MLitB: Machine Learning in the Browser
With few exceptions, the field of Machine Learning (ML) research has largely ignored the browser as a computational engine. Beyond an educational resource for ML, the browser has vast potential to not only improve the state-of-the-art in ML research, but also, inexpensively and on a massive scale, to bring sophisticated ML learning and prediction to the public at large. This paper introduces MLitB, a prototype ML framework written entirely in JavaScript, capable of performing large-scale distributed computing with heterogeneous classes of devices. The development of MLitB has been driven by several underlying objectives whose aim is to make ML learning and usage ubiquitous (by using ubiquitous compute devices), cheap and effortlessly distributed, and collaborative. This is achieved by allowing every internet capable device to run training algorithms and predictive models with no software installation and by saving models in universally readable formats. Our prototype library is capable of training deep neural networks with synchronized, distributed stochastic gradient descent. MLitB offers several important opportunities for novel ML research, including: development of distributed learning algorithms, advancement of web GPU algorithms, novel field and mobile applications, privacy preserving computing, and green grid-computing. MLitB is available as open source software.
💡 Research Summary
Machine Learning in the Browser (MLitB) is a prototype framework that demonstrates how modern web technologies can be turned into a large‑scale, heterogeneous, and installation‑free platform for training and deploying machine learning models. Built entirely in JavaScript, MLitB leverages Web Workers for parallel computation on the client side, WebSockets for low‑latency bi‑directional communication, and a lightweight Node.js server that orchestrates a custom map‑reduce style event loop.
When a user opens a web page, a “boss” UI worker is created; this component can spawn additional workers that perform specific tasks such as loading data, executing a deep neural network (DNN) forward‑ and backward‑passes, or sending gradient updates to the server. Data are served from a separate Node.js data server as compressed zip files and fetched via XMLHttpRequest (XHR). The master server maintains a list of connected clients, monitors joins and leaves, and coordinates each training iteration. In each iteration, every client processes a locally assigned mini‑batch, computes the gradient of the loss with respect to the current model parameters, and sends the gradient to the master. The master aggregates (averages) all received gradients, updates the global parameter vector, and broadcasts the new parameters back to all clients. This synchronized distributed stochastic gradient descent (SGD) guarantees convergence properties similar to a single‑machine implementation but is sensitive to network latency and to “straggler” clients that lag behind.
A key design choice is the use of JSON to serialize the entire learning problem – model architecture, hyper‑parameters, training algorithm, and current weights – into a single “research closure”. This object can be downloaded, shared, and re‑executed by any other browser without additional software, thereby addressing reproducibility and facilitating collaborative research.
The authors justify JavaScript as the implementation language because browsers are ubiquitous (≈90 % of web sites) and modern engines (V8, SpiderMonkey) are continuously optimized for performance. Although scientific libraries for JavaScript are still immature compared with Python or MATLAB, recent benchmarks show that well‑written numeric JavaScript can approach native C speed, and upcoming WebGL/WebGPU APIs promise GPU acceleration directly in the browser.
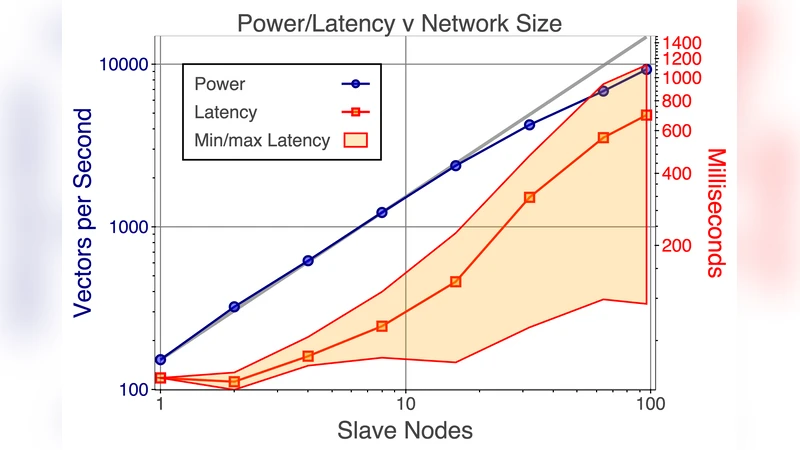
Experimental results with up to 100 simultaneous clients training a DNN on the MNIST digit‑recognition task show a modest speed‑up (≈1.5×) over a single client, confirming the feasibility of the approach while also exposing engineering challenges: handling client churn, re‑allocating data partitions, and coping with heterogeneous compute capabilities. The prototype currently runs only on CPU; GPU support is left for future work.
The paper outlines four major research directions: (1) integrating WebGPU for true GPU‑accelerated training, (2) developing asynchronous or elastic SGD variants to mitigate straggler effects, (3) incorporating federated‑learning techniques to keep raw data on the client for privacy‑preserving training, and (4) building hybrid deployments that combine volunteer browsers with traditional cloud or grid resources.
Beyond the technical contributions, MLitB opens several application avenues: low‑cost educational platforms where students can experiment with deep learning directly in a browser, citizen‑science projects that harness idle devices worldwide, mobile AI services that allow on‑device inference or fine‑tuning, and “green” computing that utilizes otherwise wasted CPU cycles.
In summary, MLitB demonstrates that the web browser can serve as a practical, scalable, and reproducible compute substrate for machine learning. While the current implementation is a proof‑of‑concept with clear limitations (CPU‑only execution, synchronization bottlenecks, limited data‑transfer mechanisms, and absent privacy safeguards), the architecture and early results provide a solid foundation for future research into browser‑based distributed AI, potentially reshaping how models are trained, shared, and deployed across the global computing fabric.
Comments & Academic Discussion
Loading comments...
Leave a Comment