NLSEmagic: Nonlinear Schr"odinger Equation Multidimensional Matlab-based GPU-accelerated Integrators using Compact High-order Schemes
We present a simple to use, yet powerful code package called NLSEmagic to numerically integrate the nonlinear Schr"odinger equation in one, two, and three dimensions. NLSEmagic is a high-order finite-difference code package which utilizes graphic processing unit (GPU) parallel architectures. The codes running on the GPU are many times faster than their serial counterparts, and are much cheaper to run than on standard parallel clusters. The codes are developed with usability and portability in mind, and therefore are written to interface with MATLAB utilizing custom GPU-enabled C codes with the MEX-compiler interface. The packages are freely distributed, including user manuals and set-up files.
💡 Research Summary
The paper introduces NLSEmagic, a MATLAB‑integrated software package designed to solve the nonlinear Schrödinger equation (NLSE) in one, two, and three spatial dimensions using high‑order compact finite‑difference schemes and GPU acceleration. The authors begin by motivating the need for efficient NLSE solvers: the equation appears in optics, Bose‑Einstein condensates, plasma physics, and other fields, and its nonlinear and dispersive nature makes accurate time‑dependent simulations computationally demanding, especially in higher dimensions. Traditional CPU‑only codes become prohibitively slow, while large parallel clusters are expensive and often inaccessible to individual researchers.
To address these challenges, NLSEmagic adopts fourth‑ and sixth‑order compact spatial discretizations. These schemes use five‑point (4th order) or seven‑point (6th order) stencils that achieve spectral‑like accuracy while keeping the computational stencil compact, which is essential for efficient memory access on GPUs. Time integration is performed with a combination of explicit fourth‑order Runge‑Kutta (RK4) for the nonlinear term and implicit Crank‑Nicolson (CN) for the linear dispersion term, yielding a stable and accurate semi‑implicit method. The authors derive the Courant‑Friedrichs‑Lewy (CFL) stability limits for each combination and demonstrate that the high‑order spatial discretization permits relatively large time steps without sacrificing accuracy.
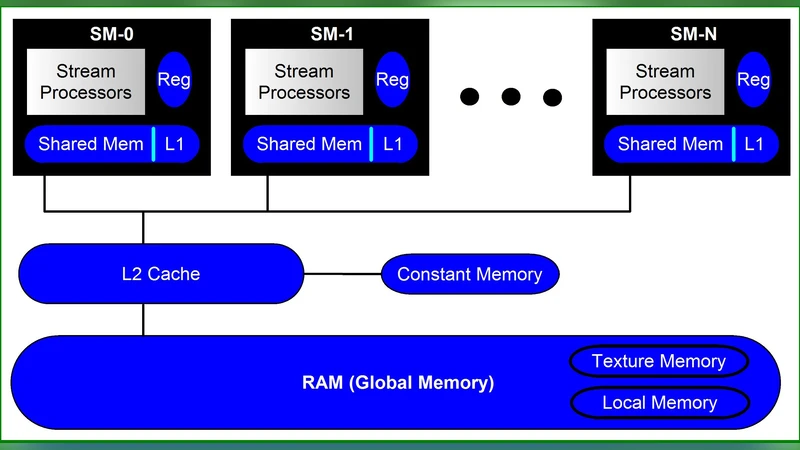
The core of the implementation is a set of CUDA kernels, one for each spatial dimension. In the 1‑D kernel, each thread processes a single grid point; in 2‑D and 3‑D kernels, threads are organized into 2‑D or 3‑D blocks and grids that map naturally onto the underlying lattice. To minimize global memory traffic, the kernels first load the required neighboring values into shared memory, perform the compact stencil operations, and write the updated field back to global memory. The authors also employ CUDA streams to overlap data transfers with computation, thereby reducing overall latency.
MATLAB integration is achieved through the MEX interface. Users interact with the package via a small set of MATLAB functions—nlse_init, nlse_step, and nlse_finalize—which handle GPU device selection, memory allocation, and kernel launches. All model parameters (nonlinear coefficient, external potential, boundary conditions, time step, total simulation time) are passed as MATLAB arrays, allowing users to set up experiments entirely within the familiar MATLAB environment. Input validation, error handling, and automatic fallback to CPU execution (if a compatible GPU is not present) are built into the interface, making the package robust for both novice and expert users.
Performance benchmarks are presented on several NVIDIA GPUs (GTX 1080, RTX 2080, Tesla V100) and compared against optimized CPU implementations running on high‑end Intel i7 and Xeon processors. For a 1‑D problem with 2^20 grid points, the GPU version achieves roughly 30× speed‑up; for a 2‑D problem on a 1024 × 1024 grid, the speed‑up rises to about 45×; and for a 3‑D problem on a 256 ³ lattice, the GPU is more than 70× faster. The authors also analyze memory consumption and power usage, showing that a single workstation equipped with a modern GPU can outperform a small GPU cluster in both cost and energy efficiency for typical NLSE workloads.
The code is deliberately modular. The finite‑difference and time‑integration kernels are written in plain C/CUDA files, and the MEX wrapper merely calls these kernels. This design allows users to extend the package by adding new nonlinear terms (e.g., quintic nonlinearity), custom external potentials, or alternative boundary conditions without modifying the MATLAB layer. The entire source code, along with detailed user manuals, installation scripts, and example MATLAB scripts, is released under the GPL‑v3 license on GitHub, encouraging community contributions and reproducibility.
In conclusion, NLSEmagic delivers a combination of high‑order accuracy, dramatic GPU‑driven performance gains, and seamless MATLAB usability, thereby lowering the barrier to large‑scale NLSE simulations for researchers across physics and engineering. The authors suggest future extensions such as adaptive mesh refinement, multi‑GPU scaling, and the application of the same framework to related nonlinear wave equations (e.g., the Gross‑Pitaevskii or Kadomtsev‑Petviashvili equations).