Using PCA to Efficiently Represent State Spaces
Reinforcement learning algorithms need to deal with the exponential growth of states and actions when exploring optimal control in high-dimensional spaces. This is known as the curse of dimensionality. By projecting the agent’s state onto a low-dimensional manifold, we can represent the state space in a smaller and more efficient representation. By using this representation during learning, the agent can converge to a good policy much faster. We test this approach in the Mario Benchmarking Domain. When using dimensionality reduction in Mario, learning converges much faster to a good policy. But, there is a critical convergence-performance trade-off. By projecting onto a low-dimensional manifold, we are ignoring important data. In this paper, we explore this trade-off of convergence and performance. We find that learning in as few as 4 dimensions (instead of 9), we can improve performance past learning in the full dimensional space at a faster convergence rate.
💡 Research Summary
The paper addresses the well‑known “curse of dimensionality” that hampers reinforcement learning (RL) when the state space grows exponentially with the number of system variables. The authors propose a straightforward yet effective remedy: before each learning step, project the high‑dimensional state vector onto a low‑dimensional manifold obtained by Principal Component Analysis (PCA) on a set of demonstration trajectories. The transformed state is then used by a standard tabular Q(λ) learner; actions are executed in the original simulator, the resulting next state is again projected, and the Q‑update proceeds as usual. Because the projection is a simple matrix multiplication, the computational overhead is negligible.
To validate the approach, the authors use the Mario AI Benchmark, a widely studied platform where an agent must collect points, avoid enemies, and reach the end of a level. The original state representation consists of nine variables: jump‑ability, ground contact, fire‑ball ability, current direction (8 compass directions plus idle), binary encodings of nearby enemies (close and mid‑range), a four‑cell forward obstacle flag, and the coordinates of the closest enemy within a 21×21 grid. This yields a theoretical space of 3.24 × 10¹⁰ possible states and 4 × 10¹¹ Q‑values, though in practice only a tiny fraction is visited.
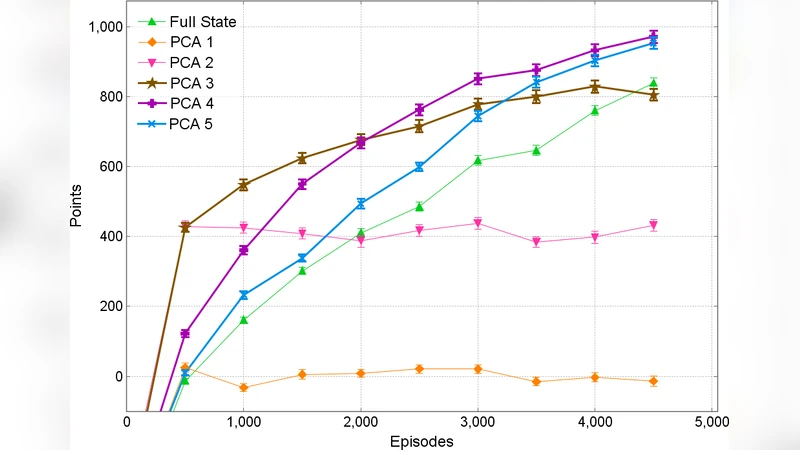
The authors first compute the covariance matrix of the demonstration data, extract eigenvectors, and sort them by eigenvalue magnitude. By selecting the top k eigenvectors they form a p × k matrix Wₖ (p = 9). The projection of any state x is xₖ = Wₖᵀ x. Experiments vary k from 2 to 9 and measure learning speed and final performance over 100 independent runs, each episode being played on a procedurally generated level with random seed and random initial Mario mode.
Results show a clear trade‑off. With k ≤ 2 the agent’s policy remains near random; convergence is extremely slow because essential information (jump, ground, direction) is heavily compressed. At k = 3 the learning speed improves, yet the final score still lags behind higher‑dimensional runs. When k ≥ 4, the agent quickly reaches a policy that outperforms the full‑dimensional baseline within roughly 5 000 episodes. The first four principal components capture the most frequently changing and most influential features (jump, ground, direction, fire‑ball ability, closest enemy Y‑coordinate, and forward obstacles). Adding more components beyond the fourth yields diminishing returns; performance plateaus and matches the full‑state case, confirming that the additional variance mainly encodes rare, fine‑grained situations.
Importantly, the authors note that while low‑dimensional learning accelerates early convergence, it cannot ultimately surpass the asymptotic performance of learning in the full space because PCA discards low‑variance information that may be crucial for optimal fine‑tuning. Consequently, the method exhibits a convergence‑performance trade‑off: faster convergence to a good but sub‑optimal policy versus slower convergence to a potentially higher‑quality policy.
The discussion acknowledges two limitations. First, the current approach assumes all states are equally important; high‑variance states that are irrelevant to the task may still dominate the PCA, leading to suboptimal component selection. Second, learning is halted once convergence is detected in the low‑dimensional space, preventing the agent from later exploiting the richer representation. To mitigate these issues, the authors propose a future “iterative dimensionality expansion” scheme: train until convergence in k dimensions, then transfer the learned policy to k + 1 dimensions, repeat until the full space is reached. This idea is inspired by mixed‑resolution function approximation work (Grzes & Kudenko) where a coarse approximation provides early guidance and a finer one refines the policy later.
In summary, the paper demonstrates that PCA‑based dimensionality reduction can dramatically speed up reinforcement learning in high‑dimensional domains without sacrificing much performance, provided that enough principal components are retained to preserve the most salient features. The approach is simple, computationally cheap, and broadly applicable to any RL problem where a representative set of state trajectories can be collected. The empirical study on the Mario benchmark validates the hypothesis, quantifies the convergence‑performance trade‑off, and outlines a promising direction for future research involving progressive dimensionality increase and hybrid function approximators.
Comments & Academic Discussion
Loading comments...
Leave a Comment