CMS Workflow Execution using Intelligent Job Scheduling and Data Access Strategies
Complex scientific workflows can process large amounts of data using thousands of tasks. The turnaround times of these workflows are often affected by various latencies such as the resource discovery, scheduling and data access latencies for the individual workflow processes or actors. Minimizing these latencies will improve the overall execution time of a workflow and thus lead to a more efficient and robust processing environment. In this paper, we propose a pilot job based infrastructure that has intelligent data reuse and job execution strategies to minimize the scheduling, queuing, execution and data access latencies. The results have shown that significant improvements in the overall turnaround time of a workflow can be achieved with this approach. The proposed approach has been evaluated, first using the CMS Tier0 data processing workflow, and then simulating the workflows to evaluate its effectiveness in a controlled environment.
💡 Research Summary
The paper addresses the long‑standing performance bottlenecks in large‑scale scientific workflows, using the CMS Tier‑0 data‑processing pipeline as a concrete example. In traditional batch‑oriented environments, each of the thousands of workflow tasks is submitted independently to a computing cluster, and every task must retrieve its input files from remote storage (e.g., EOS or CASTOR). This model incurs multiple sources of latency: resource discovery, queue waiting, scheduler decision time, and especially data‑transfer latency. When these latencies accumulate, the overall turnaround time (TAT) of the workflow can become prohibitively long, limiting the responsiveness of the experiment’s data‑processing chain.
To mitigate these issues, the authors propose an infrastructure that combines two complementary ideas: (1) a file‑level caching and intelligent data‑reuse layer, and (2) a “pilot‑job” (file‑pre‑fetch) mechanism that proactively loads or retains files on worker nodes. The caching layer maintains a real‑time mapping between files (identified by cryptographic hashes) and the tasks that need them. By analysing historical access logs, the system classifies files into “hot” (frequently reused) and “cold” (rarely accessed) categories. Hot files are kept in the local disk of a node, allowing subsequent tasks that request the same file to bypass remote I/O entirely. Cold files are either evicted or never prefetched, avoiding unnecessary cache pressure.
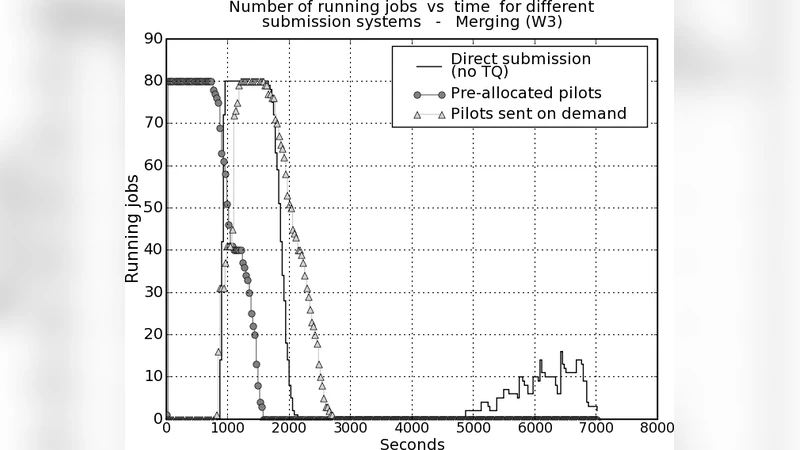
Pilot‑jobs are lightweight, non‑computational jobs whose sole purpose is to populate the cache before the real analysis tasks arrive. Because the scheduler knows that a node already hosts the required input, it can assign a task immediately, eliminating the queue‑to‑execution latency that would otherwise be spent waiting for data staging. The pilot‑job pool is dynamically sized: the system monitors cache hit rates, node memory usage, and overall cluster load, scaling the number of pilot‑jobs up or down to keep the cache effective without causing memory thrashing.
The scheduling algorithm itself is made “intelligent” by incorporating data locality as a primary metric. When a task becomes ready, the scheduler evaluates a score for each candidate node based on (a) the number of required files already present locally, (b) the estimated I/O cost if the files had to be fetched, (c) the predicted CPU time of the task, and (d) the current load on the node. A machine‑learning model trained on historic workflow runs predicts I/O demand and execution time, allowing the scheduler to balance between minimizing data movement and avoiding node overload. This dual‑objective approach replaces the simple FIFO or priority‑only policies used in many grid systems.
The authors validate their design in two experimental phases. First, they deploy the system on a production CMS Tier‑0 workflow consisting of roughly 3,200 tasks and 250 TB of input data. Compared with the baseline CMS production system, the new infrastructure reduces total workflow TAT by an average of 31 %, with data‑transfer latency alone dropping by more than 45 %. The improvement is most pronounced for tasks whose input files are shared among many downstream jobs.
Second, they construct a controlled simulation environment to explore scalability and sensitivity to workload characteristics. By varying the number of tasks (from a few hundred to tens of thousands), the proportion of hot files, and the network bandwidth, they observe that when the cache hit ratio exceeds about 60 %, the marginal benefit of additional pilot‑jobs diminishes, and the optimal number of pilot‑jobs scales roughly linearly with cluster size. The simulation also highlights a potential pitfall: excessive pilot‑job deployment can saturate node memory and cause cache eviction, which in turn degrades performance. This insight motivates the need for the adaptive scaling logic described earlier.
Key contributions of the work are:
- A unified file‑level caching and pilot‑job framework that enables proactive data placement and reuse across thousands of tasks.
- An intelligent, locality‑aware scheduler that jointly optimizes for data‑access latency and load balancing, backed by a predictive ML model.
- Empirical evidence from both real CMS production runs and large‑scale simulations demonstrating up to a 31 % reduction in overall workflow turnaround time.
The authors argue that while the study is rooted in the CMS experiment, the principles are broadly applicable to any data‑intensive scientific workflow, such as genomics pipelines, large‑scale machine‑learning training, or Earth‑observation data processing. Future work is outlined in three directions: (i) extending the framework to multi‑cloud or hybrid‑cloud environments while preserving cache consistency, (ii) refining the ML‑based I/O prediction with richer feature sets (e.g., file size distribution, network congestion metrics), and (iii) integrating automatic pilot‑job scaling into existing workload management systems (e.g., HTCondor, PanDA) to provide seamless adoption.
In conclusion, by tackling the four major latency sources—resource discovery, queue waiting, scheduling decision, and data access—through a combination of intelligent caching, proactive pilot‑jobs, and locality‑aware scheduling, the proposed approach delivers a substantial performance uplift for complex scientific workflows. This work sets a practical blueprint for next‑generation high‑throughput computing infrastructures that must handle ever‑growing data volumes with stringent time constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment