − P d > (1 − t ∗ ) " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # t ∗ " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # . (25) Similarly , for the optimal t ∗ and α < 0 . 5 , Chernoff information, C , is monotonically decreasing function of P 0 , 1 while keeping P 1 , 0 fixed if ( d 1 − d 2 ) > 0 , which is equiv alent to sho w that, t ∗ ( − P f ) " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # + (1 − t ∗ )( − P d ) " π 1 , 0 π 1 , 1 t ∗ − 1 − π 1 , 0 1 − π 1 , 1 t ∗ # > 0 . (26) Furthermore, (26) can be simplified to P f P d < (1 − t ∗ ) " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # t ∗ " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # . (27) Combining (25) and (27), the condition to make Lemma 3 true becomes P f P d < (1 − t ∗ ) " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # t ∗ " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # < 1 − P f 1 − P d . (28) DRAFT 15 Note that right hand inequality in (28) can be re written as 1 t ∗ − 1 " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # < 1 − P f 1 − P d " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # ⇔ 1 t ∗ − 1 " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # < 1 − P f 1 − P d " π 1 , 1 π 1 , 0 π 1 , 0 π 1 , 1 t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − π 1 , 0 1 − π 1 , 1 t ∗ # ⇔ 1 − π 1 , 0 1 − π 1 , 1 t ∗ 1 − P f 1 − P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 < π 1 , 0 π 1 , 1 t ∗ 1 − P f 1 − P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 ⇔ (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 t ∗ 1 − P f 1 − P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 < 1 − P f 1 − P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 . Using the result from (14), the abov e equation can be written as ln( π 1 , 1 /π 1 , 0 ) ln (1 − π 1 , 0 ) (1 − π 1 , 1 ) π 1 , 1 1 − π 1 , 1 < 1 − P f 1 − P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 1 − P f 1 − P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 . Using the fact that G = ln( π 1 , 1 /π 1 , 0 ) ln (1 − π 1 , 0 ) (1 − π 1 , 1 ) , we get G < 1 − P f 1 − P d 1 π 1 , 0 + 1 t ∗ − 1 1 π 1 , 1 1 − P f 1 − P d 1 1 − π 1 , 0 + 1 t ∗ − 1 1 1 − π 1 , 1 . After some simplification, the abov e condition can be written as 1 − P f 1 − P d G 1 − π 1 , 0 − 1 π 1 , 0 < 1 t ∗ − 1 1 π 1 , 1 − G 1 − π 1 , 1 ⇔ 1 − P f 1 − P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [ π 1 , 0 ( G + 1) − 1] < 1 t ∗ − 1 [1 − π 1 , 1 ( G + 1)] 1 t ∗ [ π 1 , 1 ( G + 1) − 1] < 1 − P f 1 − P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] + [ π 1 , 1 ( G + 1) − 1] . (29) Notice that, in the abov e equation π 1 , 1 ( G + 1) ≥ 1 and π 1 , 0 ( G + 1) ≤ 1 (30) DRAFT 16 or equiv alently 1 − π 1 , 1 π 1 , 1 ≤ G ≤ 1 − π 1 , 0 π 1 , 0 . The second inequality in (30) follo ws from the fact that ln π 1 , 1 π 1 , 0 ≥ ln 1 − π 1 , 0 1 − π 1 , 1 1 − π 1 , 1 π 1 , 1 . Using logarithm inequality , we have ln π 1 , 1 π 1 , 0 ≥ 1 − π 1 , 0 π 1 , 1 = 1 − π 1 , 1 π 1 , 1 1 − π 1 , 0 1 − π 1 , 1 − 1 ≥ ln 1 − π 1 , 0 1 − π 1 , 1 1 − π 1 , 1 π 1 , 1 . Similarly , to sho w that the second inequality in (30) is true we sho w ln π 1 , 1 π 1 , 0 ≤ ln 1 − π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 π 1 , 0 . Using loga- rithm inequality , ln π 1 , 1 π 1 , 0 ≤ π 1 , 1 π 1 , 0 − 1 = 1 − π 1 , 0 π 1 , 0 1 − 1 − π 1 , 1 1 − π 1 , 0 ≤ ln 1 − π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 π 1 , 0 . Using these results we can then write (29) in the form belo w , [ π 1 , 1 ( G + 1) − 1] 1 − P f 1 − P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] + [ π 1 , 1 ( G + 1) − 1] < t ∗ ⇔ 1 1 − P f 1 − P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] + 1 < t ∗ . (31) Similarly , the left hand side inequality in (28) can be written as, P f P d " π 1 , 1 π 1 , 0 1 − t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − t ∗ # < 1 t ∗ − 1 " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # ⇔ P f P d " π 1 , 1 π 1 , 0 π 1 , 0 π 1 , 1 t ∗ − 1 − π 1 , 1 1 − π 1 , 0 1 − π 1 , 0 1 − π 1 , 1 t # < 1 t ∗ − 1 " 1 − π 1 , 0 1 − π 1 , 1 t ∗ − π 1 , 0 π 1 , 1 t ∗ # ⇔ π 1 , 0 π 1 , 1 t P f P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 < 1 − π 1 , 0 1 − π 1 , 1 t P f P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 ⇔ P f P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 < (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 t ∗ P f P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 . Using the results from (14), the abov e equation can be written as, P f P d π 1 , 1 π 1 , 0 + 1 t ∗ − 1 P f P d 1 − π 1 , 1 1 − π 1 , 0 + 1 t ∗ − 1 < ln( π 1 , 1 /π 1 , 0 ) ln (1 − π 1 , 0 ) (1 − π 1 , 1 ) π 1 , 1 1 − π 1 , 1 . DRAFT 17 Lets denote G = ln( π 1 , 1 /π 1 , 0 ) ln (1 − π 1 , 0 ) (1 − π 1 , 1 ) , we get P f P d 1 π 1 , 0 + 1 t ∗ − 1 1 π 1 , 1 P f P d 1 1 − π 1 , 0 + 1 t ∗ − 1 1 1 − π 1 , 1 < G. After some simplification the abov e condition can be written as, 1 t ∗ − 1 1 π 1 , 1 − G 1 − π 1 , 1 < P f P d G 1 − π 1 , 0 − 1 π 1 , 0 ⇔ 1 t ∗ − 1 [1 − π 1 , 1 ( G + 1)] < P f P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [ π 1 , 0 ( G + 1) − 1] ⇔ P f P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] + [ π 1 , 1 ( G + 1) − 1] < 1 t ∗ [ π 1 , 1 ( G + 1) − 1] . Using (30), the condition can be written as t ∗ < [ π 1 , 1 ( G + 1) − 1] P f P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] + [ π 1 , 1 ( G + 1) − 1] t ∗ < 1 P f P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] + 1 . (32) No w from (31) and (32), Lemma 3 is true if A = 1 1 − P f 1 − P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] + 1 < t ∗ < 1 P f P d π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] + 1 = B . (33) Next, we show that, the optimal t ∗ is with in the region ( A, B ) . W e start from the inequality P f P d π 1 , 1 π 1 , 0 < 1 < 1 − P f 1 − P d 1 − π 1 , 1 1 − π 1 , 0 ⇔ P f P d π 1 , 1 π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] < 1 − π 1 , 0 ( G + 1) π 1 , 1 ( G + 1) − 1 < 1 − P f 1 − P d 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] Let us denote, Y = π 1 , 1 π 1 , 0 1 − π 1 , 1 1 − π 1 , 0 [1 − π 1 , 0 ( G + 1)] [ π 1 , 1 ( G + 1) − 1] , then the abo ve condition can be DRAFT 18 written as, P f P d Y 1 − π 1 , 0 1 − π 1 , 1 < 1 − π 1 , 0 ( G + 1) π 1 , 1 ( G + 1) − 1 < 1 − P f 1 − P d Y π 1 , 0 π 1 , 1 (34) Next, we use the log inequality , x − 1 x < ln( x ) < ( x − 1) , ∀ x > 0 , to deriv e further results. Let us focus our attention to the left hand side inequality in (34) P f P d Y 1 − π 1 , 0 1 − π 1 , 1 < 1 − π 1 , 0 ( G + 1) π 1 , 1 ( G + 1) − 1 ⇔ P f Y Gπ 1 , 1 1 − π 1 , 1 − 1 < P d 1 − Gπ 1 , 0 1 − π 1 , 0 ⇔ P f Y ln G π 1 , 1 1 − π 1 , 1 < P d ln 1 G 1 − π 1 , 0 π 1 , 0 (35) No w , let us focus our attention to the right hand side inequality in (34) 1 − π 1 , 0 ( G + 1) π 1 , 1 ( G + 1) − 1 < 1 − P f 1 − P d Y π 1 , 0 π 1 , 1 ⇔ (1 − P d ) 1 − π 1 , 0 Gπ 1 , 0 − 1 < (1 − P f ) Y 1 − 1 − π 1 , 1 Gπ 1 , 1 ⇔ (1 − P d )ln 1 G 1 − π 1 , 0 π 1 , 0 < (1 − P f ) Y ln G π 1 , 1 1 − π 1 , 1 (36) No w using the results from (35) and (36), we can deduce that P f P d Y < ln 1 G 1 − π 1 , 0 π 1 , 0 ln G π 1 , 1 1 − π 1 , 1 < 1 − P f 1 − P d Y ⇔ 1 1 + 1 − P f 1 − P d Y < 1 1 + ln 1 G 1 − π 1 , 0 π 1 , 0 ln G π 1 , 1 1 − π 1 , 1 < 1 1 + P f P d Y (37) which is true from the fact that for a > 0 , b > 0 , 1 1 + a < 1 1 + b if f b < a . Next, observe that, DRAFT 19 t ∗ as gi ven in (15) can be written as t ∗ = ln G π 1 , 1 1 − π 1 , 1 ln (1 /π 1 , 0 ) − 1 (1 /π 1 , 1 ) − 1 = ln( G ) + ln π 1 , 1 1 − π 1 , 1 ln π 1 , 1 π 1 , 0 + ln 1 − π 1 , 0 1 − π 1 , 1 . Observe that, ln G π 1 , 1 1 − π 1 , 1 ≥ 0 and ln 1 G 1 − π 1 , 0 π 1 , 0 ≥ 0 or equiv alently G π 1 , 1 1 − π 1 , 1 ≥ 1 and 1 G 1 − π 1 , 0 π 1 , 0 ≥ 1 from (30). Now , t ∗ = 1 1 + ln π 1 , 1 π 1 , 0 + ln 1 − π 1 , 0 1 − π 1 , 1 − ln( G ) − ln π 1 , 1 1 − π 1 , 1 ln( G ) + ln π 1 , 1 1 − π 1 , 1 = 1 1 + ln 1 G 1 − π 1 , 0 π 1 , 0 ln G π 1 , 1 1 − π 1 , 1 . Which along with (37) implies that 1 1 + 1 − P f 1 − P d Y < t ∗ < 1 1 + P f P d Y or in other words, A < t ∗ < B . This completes our proof. R E F E R E N C E S [1] P . K. V arshney , Distributed Detection and Data Fusion . New Y ork:Springer-V erlag, 1997. [2] R. V iswanathan and P . K. V arshney , “Distributed detection with multiple sensors: Part I - Fundamentals, ” Pr oc. IEEE , vol. 85, no. 1, pp. 54 –63, Jan 1997. [3] V . V eerav alli and P . K. V arshney , “Distributed inference in wireless sensor networks, ” Philosophical T ransactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , vol. 370, pp. 100–117, 2012. [4] L. Lamport, R. Shostak, and M. Pease, “The Byzantine Generals Problem, ” ACM T rans. Pr ogram. Lang. Syst. , vol. 4, no. 3, pp. 382–401, Jul. 1982. [Online]. A vailable: http://doi.acm.org/10.1145/357172.357176 [5] A. Fragkiadakis, E. Tragos, and I. Askoxylakis, “A Survey on Security Threats and Detection T echniques in Cognitive Radio Networks, ” IEEE Communications Surveys T utorials , vol. 15, no. 1, pp. 428–445, 2013. [6] H. Rif ` a-Pous, M. J. Blasco, and C. Garrigues, “Revie w of robust cooperativ e spectrum sensing techniques for cognitiv e radio networks, ” W irel. P ers. Commun. , vol. 67, no. 2, pp. 175–198, Nov . 2012. [Online]. A vailable: http://dx.doi.org/10.1007/s11277- 011- 0372- x [7] S. Marano, V . Matta, and L. T ong, “Distributed Detection in the Presence of Byzantine Attacks, ” IEEE T rans. Signal Pr ocess. , vol. 57, no. 1, pp. 16 –29, Jan. 2009. [8] A. Raw at, P . Anand, H. Chen, and P . V arshney , “Collaborative Spectrum Sensing in the Presence of Byzantine Attacks in Cognitiv e Radio Networks, ” IEEE T rans. Signal Process. , vol. 59, no. 2, pp. 774 –786, Feb 2011. DRAFT 20 [9] B. Kailkhura, S. Brahma, Y . S. Han, and P . K. V arshney , “Distributed Detection in Tree T opologies With Byzantines, ” IEEE T rans. Signal Pr ocess. , vol. 62, pp. 3208–3219, June 2014. [10] B. Kailkhura, S. Brahma, and P . K. V arshney , “Optimal Byzantine Attack on Distributed Detection in T ree based T opologies, ” in Proc. International Conference on Computing, Networking and Communications W orkshops (ICNC-2013) , San Diego, CA, January 2013, pp. 227–231. [11] B. Kailkhura, S. Brahma, Y . S. Han, and P . K. V arshney , “Optimal Distributed Detection in the Presence of Byzantines, ” in Pr oc. The 38th International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP 2013) , V ancouver , Canada, May 2013. [12] A. V empaty , K. Agrawal, H. Chen, and P . K. V arshney , “Adapti ve learning of Byzantines’ behavior in cooperative spectrum sensing, ” in Proc. IEEE W ireless Comm. and Networking Conf. (WCNC) , march 2011, pp. 1310 –1315. [13] R. Chen, J.-M. Park, and K. Bian, “Robust distributed spectrum sensing in cognitiv e radio networks, ” in Pr oc. 27th Conf. Comput. Commun., Phoenix, AZ , 2008, pp. 1876–1884. [14] E. Soltanmohammadi, M. Orooji, and M. Naraghi-Pour, “Decentralized Hypothesis T esting in Wireless Sensor Networks in the Presence of Misbehaving Nodes, ” IEEE T rans. Inf. F orensics Security , vol. 8, no. 1, pp. 205–215, 2013. [15] B. Kailkhura, Y . Han, S. Brahma, and P . V arshney , “On Covert Data Falsification Attacks on Distrib uted Detection Systems, ” in Communications and Information T echnologies (ISCIT), 2013 13th International Symposium on , Sept 2013, pp. 412–417. [16] J. N. Tsitsiklis, “Decentralized Detection by a Large Number of Sensors*, ” Math. control, Signals, and Systems , vol. 1, pp. 167–182, 1988. [17] H. Chernoff, “A Measure of Asymptotic Efficiency for T ests of a Hypothesis Based on the sum of Observations, ” The Annals of Mathematical Statistics , vol. 23, pp. 493–507, December 1952. DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment