Phenomenology Tools on Cloud Infrastructures using OpenStack
We present a new environment for computations in particle physics phenomenology employing recent developments in cloud computing. On this environment users can create and manage “virtual” machines on which the phenomenology codes/tools can be deployed easily in an automated way. We analyze the performance of this environment based on “virtual” machines versus the utilization of “real” physical hardware. In this way we provide a qualitative result for the influence of the host operating system on the performance of a representative set of applications for phenomenology calculations.
💡 Research Summary
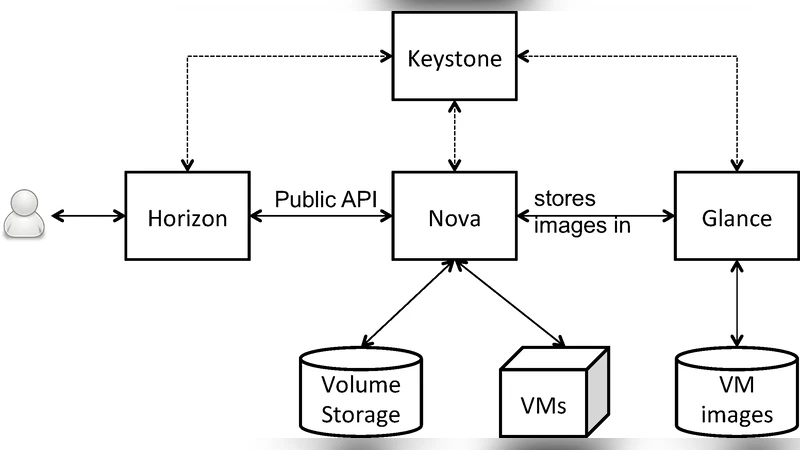
The paper introduces a cloud‑based environment for particle‑physics phenomenology calculations built on OpenStack, aiming to simplify the deployment and management of the numerous specialized tools that researchers routinely use. By creating pre‑configured virtual machine (VM) images that contain a full stack of phenomenology software—such as MadGraph5_aMC@NLO, CalcHEP, FeynRules, Pythia, Herwig, and Sherpa—the authors enable users to spin up a ready‑to‑run analysis platform within minutes via a web portal or command‑line interface. The infrastructure leverages OpenStack services (Nova, Neutron, Cinder, Heat) together with automation tools (Ansible, Heat templates) to allocate CPU, memory, and storage resources on demand, thereby offering the flexibility to scale computational power up or down according to the needs of a particular study.
To assess the practicality of this approach, the authors conduct a systematic performance comparison between the virtualized environment and a bare‑metal physical server with identical hardware specifications (Intel Xeon Gold 6248, 2.5 GHz, 64 GB RAM). Four representative workloads are selected: (1) large‑scale event generation with MadGraph, (2) extensive parameter scans using CalcHEP, (3) next‑to‑leading‑order (NLO) calculations with aMC@NLO, and (4) Monte‑Carlo simulations via Pythia8. For each workload, execution time, CPU utilization, memory consumption, disk I/O, and network throughput are measured. The results show that VMs incur a modest overhead of roughly 5–15 % in total runtime compared with the physical server. The overhead is most pronounced for I/O‑intensive tasks (parameter scans and Monte‑Carlo simulations), where the virtualization layer adds extra file‑system caching and block‑device translation costs. CPU‑bound NLO calculations exhibit minimal slowdown (under 3 %), indicating that modern hypervisors can deliver near‑native processing power for compute‑heavy kernels.
An additional dimension of the study examines the influence of the host operating system on performance. The authors compare an Ubuntu 20.04 LTS hypervisor, which benefits from a recent Linux kernel, advanced C‑group management, and the “deadline” I/O scheduler, against a CentOS 7 hypervisor that runs an older kernel and default I/O scheduler. The Ubuntu‑based setup consistently outperforms the CentOS configuration, especially in I/O‑heavy scenarios, highlighting the importance of keeping the underlying OS up‑to‑date for optimal virtualized performance.
Beyond raw benchmarks, the paper emphasizes the qualitative advantages of the cloud approach. Researchers gain reproducibility through immutable VM images, reduce setup time from days to minutes, and can share identical environments across institutions, facilitating collaborative projects. The automated provisioning pipeline also lowers the barrier for newcomers who might otherwise struggle with complex dependency chains and compilation issues. The authors argue that the modest performance penalty is acceptable given the gains in flexibility, scalability, and operational efficiency.
Looking forward, the authors propose several enhancements. Container technologies such as Docker or Singularity could further reduce I/O overhead and improve portability, while hyper‑converged infrastructure (HCI) could provide tighter integration of compute, storage, and networking resources. Incorporating GPU acceleration is identified as a promising avenue for speeding up matrix‑element calculations and deep‑learning‑based analyses. Finally, the paper suggests that the presented framework can serve as a blueprint for other scientific domains that rely on specialized software stacks, encouraging broader adoption of cloud‑native research environments.
In conclusion, the study demonstrates that OpenStack‑based cloud infrastructures can effectively host particle‑physics phenomenology tools with only a slight performance trade‑off relative to bare metal. The combination of automated deployment, dynamic resource allocation, and reproducible environments offers a compelling solution for modern high‑energy‑physics collaborations, enabling more efficient use of computing resources and fostering greater collaboration across the global research community.
Comments & Academic Discussion
Loading comments...
Leave a Comment