Structural and Functional Discovery in Dynamic Networks with Non-negative Matrix Factorization
Time series of graphs are increasingly prevalent in modern data and pose unique challenges to visual exploration and pattern extraction. This paper describes the development and application of matrix factorizations for exploration and time-varying co…
Authors: Shawn Mankad, George Michailidis
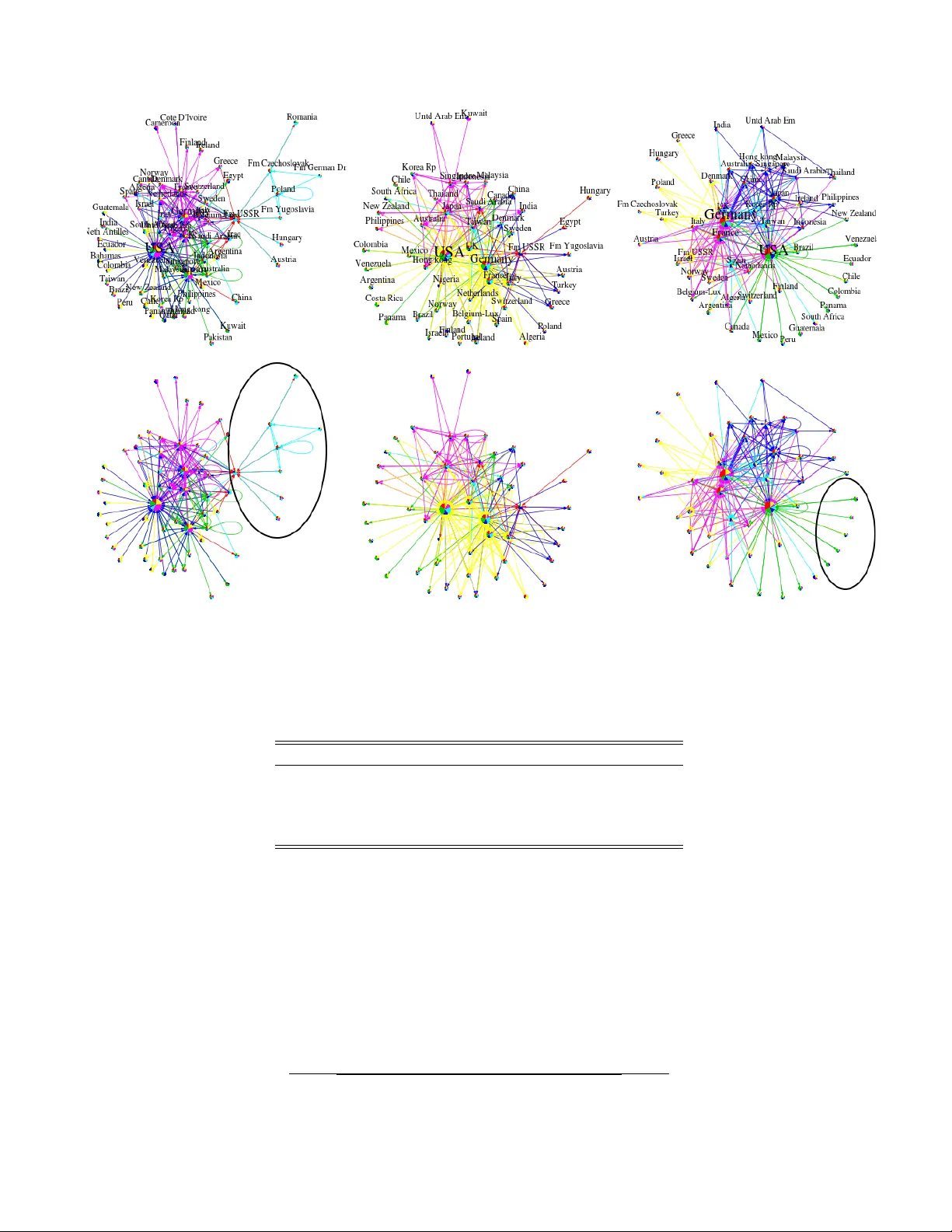
Structural and F unctional Disco v ery in Dynamic Net w orks with Non-negativ e Matrix F actorization Sha wn Mank ad and George Michailidis Statistics Dep artment, University of Michigan Time series of graphs are increasingly prev alent in modern data and p ose unique c hallenges to visual exploration and pattern extraction. This paper describes the dev elopment and application of matrix factorizations for exploration and time-v arying comm unity detection in time-ev olving graph sequences. The matrix factorization mo del allo ws the user to home in on and display interesting, underlying structure and its evolution ov er time. The metho ds are scalable to weigh ted netw orks with a large num ber of time points or nodes, and can accommodate sudden changes to graph top ology . Our techniques are demonstrated with several dynamic graph series from b oth synthetic and real world data, including citation and trade net works. These examples illustrate ho w users can steer the tec hniques and combine them with existing metho ds to discov er and display meaningful patterns in sizable graphs ov er many time points. I. INTR ODUCTION Due to adv ances in data collection tec hnologies, it is b ecoming increasingly common to study time series of net works. An imp ortan t research question is how to dis- co ver the underlying structure and dynamics in time- v arying net work ed systems. In this work, we propose a new matrix factorization-based approac h for commu- nit y disco very and visual exploration within p oten tially w eighted and directed netw ork time-series. Next, we re- view and discuss this w ork in relation to p opular ap- proac hes for addressing the k ey problems of communit y detection and visualization of time series of netw orks. There ha ve b een man y imp ortant contributions for comm unity detection in netw ork time-series, extensively review ed in [ 1 , 2 ], from the fields of physics, computer science and statistics. The basic goal of comm unity de- tection is to extract groups of nodes that feature rela- tiv ely dense within group connectivity and sparser be- t ween group connections [ 3 , 4 ]. A common strategy is to embed the graphs in low-dimensional latent spaces. F or instance, [ 5 ] use latent v ariables to capture groups of pap ers that ev olve similarly in citation netw ork data. [ 6 ] extend to the dynamic setting a p opular latent space mo del for static data [ 7 ] by utilizing smo othness con- strain ts to preserve the co ordinates of the no des in the laten t space ov er time. This article also utilizes a simi- lar lo w-dimensional em b edding strategy . A k ey difference b et w een this w ork and [ 6 ] is that comm unity mem b ership itself is sub ject to smo othness conditions in our appr oach, hence remo ving the need for a tw o stage pro cedure. This article is also in con trast to previous w orks that use temporal smo othness constrain ts for non-o verlapping (hard) communit y detection [ 8 ], estimating time-v arying net work structure from cov ariate information [ 9 ], predict- ing netw ork (link) structure [ 10 ], or anomaly detection [ 11 , 12 ]. A sequence of non-negative factorizations discov ers o verlapping communit y structure, where no de partici- pation within each communit y is quantified and time- v arying. Other works that consider a single netw ork cross-section ha v e sho wn adv antages of NMF for comm u- nit y detection [ 13 , 14 ]. In addition to a quantification of ho w strongly each no de participates in each communit y , NMF do es not suffer from the drawbac ks of mo dularit y optimization metho ds, such as the resolution limit [ 15 ]. W e also use the NMF to transform the time series of net works to a time-series for eac h no de, whic h can be used to create an alternativ e to graph dra wings for vi- sualization of no de dynamics. Much of the visualization literature aims to enhance static graph drawing meth- o ds with animations that mo v e no des (v ertices) as lit- tle as p ossible betw een time steps to facilitate readabil- it y [ 16 ]. Ho wev er, the reliabilit y of these metho ds rely on the h uman ability to p erceiv e and remember changes [ 17 ]. Moreo v er, exp erimen ts ha ve disco vered that the ef- fectiv eness of dynamic lay outs are strongly predicted b y no de sp eed and target separation [ 18 ]. Th us, dynamic graph dra wings encoun ter difficulties when faced with a large n umber of time p oin ts, larger graphs that feature abrupt, non-smooth c hanges, or if the user is in terested in detailed analysis, esp ecially at the individual node level (see Section 3.2 of [ 19 ], [ 20 , 21 ]). On the other hand, static displa ys facilitate detailed analysis and av oid diffi- culties asso ciated with animated la y outs. This highligh ts a main adv antage our NMF mo del, namely creating static displa ys of no de evolutions. The remainder of this article is organized as follows: in the next section, we in tro duce a mo del for static netw ork data in Section I I , follow ed b y an extension for dynamic net works in Section I II . W e then test the matrix factor- ization mo del on sev eral synthetic and real-w orld data sets in Section IV . In Section V , we close the article with a brief discussion. I I. NMF FOR NETWORK CROSS-SECTIONS The most common factorization is the Singular V alue Decomp osition (SVD), which has imp ortan t connections to communit y detection, graph drawing, and areas of statistics and signal proce ssing [ 22 ]. F or instance in clas- 2 sical sp ectral la yout, the co ordinates of each no de are giv en by the SVD of graph related matrices, and can b e calculated efficiently using algorithms in [ 23 , 24 ]. Re- cen tly , there has b een extensive interest in sp ectral clus- tering [ 25 – 27 ], whic h aims to discov er comm unit y struc- ture in eigenv ectors of the graph Laplacian matrix. The metho d proposed in this pap er is similar in spirit, as it also relies on low rank appro ximations to adjacency matrices (instead of Laplacian matrices). Ho w ever, w e searc h for low-rank approximations that satisfy different (relaxed) constraints than orthonormality , namely , that the approximating decomp ositions are comp osed of non- negativ e entries. Such factorizations, referred to as NMF, ha ve b een shown to b e adv antageous for visualization of non-negativ e data [ 28 – 31 ]. Non-negativit y is typically satisfied with net works, as edges commonly correspond to flows, capacity , or binary relationships, and hence are non-negativ e. NMF solutions do not hav e simple expres- sions in terms of eigenv ectors. They can, ho wev er, be efficien tly computed by form ulating the problem as one of p enalized optimization, and using modern gradien t- descen t algorithms. Recently , theoretical connections be- t ween NMF and imp ortant problems in data mining hav e b een developed [ 32 , 33 ], and accordingly , NMF has b een prop osed for o verlapping comm unity detection on static [ 13 , 14 ] and dynamic [ 34 ] netw orks . With NMF a given adjacency matrix is appro ximated with an outer pro duct that is estimated through the fol- lo wing minimization min U ≥ 0 ,V ≥ 0 || A − U V T || 2 F , (1) where A is the n × n adjacency matrix, and U and V are b oth n × K matrices with elements in R + . The rank or dimension of the approximation K corresp onds to the n umber of comm unities, and is c hosen to obtain a go o d fit to the data while ac hieving in terpretability . An in- teresting fact ab out NMF is that the estimates are al- w ays rescalable (scale inv arian t). F or example, w e can m ultiply U by some constant c and V by 1 /c to obtain differen t U, V estimates without changing their product U V T . Th us, as seen by the rotational indeterminancy and multiplicativ e nature of the factorization, NMF is an under-constrained mo del. It is, how ev er, straightforw ard to interpret the esti- mates due to non-negativity . F or instance, ( U ) ik ( V ) j k can b e interpreted as the con tribution of the k th cluster to the edge ( A ) ij . In other words, the exp ected in terac- tion ( ˆ A ) ij = P K k =1 ( U ) ik ( V ) j k b et w een no des i and j is the result of their mutual participation in the same com- m unities [ 13 ]. Such an edge decomp osition can then b e used to assign no des to communities. F or instance, one can proceed b y first assigning all edges to the commu- nit y with largest relative contribution. Then, no des are assigned to comm unities according to the prop ortion of its edges that b elong to each comm unity . W e note that with an NMF-based metho dology , the adjacency matrix can b e w eighted (non-negatively), a potentially app ealing feature since many existing analysis tools are arguably only compatible with net works of binary relations. Though it is not explicitly controlled, standard NMF tends to estimate sparse comp onents. Beyond the ad- ditional in terpretability that sparsit y pro vides, w e find further motiv ation to encourage sparsity of the NMF es- timate when w orking with netw orks. F or instance, sup- p ose ( A ) ij =0 for some i, j , that is, there is an absense of an edge b et w een no des i and j . In the low rank approx- imation there is no guaren tee that ( ˆ A ) ij = 0, though w e exp ect it to b e near zero. A straightforw ard wa y to force ( ˆ A ) ij exactly to zero is b y anc horing ( U ) ik = ( V ) j k = 0 for all k , and estimating the remaining elemen ts of U and V b y the algorithm provided b elo w (see [ 35 ] for a similar strategy for m ultidimensional scaling). Ho wev er, anc horing is not appropriate with rep eated or sequential observ ations, as an edge can appear and disapp ear due to noise. Keeping in mind the extension to sequences of net- w orks in the next section, we instead encourage sparsity in the form of an l 1 p enalt y . The factorized matrices are obtained through minimiz- ing an ob jective function that consists of a go o dness of fit comp onen t and a roughness p enalty min U ≥ 0 ,V ≥ 0 || A − U V T || 2 F + λ s K X k =1 || V k || 1 , (2) where the parameter λ s ≥ 0. The strength of the penalty is set b y the user to steer the analysis, where a larger p enalt y encourages sparser V . Adding penalties to NMF is a common strategy , since they not only improv e in ter- pretabilit y , but often improv e numerical stabilit y of the estimation by making the NMF optimization less under- constrained. [ 36 – 40 ] and references therein review im- p ortan t penalized NMF mo dels (see [ 41 – 43 ] for similar approac hes with SVD). An adv antage of an NMF-based approach is that it is easy to modify for particular datasets. F or example, a similar l 1 p enalt y can be included on U if the ro wspace (t ypically out-going edges) are of interest. The estimation algorithm we present is similar to the b enc hmark algorithm for NMF, known as ‘multiplicativ e up dating’ [ 28 , 29 ]. The algorithm can b e viewed as an adaptiv e gradient descen t. It is relatively simple to im- plemen t, but can conv erge slowly due to its linear rate [ 44 ]. In practice w e find that after a handful of itera- tions, the algorithm results in visually meaningful fac- torizations. The estimation algorithm for the p enalized NMF in Eq. 2 is studied in [ 38 ] and [ 39 ], and the main deriv ation steps we present next follow these works. First, to enforce the non-negativity constrain ts, we consider the Lagrangian L = || A − U V T || 2 F + λ s K X k =1 || V k || 1 (3) + T r (Φ U T ) + T r (Ψ V T ) , where Φ , Ψ are Lagrange multipliers. 3 T o dev elop a mo dern gradien t descen t algorithm, w e emplo y the following Karush-Kuhn-T uck er (KKT) opti- malit y conditions, whic h pro vide necessary conditions for a lo cal minimum [ 45 ]. The KKT optimalit y conditions are obtained b y setting ∂ L ∂ U = ∂ L ∂ V = 0. Φ = − 2 AV + 2 U V T V (4) Ψ = − 2 A T U + 2 V U T U + 2 λ s . (5) Then, the KKT complimentary slac kness conditions yield 0 = ( − 2 AV + 2 U V T V ) ij ( U ) ij (6) 0 = ( − 2 A T U + 2 V U T U + 2 λ s ) ij ( V ) ij , (7) whic h, after some algebraic manipulation, lead to the m ultiplicative up date rules shown in Algo. 1 . The al- gorithm has some notable theoretical prop erties. Sp ecif- ically , each iteration of the algorithm will pro duce esti- mates that reduce the ob jectiv e function v alue, e.g., the estimates impro ve at each iteration. Minor modifications pro vided in [ 46 ] can be emplo yed to guarantee conv er- gence to a stationary p oint. 1: Set constant λ s 2: Initialize { U, V } as dense, p ositiv e random matrices 3: rep eat 4: Set ( U ) ij ← ( U ) ij ( AV ) ij ( U V T V ) ij 5: Set ( V ) ij ← ( V ) ij ( A T U ) ij ( V U T U ) ij + λ s 6: until Conv ergence ALGORITHM 1. Sparse NMF Lastly , w e note that when the observed graph is undi- rected, due to symmetry of the adjacency matrix the fac- torization can b e written as A ≈ U Λ U T , (8) where Λ is a non-negative diagonal matrix. This is the underlying mo del in vestigated in F acetnet [ 34 ], with ad- ditional constrain ts on U to satisfy an underlying prob- abilistic int erpretation. The ob jective function consid- ered in [ 34 ] w as also based on relativ e entrop y or KL- div ergence. W e find that suc h symmetric NMF mo d- els are far more sensitive to additional constraints than its general counterpart, esp ecially when dealing with se- quences of net works as in the next section. Symmet- ric NMF has less flexibility , since additional constraints strongly influence the reconstruction accuracy of the esti- mation. On the other hand, without imp osing symmetry , as V c hanges, U compensates (and vice versa) in order for the final pro duct to reproduce the data as best as p ossible. Thus, for tasks of visualization of no de ev olu- tion and communit y extraction in dynamic netw orks, we do not imp ose symmetry on the factorization. A. Illustrativ e Examples 1. Community Discovery on a T oy Example W e compare the following metho ds on a to y example sho wn in Fig. 1 . 1. Leading eigenv ector (mo dularity) based comm u- nit y discov ery [ 47 ] 2. Sp ectral clustering [ 26 ] 3. Clique p ercolation [ 48 ] for ov erlapping comm unity disco very 4. Classical NMF (Eq. 1 ) 5. Sparse NMF (Eq. 2 ) The results of the alternative metho dologies are pro- vided in Fig. 2 , where we see that ev en on this to y ex- ample, there is disagreement in the reco v ered comm u- nit y structure. The leading eigenv ector solution differs sligh tly from that of sp ectral clustering. T ak en together, one ma y susp ect a soft partitioning would result in o ver- lap b etw een the green and red communities. Y et, clique p ercolation finds ov erlap b etw een the blue and red com- m unities. Classical NMF finds o v erlap b etw een all three comm unities, quantifies the amount of o verlap (denoted b y the pie c hart on each no de), and decomposes eac h edge b y communit y (colored as a mixture of red, green and blue). Fig. 3 shows that sparse NMF finds a cleaner structure compared to classical NMF. In particular, the sparse NMF solution has less o verlap (mixing) b et w een the three groups, while still quantifying comm unity con- tribution to no des and edges. 2. R ank One F actorizations W e show in our exp eriments (Section IV ) that a se- quence of rank one matrix factorizations can b e the basis for informativ e displays of time-v arying node imp ortance to connectivit y . T o provide some in tuition as to why such a rank one factorization is informativ e, consider Fig. 4 , whic h shows graph structures, corresp onding NMFs, and Klein b erg’s authorit y and h ub scores [ 49 ]. Authorit y and h ub scores are computed b y the leading eigenv ector of A T A and AA T , resp ectively . Sub ject to rescaling of the NMF estimates, the results are iden tical. In fact, by the P erron-F robenius theorem (see Chapter 8 of [ 50 ]), the rank one NMF solution is alwa ys a rescaled v ersion of authorit y and h ub scores. This provides a natural in- terpretation for the rank one NMF. F or instance, the U v ector on the Star Net w ork highlights the hub no de. The V v ector show that all p eripheral no des are equal in terms of their authority (incoming connections), and that the cen tral node has no incoming connections. NMF v ec- tors of the Ring Netw ork sho w eac h no de with an equal 4 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● FIG. 1. An undirected netw ork with 19 no des. score for incoming (authorit y) and outgoing (hub) con- nectivit y . The fact that U con tains larger elemen ts than V is arbitrary . Ho wev er, the assignment of equal v alues within U and V shows eac h no de is equally imp ortan t to in terconnectivity . I II. MODEL F OR D YNAMIC NETWORKS Giv en a time series of net works {G t = ( V t , E t ) } T t =1 with corresp onding adjacency matrices { A t } T t =1 , the goal is to produce a sequence of low rank matrix factorizations { U t , V t } T t =1 . T o extend the factorization from the previous section to the temp oral setting, w e imp ose a smo othness con- strain t on the basis U t . This constrain t forces new com- m unity structure to be similar to previous time p oints. Since individual node time-series given b y U t are visually smo oth, time plots for eac h node become informativ e and pro vide an alternative to graph drawings for visualizing no de dynamics. Moreov er, time plots are static displays, whic h facilitate detailed analysis and av oid difficulties as- so ciated with animated la youts when given a large num- b er of time p oints or no des. The ob jective function b ecomes min { U t ≥ 0 ,V t ≥ 0 } T t =1 T X t =1 || A t − U t V T t || 2 F (9) + λ t T X t =1 t + W 2 X ˜ t = t − W 2 || U t − U ˜ t || 2 F + λ s T X t =1 K X k =1 || V t,k || 1 , where W is a small in teger represen ting a time window. The parameters λ t , λ s and W are set by the user to steer the analysis. The in terpretations of U t , V t extend naturally from the previous section, so that, for instance, P k ( V t ) kj mea- sures the imp ortance of no de j (typically corresp onding to incoming edges), and ( U t ) ik ( V t ) j k / P K k =1 ( U t ) ik ( V t ) j k to measure the relativ e con tribution of eac h communit y to eac h i, j edge. In principle, the edge decomp osition can b e used to assign no des to communities as discussed in the last section. How ever, this approach can b e un- satisfactory due to unstable comm unity assignments. As alternativ e method is to assign communities in terms of U t , which ensures the stability of the communit y struc- ture through time. Specifically , measuring the contribu- tion of no de i to eac h comm unity with the relative mag- nitude of the i th elemen t of eac h dimension of U t , e.g., ( U t ) ik / P K k =1 ( U t ) ik . W e can follow similar steps as in the last section to deriv e a gradient descent estimation algorithm. First, to enforce the non-negativit y constraints, we consider the Lagrangian L = T X t =1 || A t − U t V T t || 2 F (10) + λ t T X t =1 t + W 2 X ˜ t = t − W 2 || U t − U ˜ t || 2 F + λ s T X t =1 n X i =1 K X j =1 | V t ( i, j ) | + T X t =1 T r (Φ t U T t ) + T X t =1 T r (Ψ t V T t ) , where Φ t , Ψ t are Lagrange m ultipliers. The follo wing KKT optimalit y conditions are obtained b y setting ∂ L ∂ U t = ∂ L ∂ V t = 0. Φ t = − 2 A t V t + 2 U t V T t V t − 2 λ t t − 1 X ˜ t = t − W 2 U ˜ t (11) − 2 λ t t + W 2 X ˜ t = t +1 U ˜ t + 2 W λ t U t Ψ t = − 2 A T t U t + 2 V t U T t U t + 2 λ s . (12) 5 Leading eigenv ector Sp ectral clustering Clique p ercolation Classical NMF ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● FIG. 2. (Color online) Results using alternative communit y discov ery metho ds. FIG. 3. (Color online) Results from applying sparse NMF (Algo. 1 ) with λ s = 5. Nodes and edges are colored to denote the relative contribution of each communit y . Then, the KKT complimentary slac kness conditions yield 0 = ( − 2 A t V t + 2 U t V T t V t − 2 λ t t − 1 X ˜ t = t − W 2 U ˜ t ) ij ( U t ) ij (13) + ( − 2 λ t t + W 2 X ˜ t = t +1 U ˜ t + 2 W λ t U t ) ij ( U t ) ij 0 = ( − 2 A T t U t + 2 V t U T t U t + 2 λ s ) ij ( V t ) ij , (14) whic h after some algebra leads to the algorithm pro vided in Algo. 2 . The theoretical properties are also the same as in the previous section. Most notably , the estimates of U t and V t will impro v e at each iteration with resp ect Star Netw ork Ring Netw ork Adjacency Matrix 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 1 0 0 0 1 0 1 0 0 0 1 0 1 1 0 0 1 0 NMF U, V 1 . 00 0 . 00 0 . 00 0 . 00 0 . 00 0 . 00 1 . 00 1 . 00 1 . 00 1 . 00 0 . 89 0 . 89 0 . 89 0 . 89 0 . 89 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 Hub, Authority 1 . 00 0 . 00 0 . 00 0 . 00 0 . 00 0 . 00 0 . 50 0 . 50 0 . 50 0 . 50 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 0 . 45 FIG. 4. Rank 1 NMF without penalization and Kleinberg’s authorit y/hub scores [ 49 ]. to Eq. 9 . A. P arameter Selection W e briefly discuss the imp ortant practical matter of c ho osing K , the inner rank of the matrix factorization. F or the goal of clustering, the rank should b e equal to the n um b er of underlying groups. The rank can be ascer- tained by examining the accuracy of the reconstruction as a function of rank. Ho wev er, this tends to rely on sub jective judgments and ov erfit the given data. Cross v alidation based approaches are theoretically preferable and follo w the same intuition. The idea b ehind cross v alidation is to use random sub- sets of the data from each data slice to fit the model, and another subset from each data slice to assess accuracy . Differen t v alues of K are then cycled ov er and the one 6 1: Set constants λ t , λ s , W . 2: Initialize { U t } , { V t } as dense, p ositiv e random matrices. 3: rep eat 4: for t=1..T do 5: Set 6: ( U t ) ij ← ( U t ) ij ( A t V t + λ t P t − 1 ˜ t = t − W 2 U ˜ t + λ t P t + W 2 ˜ t = t +1 U ˜ t ) ij ( U t V T t V t + W λ t U t ) ij . 7: Set ( V t ) ij ← ( V t ) ij ( A T t U t ) ij ( V t U T t U t ) ij + λ s . 8: end for 9: until Conv ergence ALGORITHM 2. NMF with temp oral and sparsity p enalties that corresp onds to the low est test error is chosen. Due to the data structure, w e emplo y tw o-dimensional cross v alidation. Tw o-dimensional refers to the selection of submatric es for our training and test data. Sp ecial care is tak en to ensure that the same rows and columns are held out of every data slice, and the dimensions of the training and test sets are identical. The hold out pattern divides the rows in to k groups, the columns into l groups, then uses the corresponding k l submatrices to fit and test the mo del. In eac h submatrix, the giv en ro w and column group iden tifies a held out submatrix that is used as test data, while the remaining cells are used for training. The algorithm is sho wn in Algo. 3 . The notation in the algorithm uses I l and I J as index sets to iden tify submatrices in the each data matrix. 1: F orm row holdout set: I l ⊂ { 1 , .., n } 2: F orm column holdout set: I J = ⊂ { 1 , .., n } 3: Set ( ˜ U t , ˜ V t ) = arg min U t ,V t ≥ 0 X t || ( A t ) −I l , −I J − U t V T t || 2 F 4: Set ˘ U t = arg min U t ≥ 0 X t || ( A t ) I l , −I J − U t ˜ V T t || 2 F 5: Set ˘ V t = arg min V t ≥ 0 X t || ( A t ) −I l , I J − ˜ U t V T t || 2 F 6: Set ˆ ( A t ) I l , I J = ˘ U t ˘ V T t 7: Compute T est error T est Error = X t || ( A t ) I l , I J − ˆ ( A t ) I l , I J || 2 F ALGORITHM 3. Cross-v alidation for choosing the n umber of communities (rank) W e then cycle o ver different v alues of K to choose the ● ● ● ● ● ● ● ● A vg T est Error Inner Rank 1 2 3 4 5 6 7 8 20 22 24 26 28 30 FIG. 5. Cross v alidation indicates 3 communities (rank 3) features the low est av erage test error for the toy example. one that minimizes av erage test error. Fig. 5 shows that this pro cedure correctly iden tifies 3 comm unities for the to y example. Consistency results are dev elop ed in [ 51 ] to pro vide theoretical foundations for this approach. In principle the cross v alidation pro cedure can b e used to select the p enalties λ t , λ s and the time window W . Ho wev er, considering the scale of many mo dern net work datasets, this would require too m uch computing time. Instead we typically choose the p enalties by hand to em- phasize readability and interpretabilit y of the results, k eeping in mind that if either p enalty is set too large then the estimation results in degenerate solutions. F or instance, the algorithm suffers from numerical instabili- ties when λ s is too large, since all V t elemen ts are zero. If λ t is set to an extremely large num b er, then U t will b e appro ximately constant for all time p erio ds, so the effec- tiv e mo del is A t ≈ U V T t , e.g., the communit y structure is fixed for all observ ations. The parameter, W , controls the num b er of neighbor- ing time steps to locally a verage. Larger v alues of W mean that the mo del has more memory so it incorp o- rates more time p oints for estimation. This risks missing sharp er changes in the data and only detecting the m ost p ersisten t patterns. On the other hand, small v alues of W make the fitting more sensitive to sharp changes, but increase short term fluctuations due to smaller num b er of observ ations. W e set W = 2 (lo oking one time p erio d ahead and before) for all presen ted exp erimen ts. Larger v alues could b e used in very noisy settings to further smo oth results. 7 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● FIG. 6. The cell phone netw ork from a da y using a force di- rected lay out algorithm in igraph. Node 200 is colored black. IV. EXPERIMENTS In this section we test the mo del on both syn thetic and real-world examples. The syn thetic net works allo w us to v alidate the mo del’s ability to highligh t kno wn com- m unity structure and no de evolution, while the real ex- amples exhibit the mo del’s p erformance under practical conditions. A. Syn thetic Net w orks 1. Catalano Communication Network The first example utilizes the Catalano so cial netw ork, whic h w as part of the Visual Analytics Science and T ec h- nology (V AST) 2008 c hallenge [ 52 ]. The synthetic data consists of 400 unique cell phone IDs o v er a ten day p e- rio d. Altogether, there are 9834 phone records with the follo wing fields: calling phone iden tifier, receiving phone iden tifier, date, time of day , call duration, and cell tow er closest to the call origin. The purp ose of the challenge w as to c haracterize the so cial structure o ver time for a fictitious, contro versial socio-p olitical mov emen t. In par- ticular, the c hallenge requires iden tifying five key indi- viduals that organize activities and c omm unications for the netw ork; a hint was given to c hallenge participants that no de 200 is one of the p ersons of interest. W e use the first sev en days of data to illustrate our metho dology , since there is a strong change in the connec- tion patterns from da y 8-10 for node 200 (see [ 52 , 53 ] and references therein). Directed netw orks are constructed daily by drawing an edge from the caller to the receiver. Fig. 6 shows an example of one da y’s net work. The graph is too cluttered to visually iden tify leaders of the netw ork or get a sense of the netw ork structure. W e fit a sequence of rank 5 NMFs, as identified in Fig. 7 through cross v alidation, with a large temp oral p enalty to highlight the most p ersistent in teractions. Fig. 8 shows t wo sets of graph drawings for three days (due to space limitations), with the no des colored according to their comm unity membership. The first ro w sho ws the graph constructed directly from the data, while the second row sho ws graph drawings of the fitte d model ˆ A = U t V T t . The clustering results applied to the ra w data are not in terpretable, as the data is simply to o cluttered. How- ev er, the p ersons of interest and the hierarchical struc- ture of the communication net work are clearly shown when considering the fitted netw orks. One can visually iden tify that no de 200 consistently relays information to his neighbors (1,2,3,5), who disseminate information to their respective sub ordinates. W e can also see that nodes higher up on the organizational hierarch y tend to b elong to multiple communities, presumably since they dissem- inate information to differen t groups of sub ordinates. Fig. 9 shows the results of applying F acetnet [ 34 ], an alternativ e NMF methodology for dynamic ov erlapping comm unity detection. F acetnet applies an underlying mo del with less flexibility resulting in po or reconstruc- tions of the data, as seen in the fitted net works. W e also collapse the data into a single netw ork snapshot in order to apply static clustering algorithms. First, an edge is k ept only if it was observ ed more than Thr eshold days. Then, sp ectral clustering and clique p ercolation are ap- plied to the resultan t net work snapshot. All alternative metho ds struggle, as the data is to o ‘hairball’ like. On the other hand, the fitted p enalized NMF mo del pro vides a unified framework to filter the netw ork and visualize com- m unity structure. V AST nev er officially released correct answ ers for the challenge. Ho wev er, our analysis closely matc hes winning entries [ 53 – 55 ]. T reating the conclu- sions of the entries as ground truth, we hav e pro vided a simple workflo w that uncov ers patterns in the data that are not directly obtainable with traditional metho ds. 2. Pr efer ential Attachment Pr oc ess In this simulation, no des attach according to a prefer- en tial attachmen t mo del [ 56 , 57 ] until 10000 no des hav e ’attac hed’ to the embedding. W e observe this gro wing pro cess at 100 uniformly spaced time p oin ts. Thus, at eac h time point 100 new no des attach to the graph. W e use source co de from a netw orks MA TLAB to olb o x [ 58 ] that generates preferen tial attachmen t graphs according to the standard mo del. In the preferential attac hment model, Π( i ), which rep- resen ts the probability that a new no de connects to no de i , dep ends on no de i ’s degree. Sp ecifically , we hav e Π( i ) ∝ d i (15) where d i is the degree of the ith node. This generat- 8 ● ● ● ● ● ● ● ● ● ● A verage RSS Inner Rank 2 4 6 8 10 500 520 540 560 580 600 ● ● ● ● ● ● ● ● ● ● A vg T est Error Inner Rank 2 4 6 8 10 25.10 25.15 25.20 25.25 25.30 25.35 25.40 FIG. 7. Cho osing K for the Catalano communications netw ork. The left panel shows the av erage residual sum of squares, and the righ t panel shows the a verage test error obtained via cross v alidation (5 × 5 fold) for different the appro ximation ranks. Cross v alidation indicates that 5 communities is optimal. Da y 5 Da y 6 Da y 7 Ra w 3 1 5 200 2 3 1 5 200 2 3 1 5 200 2 Fitted 3 1 5 200 2 3 1 5 200 2 3 1 5 200 2 FIG. 8. (Color online) The raw (top row) and filtered Catalano netw orks (b ottom row) colored by the U t comm unity structure. A force directed lay out in igraph was used to create this embedding. No des are colored by soft partitioning via the p enalized NMF. ing framew ork leads to net w orks whose asymptotic de- gree distribution follo ws a p o wer-la w distribution with parameter γ = 3. Graphs with heavy-tailed degree dis- tributions are commonly observed in a v ariety of areas, suc h as the Internet, protein interactions, citation net- w orks, among others [ 59 ]. In practice, an analyst would not know that the data comes from a preferen tial attac hment pro cess. In which case, an exploratory analysis may include insp ecting the net work sequence on a set of standard metrics (degree, 9 Da y 5 Da y 6 Da y 7 Ra w 3 1 5 200 2 3 1 5 200 2 3 1 5 200 2 Fitted 1 5 200 FIG. 9. (Color online) Results of applying the F acetnet factorization [ 34 ] with a prior weigh t of λ = 0 . 8. The raw (top row) and filtered Catalano netw orks (b ottom row) colored by the F acetnet factorization. transitivit y , centralit y , etc.), graph drawings, as well as comm unity detection approaches. W e b eliev e that a se- quence of one-dimensional ( K = 1) p enalized NMFs can serv e as the basis for a complimen tary exploratory to ol that helps uncov er different connectivit y patterns and ev olution in the data. In particular, due to the smo oth- ness p enalty , time plots in U t for each no de b ecome use- ful for uncov ering the num b er and t yp es of no de evo- lutions in the data. Similarly , heatmaps or displa ys of the sparsity pattern of V t are useful to identify when no des/groups b ecome significantly active. Since preferential attachmen t net works hav e b een ex- tensiv ely studied, we sho w only the NMF-based displays. Fig. 11 sho ws important (hub) no des that distinct tra- jectories that indicate their increasing imp ortance to the net work ov er time. The V t sparsit y features a pseudo- upp er triangular form. This corresp onds to the no de attac hment order and reflects that no des p ermanen tly attac h after connecting to the netw ork. Suc h displa ys can b e created quickly and can help the pro cess of iden- tifying interesting no des, formulating researc h questions, and so on. Also shown in Fig. 11 is that p enalization is imp ortant to the usefulness and interpretabilit y of the displays. F or instance, without a temp oral p enalt y , the time plots em- phasize only the highest degree no de. With appropriate p enalties, an analyst can visually identify the different h ub no des. B. Real Netw orks 1. arXiv Citations W e inv estigate a time series of citation netw orks pro- vided as part of the 2003 KDD Cup [ 60 ]. The graphs are from the e-print service arXiv for the ‘high energy ph ysics theory’ section. The data cov ers papers in the p erio d from Octob er 1993 to Decem b er 2002, and is organized in to monthly net works. In particular, if pap er i cites pap er j , then the graph contains a directed edge from i to j . An y citations to or from papers outside the dataset are not included. F ollo wing conv ention, edges are aggregated, that is, the citation graph for a giv en month will contain all citations from the b eginning of the data up to, and including, the curren t month. Altogether, there are 22750 no des (pa- p ers) with 176602 edges (references) ov er 112 months. As a first step tow ards inv estigating the data, we dra w the net w ork at different p oints in time in Fig. 12 . Even when considering a single time p oin t, it quic kly b ecomes difficult to discern pap er (node) properties due to the 10 Threshold=2 Threshold=3 Threshold=4 Sp ectral Clustering ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 3 1 5 200 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 3 1 5 200 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 3 1 5 200 2 Clique P ercolation ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 3 1 5 200 2 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 3 1 5 200 2 No Communities Detected FIG. 10. (Color online) The first and second rows apply static clustering metho ds to the collapsed data (a veraging ov er time). All alternative metho ds struggle to identify the k ey individuals or hierarchical organizational structure. large net work size. Th us, the data requires netw ork statistics and other metho ds to extract structure and in- fer dynamics in the net work sequence. Net work statis- tics, sho wn in Fig. 13 , pro vide some additional insigh t. There is a noticeable increase in netw ork gro wth around the y ear 2000, which is commonly attributed to pap ers that reference other w orks b efore the start of the ob- serv ation p erio d (see [ 61 ]). As we mov e a wa y from the b eginning of the data, papers primarily reference other pap ers b elonging to the data set. Additional statistical prop erties of the data w ere discussed in [ 61 ], whic h found that the netw orks feature decreasing diameter ov er time and hea vy-tailed degree distributions. T o visualize how nodes in the netw ork evolv ed, Fig. 14 displa ys results from the matrix factorization mo del using a sequence of one-dimensional approximations ( K = 1). The adjacency matrix is constructed so that U t scores no des by their importance to the a v erage inc oming con- nections, and ( U t ) 1 j measures the time-v arying authority of pap er j . V t yields similar scores based on outgoing con- nections. As observed with the preferential attachmen t exp erimen t, the paper tra jectories are smo othed effec- tiv ely and important dynamics are highlighted b y em- plo ying p enalties. Sp ecifically , there are tw o imp ortant p eriods in the data. The first p erio d cov ers 1996-1999, and featured pap ers mostly on an extension of string the- ory called M-theory . M-theory was first proposed in 1995 and led to new research in theoretical ph ysics. A n um b er of scientists, including Witten, Sen and Polc hinski, were imp ortan t to the historical developmen t of the theory , and as seen in T ables I and T able I I , our NMF approach iden tifies these imp ortan t authors and their w orks. F rom 1999-2000 the rate of citations to these papers tended to decrease, while focus shifted to other topics and sub- fields that M-theory ga v e rise to. These citation pat- terns are reflected in the b old and dashed tra jectories in Fig. 14 . The displays of V t sparsit y show that pap ers do not app ear uniformly throughout time. Instead as other net work statistics show, pap ers ‘attac h’ at a faster rate around y ear 2000. W e provide comparisons with the alternative metho d- ologies utilized in [ 5 ] to inv estigate dynamic citation net- w ork from the US Supreme Court. First, we apply the leading eigen v ector modularity-based method for com- m unity discov ery [ 47 ] to the fully formed citation netw ork ( t = 112). The second alternative metho dology is a mix- ture mo del in [ 5 ] to extract groups of pap ers according to their common temp oral citation profiles. The left panel of Fig. 15 sho ws the degree of each pap er o ver time, colored by the leading eigenv ector communit y assignmen ts. The optimal num b er of groups is ov er tw o h undred. There are four large groups of papers, with the 11 (a)No p enalties (b) λ t = 50 , λ s = 5 (c) λ t = 100 , λ s = 5 FIG. 11. (Color online) Fitted v alues for U and V ov er time for the preferential attac hment simulation. The left column sho ws a time plot of U t o ver different parameter v alues. Each line corresponds to a no de on the graph. The right column iden tifies the nonzero elemen ts of V t . Each row corresp onds to a no de on the graph and time v aries along the horizon tal axis. Jan 1995 Jan 1998 Jan 2000 FIG. 12. Graph la y outs of the arXiv data at three differ- en t time p oin ts. Due to the size of the net works, it quickly b ecomes difficult to discern pap er (no de) prop erties. ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Number Nodes Number Edges 5e+01 5e+02 5e+03 5e+04 50 200 500 2000 10000 Y ear Number Nodes 0 5000 10000 20000 1994 1996 1998 2000 2002 Y ear A vg Degree 2 4 6 8 10 12 14 16 1994 1996 1998 2000 2002 Y ear Clustering Coef 0.00 0.02 0.04 0.06 0.08 0.10 1994 1996 1998 2000 2002 FIG. 13. (Color online) ArXiv netw ork statistics ov er time. The kink near near Jan uary 2000 indicates sudden, rapid gro wth. The top-left plot is on a log-log scale. other groups con taining only a handful of pap ers. This approac h does not utilize the temp oral profile of eac h pap er, and as a consequence the groups are in terpretable from a static connectivit y p oin t of view only . The right panel of Fig. 15 sho ws reasonable time- profiles from the mixture model. One group gro ws slo wly from the b eginning of the observ ational p erio d, while the other group exp eriences rapid growth starting around the year 2000. These results complimen t the NMF- based Fig. 14 , and together provide a robust metho dol- ogy to identify imp ortant pap ers, as well as characterize the data in terms of the num b er and types of different no des/groups in the data. 2. Glob al T r ade Flows In this example, w e analyze annual bilateral trade flows b et w een 164 coun tries from 1980-1997 [ 62 ]. Thus, we observ e a dynamic, weigh ted graph at 18 time p oin ts, where each directional edge denotes the total v alue of exp orts from one coun try to another. Since trade flows can differ in size by orders of magnitude, w e work with trade v alues that are expressed in log dollars. W e fit a sequence of rank 6 NMFs, as iden tified in Fig. 16 through cross v alidation, and displa y the net work based on fitted trade flows ( ˆ A t = U t V T t ) in Fig. 17 . W e sho w only three y ears (1980, 1990, 1997) due to space constrain ts. All countries b elong to more than one communit y , whic h reflects the interconnected nature of the global 12 No Penalt y λ s = 1 λ s = 5 λ s = 10 FIG. 14. (Color online) Fitted v alues for U t and V t for the arXiv data with λ t = 5. Each ligh t gray line corresp onds to a pap er (no de) on the graph. The b old lines show the av erage of the 10 pap ers with highest av erage ˆ U from 1996-1999, and 2000 on wards (dashed). Each ro w in the heatmaps corresp onds to a pap er and time v aries along the horizontal axis. T ABLE I. The top 10 papers with highest av erage ˆ U from 1996-1999. # Citations counts all references to the work, including b y pap ers outside of our data. These counts obtained via Go ogle. Title Authors In-Degree Out-Degree # Citations (Google) Heterotic and Type I String Dynamics from Eleven Dimensions Horav a and Witten 783 18 2334 Fiv e-branes And M -Theory On An Orbifold Witten 169 15 251 T yp e I IB Sup erstrings, BPS Monop oles, And Three- Hanan y and Witten 437 20 844 Dimensional Gauge Dynamics D-Branes and T opological Field Theories Bershadsky , et al. 271 15 463 Lectures on Sup erstring and M Theory Dualities Sc hw arz 247 68 534 D-Strings on D-Manifolds Bershadsky et al. 172 22 247 String Theory Dynamics In V arious Dimensions Witten 263 0 2263 Branes, Fluxes and Duality in M(atrix)-Theory Ganor, et al. 184 16 243 Diric hlet-Branes and Ramond-Ramond Charges P olchinski 370 0 2592 Matrix Description of M-theory on T 5 and T 5 / Z 2 Seib erg 208 30 353 econom y . Ho wev er, there are coun tries, primarily from Africa and Cen tral America, that are dominated by a single communit y or b elong to only a subset of the six comm unities. F or instance, in 1997, Ecuador, V enezuela and Panama only connect with the USA and hence, b e- long mostly to the green comm unity . There are also in teresting findings that corresp ond with historical ev ents. F or instance, in 1980 there is a strong communit y (circled in the figure) consisting of coun tries aligned with the former USSR, which acted as a hub. How ever b y 1990, this communit y has dis- solv ed, and is reflected in the edge and no de colorings of these coun tries (more diversified trading relationships). In 1990, w e also see the emergence of the so-called ’Asian miracles’, countries in Asia that exp erienced p ersistent and rapid ec onomic growth in the 1990’s [ 63 , 64 ]. These coun tries mo ve closer to the cen ter of the trading netw ork with mem b ership in all communities. V. DISCUSSION The main idea b ehind the approac h presented in this pap er is to abstract the netw ork sequence to a sequence of 13 T ABLE I I. The top 10 pap ers with highest a verage ˆ U from 2000 onw ards. Title Authors In-Degree Out-Degree # Citations (Google) The Large N Limit of Sup erconformal Field Theories and Sup ergravit y Maldacena 1059 2 10697 An ti De Sitter Space And Holography Witten 766 2 6956 Gauge Theory Correlators from Non-Critical String Theory Gubser et al. 708 0 6004 String Theory and Noncommutativ e Geometry Seib erg and Witten 796 12 3833 Large N Field Theories, String Theory and Gravit y Aharon y et a. 446 74 3354 An Alternative to Compactification Randall and Sundrum 733 0 5693 Noncomm utative Geometry and Matrix Theory: Compactification on T ori Connes et al. 512 3 1810 M Theory As A Matrix Mo del: A Conjecture Banks et al. 414 0 2460 D-branes and the Noncommutativ e T orus Douglas and Hull 296 2 866 Diric hlet-Branes and Ramond-Ramond Charges P olchinski 370 0 2592 Y ear 0.00 0.01 0.02 0.03 0.04 1994 1996 1998 2000 2002 0 4000 10000 Group Size FIG. 15. The left panel shows the degree of eac h no de o ver all time p oints, colored by the leading eigenv ector groupings. The right panel shows time-profiles for each group based on the mixture mo del of [ 5 ]. ● ● ● ● ● ● ● ● ● ● Av erage RSS Inner Rank 2 4 6 8 10 120000 140000 160000 180000 200000 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Avg T est Error Inner Rank 2 Partitions 5 10 15 1400 1800 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Avg T est Error Inner Rank 5 Partitions 5 10 15 5500 7000 8500 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Avg T est Error Inner Rank 10 Partitions 5 10 15 35000 45000 FIG. 16. Cho osing K for W orld T rade Data. The left panel sho ws the a verage residual sum of squares. The right panel sho ws the av erage test error obtained via cross v alidation for differen t n umber of partitions. Cross v alidation consistently indicates 6 communities ( K = 6) as optimal. lo wer dimensional spaces using matrix factorizations for visual exploration, communit y detection and structural disco very . Next, w e highlight some of the strengths and w eaknesses of this approach. A. Strengths An important b enefit is the v ersatility and scalabil- it y of matrix factorization mo del. T able I II shows run- times for all exp erimen ts. The computational cost is lo w enough to use in com bination with other analysis and visualization to ols. Moreo ver, the p enalized NMF ap- proac h is compatible with b oth binary and weigh ted net- w orks. Using the model as a basis for an exploratory visual to ol can help users unco ver different connectivity pat- terns and evolution in the data. The estimates of U t and V t can b e used for comm unity disco v ery or a ranking of nodes based on their importance to connectivity for subsequen t analysis. Displa ys of the factorizations can pro vide a sense of the data complexity , namely the types and n umber of no de evolutions. B. W eaknesses The optimal choice of tuning parameters ( λ t , λ s ) is dep enden t on perception and how the edge weigh ts are scaled. This can limit the benefits of the proposed ap- proac h when given multiple datasets. Time plots and heatmaps to visualize eac h factor yield limited information ab out global top ology . F or exam- ple, one can see from Figs. 11 and 14 that there are dominan t no des, but in principle, there could b e many top ologies that feature dominan t no des. One cannot sa y for sure without additional analysis that the net works follo w a particular connectivity mo del. Th us, combining the matrix factorization mo del in this article with exist- ing analysis and visualization tools can provide a more comprehensiv e analysis of the data. C. F uture W ork An imp ortan t area of exploration would b e to system- atically compare penalized versions of NMF and SVD. 14 1980 1990 1997 FIG. 17. (Color online) W orld trade netw orks o ver time, where countries are colored corresp onding to their membership in 6 comm unities. Edges are colored by the communit y with largest relative contribution. The b ottom row sho ws the same netw ork dra wing without lab els. T ABLE I I I. Av erage run times for the p enalized NMF with temporal and sparsity p enalties. The computational time scales appro ximately linearly with the num b er of time p oints and no des. Data No des Time Poin ts Run time (seconds) Catalano 400 7 0.29 W orld T rade 164 18 0.51 Preferen tial Attac hmen t 10000 100 39.45 arXiv Citations 22750 112 60.64 In this work w e chose to fo cus on NMF, since w e find the corresp onding displays preferable in terms of in ter- pretabilit y . This is generally consistent with existing lit- erature on matrix factorization. Ho wev er, SVD of graph related matrices hav e deep connections to classical sp ec- tral lay out and problems in communit y detection. There ma y b e classes of graph top ologies and particular visual- ization goals under whic h SVD is preferable. There could also be other t yp es and combinations of p enalties that are useful in visualization and detec- tion of graph structure. F or instance, depending on the precise meaning of a directional edge, one ma y desire b oth smo othness and sparsity for U t , V t or b oth factors. Nonetheless, v ariants on the p enalty structure will result in mo dels that require roughly the same computational costs. Thus, this w ork pro vides evidence that penalized matrix factorization mo dels are promising for structural and functional discov ery in dynamic netw orks. [1] S. E. Fienberg, Journal of Computational and Graphical Statistics 21 , 825 (2012) . [2] A. Goldenberg, A. X. Zheng, S. E. Fien b erg, and 15 E. M. Airoldi, ArXiv e-prints (2009), [stat.ME] . [3] M. Girv an and M. E. J. Newman, Pro ceedings of the Na- tional Academy of Science 99 , 7821 (2002) , arXiv:cond- mat/0112110 . [4] B. Ball, B. Karrer, and M. E. J. Newman, Phys. Rev. E 84 , 036103 (2011) , arXiv:1104.3590 . [5] E. A. Leich t, G. Clarkson, K. Shedden, and M. E. New- man, The Europ ean Physical Journal B 59 , 75 (2007) . [6] P . Sark ar and A. Mo ore, in A dvanc es in Neur al In- formation Pr o c essing Systems 18 , edited by Y. W eiss, B. Sch¨ olk opf, and J. Platt (MIT Press, Cambridge, MA, 2006) pp. 1145–1152. [7] P . D. Hoff, A. E. Raftery , and M. S. Handco ck, Journal of the American Statistical Asso ciation 97 , 1090 (2002) . [8] J. Sun, C. F aloutsos, S. P apadimitriou, and P . S. Y u, in Pr o c e e dings of the 13th ACM SIGKDD international c on- fer enc e on Know le dge disc overy and data mining , KDD ’07 (ACM, New Y ork, NY, USA, 2007) pp. 687–696. [9] M. Kolar, L. Song, A. Ahmed, and E. P . Xing, Annals of Applied Statistics 4 , 94 (2010) , ”arXiv”:0812.5087 . [10] E. Richard, P .-A. Sa v alle, and N. V a y atis, ArXiv e-prints (2012), arXiv:1205.1406 [stat.ML] . [11] S. Asur, S. Parthasarath y , and D. Ucar, A CM T rans. Kno wl. Discov. Data 3 , 16:1 (2009) . [12] M. Raginsky , R. Willett, C. Horn, J. Silv a, and R. Mar- cia, Information Theory , IEEE T ransactions on 58 , 5544 (2012) , 0911.2904 . [13] I. Psorakis, S. Roberts, M. Eb den, and B. Sheldon, Ph ys. Rev. E 83 , 066114 (2011) . [14] F. W ang, T. Li, X. W ang, S. Zhu, and C. Ding, Data Mining and Knowledge Discov ery 22 , 493 (2011) . [15] S. F ortunato and M. Barthlem y , Proceedings of the National Academ y of Sciences 104 , 36 (2007) , arXiv:ph ysics/0607100 . [16] Y. F rishman and A. T al, Visualization and Computer Graphics, IEEE T ransactions on 14 , 727 (2008) . [17] D. Arc hambault, H. Purchase, and B. Pinaud, Visual- ization and Computer Graphics, IEEE T ransactions on 17 , 539 (2011) . [18] S. Ghani, N. Elmqvist, and J.-S. Yi, Computer Graphics F orum (Pro c. EuroViz 2012) 31 , 1205 (2012). [19] T. von Landserb er, A. Kuijp er, T. Schrec k, J. Kohlham- mer, J.-J. v an Wijk, and D.-W. F ellner, EuroGraphics state of the art rep orts (2010). [20] T. von Landesb erger, A. Kuijp er, T. Sc hreck, J. Kohlhammer, J. v an Wijk, J.-D. F ek ete, and D. F ellner, Computer Graphics F orum 30 , 1719 (2011) . [21] J. S. Yi, N. Elmqvist, and S. Lee, International Journal of Human-Computer Interaction 26 , 1031 (2010). [22] T. Hastie, R. Tibshirani, and J. H. F riedman, The ele- ments of statistical learning: data mining, infer enc e, and pr e diction: with 200 ful l-c olor il lustr ations (New Y ork: Springer-V erlag, 2001) p. 533. [23] Y. Koren, Computers & Mathematics with Applications 49 , 1867 (2005) . [24] U. Brandes, D. Fleisc her, and T. Puppe, in Gr aph Dr aw- ing , Lecture Notes in Computer Science, V ol. 3843, edited b y P . Healy and N. Nikolo v (Springer Berlin Heidelb erg, 2006) pp. 25–36. [25] K. Rohe and B. Y u, ArXiv e-prints (2012), arXiv:1204.2296 [stat.ML] . [26] K. Rohe, S. Chatterjee, and B. Y u, Ann. Stat. 39 , 1878 (2011) , 1007.1684 . [27] F. R. K. Chung, Sp e ctr al Gr aph The ory (Amer. Math. So c., 1997). [28] D. D. Lee and H. S. Seung, Nature 401 , 788 (1999). [29] D. D. Lee and H. S. Seung, Adv ances in neural informa- tion pro cessing systems , 556 (2001) . [30] P . P aatero and U. T app er, Environmetrics 5 , 111 (1994) . [31] K. Dev ara jan, PLoS Comput Biol 4 , e1000029 (2008) . [32] C. Ding, X. He, and H. D. Simon, in Pr oc. SIAM Data Mining Conf (2005) pp. 606–610. [33] C. Ding, T. Li, and W. Peng, Comput. Stat. Data Anal. 52 , 3913 (2008) . [34] Y.-R. Lin, Y. Chi, S. Zhu, H. Sundaram, and B. L. Tseng, in Pr o c e e dings of the 17th international c onfer enc e on World Wide Web , WWW ’08 (ACM, New Y ork, NY, USA, 2008) pp. 685–694. [35] A. Buja, D. F. Swa yne, M. L. Littman, N. Dean, H. Hof- mann, and L. Chen, Journal of Computational and Graphical Statistics 17 , 444 (2008) . [36] M. W. Berry , M. Browne, A. N. Langville, V. P . Pauca, and R. J. Plemmons, in Computational Statistics and Data Analysis (2006) pp. 155–173. [37] Z. Chen and A. Cichocki, in L ab or atory for A dvanc e d Br ain Signal Pr o c essing, RIKEN, T e ch. R ep (2005). [38] P . O. Ho yer, in In Neur al Networks for Signal Pr o c ess- ing XII (Pro c. IEEE Workshop on Neur al Networks for Signal Pro c essing) (2002) pp. 557–565. [39] P . O. Ho yer, J. Mac h. Learn. Res. 5 , 1457 (2004), arXiv:cs/0408058 . [40] D. Cai, X. He, J. Han, and T. Huang, Pattern Analysis and Machine In telligence, IEEE T ransactions on 33 , 1548 (2011) . [41] H. Zou, T. Hastie, and R. Tibshirani, Journal of Com- putational and Graphical Statistics 15 , 265 (2006) . [42] D. M. Witten, R. Tibshirani, and T. Hastie, Biostatistics 10 , 515 (2009) . [43] J. Guo, G. James, E. Levina, G. Michai- lidis, and J. Zh u, Journal of Computa- tional and Graphical Statistics 19 , 930 (2010) , h ttp://pubs.amstat.org/doi/p df/10.1198/jcgs.2010.08127 . [44] M. Chu, F. Diele, R. Plemmons, and S. Ragni, SIAM Journal of Matrix Analysis , 4 (2004) . [45] S. Boyd and L. V andenberghe, Convex optimization (Cam bridge Univ ersity Press, Cam bridge, 2004) pp. xiv+716. [46] C.-J. Lin, Neural Net works, IEEE T ransactions on 18 , 1589 (2007) . [47] M. E. J. Newman, Phys. Rev. E 74 , 036104 (2006) , arXiv:ph ysics/0605087 . [48] G. Palla, I. Der´ en yi, I. F ark as, and T. Vicsek, Nature (London) 435 , 814 (2005) , arXiv:physics/0506133 . [49] J. M. Klein b erg, J. ACM 46 , 604 (1999) . [50] C. D. Mey er, ed., Matrix analysis and applie d line ar al- gebr a (So ciet y for Industrial and Applied Mathematics, Philadelphia, P A, USA, 2000). [51] P . O. Perry and A. B. Owen, Annals of Applied Statistics 3 , 564 (2009), 0908.2062 . [52] IEEE V AST (IEEE, 2008). [53] A. A. Shav erdian, H. Zhou, G. Mic hailidis, and H. V. Jagadish, in Pr o c e e dings of the ACM SIGKDD Work- shop on Visual Analytics and Know le dge Disc overy: Inte- gr ating Automate d Analysis with Inter active Explor ation , V AKD ’09 (A CM, New Y ork, NY, USA, 2009) pp. 74–82. [54] Z. Shen and K.-L. Ma, in Visualization Symp osium, 2008. PacificVIS ’08. IEEE Pacific (2008) pp. 175 –182. 16 [55] Q. Y e, B. W u, D. Hu, and B. W ang, in F uzzy Systems and Know le dge Discovery, 2009. FSKD ’09. Sixth Inter- national Conferenc e on , V ol. 2 (2009) pp. 413 –417. [56] M. Newman, A. Barab´ asi, and D. W atts, The Structur e And Dynamics of Networks , Princeton Studies in Com- plexit y (Princeton Universit y Press, 2006). [57] A.-L. Barabsi and R. Alb ert, Science 286 , 509 (1999) . [58] G. Bouno v a, Matlab to ols for network analysis , T ech. Rep. (Massach usetts Institute of T echnology , 2011). [59] A. Clauset, C. Shalizi, and M. Newman, SIAM Review 51 , 661 (2009), 0706.1062 . [60] J. Gehrke, P . Ginsparg, and J. M. Klein b erg, in SIGKDD Explor ations , V ol. 5 (2003) pp. 149 –151. [61] J. Lesko vec, J. Kleinberg, and C. F aloutsos, in Pr o c e e d- ings of the eleventh ACM SIGKDD international c onfer- enc e on Know le dge disc overy in data mining , KDD ’05 (A CM, New Y ork, NY, USA, 2005) pp. 177–187. [62] R. C. F eenstra, R. E. Lipsey , H. Deng, A. C. Ma, and H. Mo, NBER W orking Paper no. 11040 (2004). [63] J. E. Stiglitz, The W orld Bank Research Observer 11 , 151 (1996) . [64] R. R. Nelson and H. Pac k, The Asian mir acle and mo d- ern gr owth the ory , P olicy Research W orking P ap er Series 1881 (The W orld Bank, 1998).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment