Semi-Supervised Anomaly Detection - Towards Model-Independent Searches of New Physics
Most classification algorithms used in high energy physics fall under the category of supervised machine learning. Such methods require a training set containing both signal and background events and are prone to classification errors should this tra…
Authors: Mikael Kuusela, Tommi Vatanen, Eric Malmi
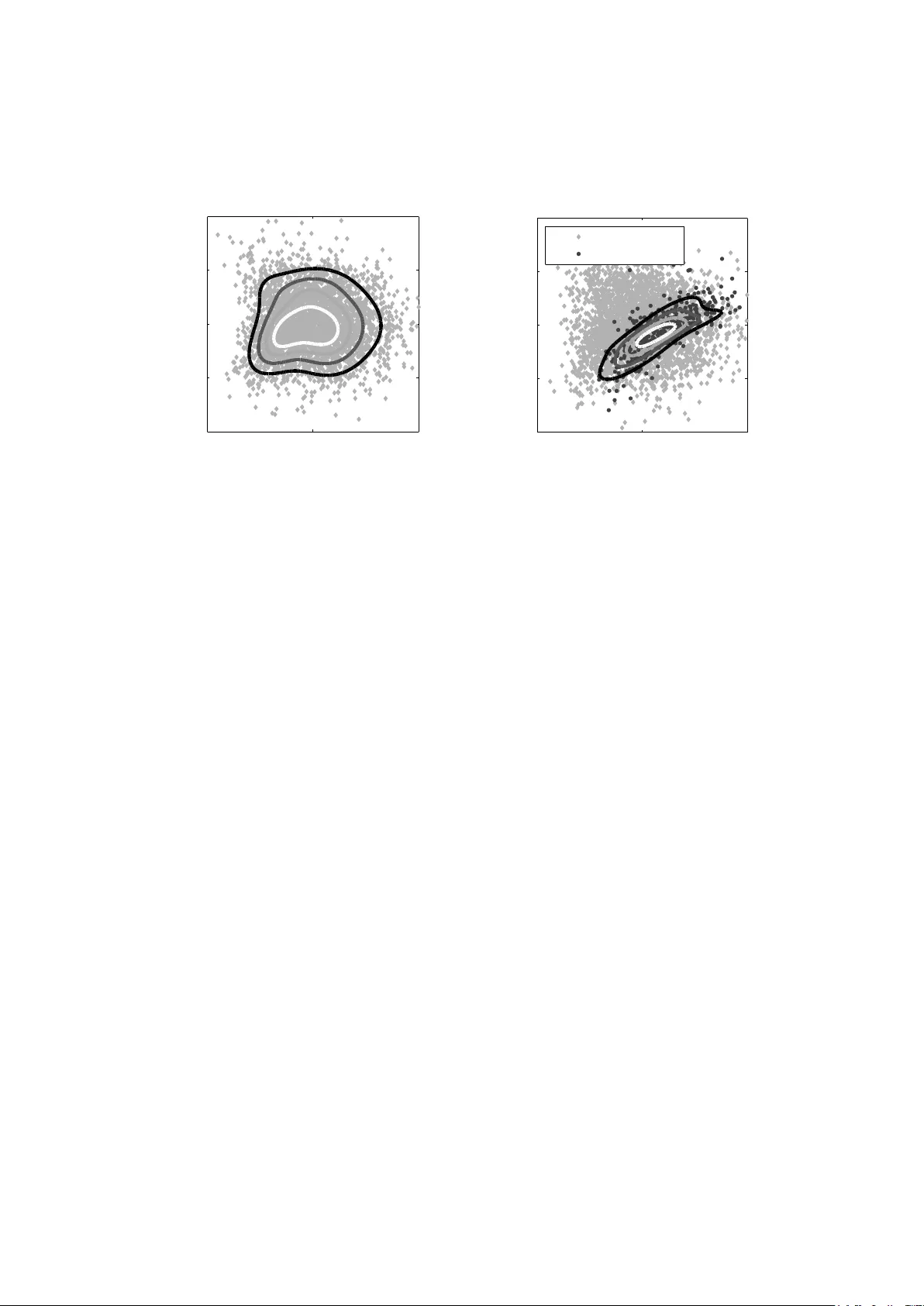
Semi-sup ervised anomaly detection – to w ards mo del-indep enden t searc hes of new ph ysics Mik ael Kuusela 1 , 2 , T ommi V atanen 1 , 2 , Eric Malmi 1 , 2 , T apani Raiko 2 , Timo Aaltonen 1 and Y oshik azu Nagai 3 1 Helsinki Institute of Ph ysics, PO Bo x 64, FI-00014 Univ ersit y of Helsinki, Finland 2 Aalto Univ ersit y , Department of Information and Computer Science, PO Bo x 15400, FI-00076 Aalto, Finland 3 Univ ersity of Tsukuba, 1-1-1 T enno dai, Tsukuba, Ibaraki 305-8577, Japan E-mail: { mikael.kuusela,tommi.vatanen,eric.malmi } @aalto.fi Abstract. Most classification algorithms used in high energy ph ysics fall under the category of sup ervised machine learning. Suc h metho ds require a training set con taining b oth signal and bac kground even ts and are prone to classification errors should this training data b e systematically inaccurate for example due to the assumed MC mo del. T o complemen t suc h mo del-dependent searc hes, we propose an algorithm based on semi-supervised anomaly detection tec hniques, which does not require a MC training sample for the signal data. W e first mo del the bac kground using a multiv ariate Gaussian mixture model. W e then searc h for deviations from this mo del by fitting to the observ ations a mixture of the background model and a n umber of additional Gaussians. This allo ws us to perform pattern recognition of any anomalous excess o ver the background. W e show by a comparison to neural netw ork classifiers that such an approach is a lot more robust against missp ecification of the signal MC than supervised classification. In cases where there is an unexp ected signal, a neural netw ork might fail to correctly iden tify it, while anomaly detection do es not suffer from such a limitation. On the other hand, when there are no systematic errors in the training data, b oth metho ds p erform comparably . 1. In tro duction Mac hine learning techniques hav e b een extensively used in high energy ph ysics data analysis o ver the past few decades [1]. Esp ecially sup ervised, m ultiv ariate classification algorithms, such as neural netw orks and b o osted decision trees, ha ve b ecome commonplace in state-of-the-art ph ysics analyses and hav e prov en to b e inv aluable to ols in increasing the signal-to-background ratio in searc hes of tiny signals of new physics. Such metho ds work under the assumption that there exists lab eled data sets of signal and bac kground even ts whic h can b e used to train the classification algorithm. These training samples are usually obtained from Monte Carlo (MC) sim ulation of the new physics pro cess and the corresponding Standard Mo del bac kground. Sup ervised mac hine learning algorithms are the to ols of mo del-dep enden t new physics searc hes. In the b eginning of the analysis, one decides to fo cus on a particular v ariant of a certain new ph ysics mo del. This could b e for example a certain SUSY parametrization. Even ts corresp onding to this choice are then generated using a MC generator follow ed by training of a classification algorithm to optimize the yield of such ev en ts. In the b est case scenario, applying this classifier to real observed data would pro duce a statistically significant excess ov er −5 0 5 10 −4 −2 0 2 4 6 8 x y (a) Training data Background Signal −5 0 5 10 −4 −2 0 2 4 6 8 x y (b) Observations Background Signal Figure 1. Demonstration of the limitations of mo del-dep endent searc hes of new ph ysics. When a neural netw ork is trained with the data of the left figure, the classification decision b oundary is given b y the black curv e. But if the training data is systematically inaccurate, a new physics signal could b e completely missed in the analysis. F or example all the observ ations of the right figure would b e classified as bac kground. the Standard Mo del background and result in a disco v ery of new b eyond the Standard Mo del ph ysics. Unfortunately , this pro cess could go wrong on several different levels. Firstly , there are no guaran tees that nature actually ob eys an y of the existing theoretical new ph ysics mo dels. The solution to the existing problems with the Standard Mo del could b e something that no one has even thought of yet. Ev en if one of the existing theories is the right wa y forw ard, such mo dels often hav e a large amount of free parameters. Exploring the whole high-dimensional parameter space one combination of v alues at a time could b e a very lab orious, time-consuming and error-prone pro cess. Lastly , MC simulation of suc h pro cesses often requires simplifications and approximations and could b e a ma jor source of systematic errors in its own righ t. This kind of uncertainties and systematic errors are not well-tolerated b y sup ervised classification algorithms. Figure 1 illustrates the problem. When a neural netw ork was trained using the signal and bac kground data of Figure 1a, we obtained the black decision b oundary to separate signal ev en ts from background. But what if due to one of the ab ov e mentioned problems, the real new physics signal lo oked lik e the one in Figure 1b? The algorithm trained with wrong type of training patterns would completely miss suc h a signal. The signal even ts w ould all b e regarded as background even though the data clearly contains a signature of an in teresting anomalous pro cess. While it is p ossible to alleviate this type of problems up to some extent b y tw eaking the training data and the classification algorithm of the sup ervised classifier, a more principled solution is pro vided b y p erforming the new physics searc h in a mo del-indep enden t mo de where, instead of trying to provide an exp erimental v alidation of a particular b eyond the Standard Mo del ph ysics mo del, one is simply lo oking for deviations from kno wn Standard Mo del physics. The goal of mo del-indep enden t new ph ysics searches is to b e sensitive to any deviations from kno wn physics, whether or not they are described b y one of the existing theoretical models. This kind of ideas ha ve b een put forw ard b oth at the T ev atron and at the LHC. F or example, at the CDF exp eriment, a combination of algorithms called Vista and Sleuth w ere used to p erform a global mo del-indep enden t searc h of new physics with early T ev atron Run I I data [2], while an algorithm called MUSiC is currently b eing used to scan the data of the CMS exp eriment at the LHC for such deviations [3]. In this pap er, w e presen t an alternative algorithm for mo del-indep endent searches of new ph ysics based on semi-supervised anomaly detection tec hniques. As opp osed to existing metho ds, our aim is not only to detect deviations from known Standard Mo del ph ysics in a model- indep enden t manner but also to pro duce a mo del for the observ ations which can b e used to further analyze the prop erties of the p otential new ph ysics signal. Our metho d is also inherently m ultiv ariate and binning-free, while the existing metho ds are based on exploiting the prop erties of one-dimensional histograms. 2. Semi-sup ervised detection of collective anomalies 2.1. Motivation Our data analysis problem can be form ulated as follo ws: given a lab eled sample of known physics exp ected to b e seen in the exp eriment and the empirical observ ations, how can we find out if there is a previously unkno wn contribution among the measuremen ts and, if there is, ho w can w e study its prop erties? In statistics, such a problem is solv ed using semi-sup ervised anomaly detection algorithms [4]. These are algorithms designed to lo ok for deviations from a lab eled sample of normal data. The neural net work based background encapsulator [5] of the trigger of the H1 exp eriment at HERA can, for instance, b e regarded as an example of suc h an algorithm. Unfortunately , existing semi-sup ervised anomaly detection algorithms can rarely b e directly applied to solve the mo del-indep endent searc h problem. This is b ecause they are designed to classify observ ations as anomalies should they fall in regions of the data space where there is a small densit y of normal observ ations. The problem is that in man y theoretical mo dels the excess of ev ents corresp onding to the new physics signal app ears among the bulk of the background distribution instead of the tail regions considered by standard anomaly detection algorithms. W e solve the problem b y exploiting the fact that if there is a new physics signal, it should o ccur as a collection of several ev ents whic h, only when considered together, constitute an anomalous deviation from the Standard Mo del. 2.2. Fixe d-b ackgr ound mo del for anomaly dete ction W e start by fitting a parametric density estimate p B ( x ) to a lab eled background sample. This densit y estimate, which w e call the b ackgr ound mo del , serv es as a reference of normal data. W e conduct a searc h for collectiv e deviations from the background mo del by fitting to the observ ations a mixture of p B ( x ) and an additional anomaly mo del p A ( x ): p FB ( x ) = (1 − λ ) p B ( x ) + λp A ( x ) . (1) W e call this mixture mo del the fixe d-b ackgr ound mo del to emphasize that when modeling the observ ations, p B ( x ) is k ept fixed which allo ws p A ( x ) to capture any unmo deled anomalous con tributions in the data. Fitting of b oth p B ( x ) and p FB ( x ) to the data is done by maximizing the likelihoo d of the mo del parameters. P attern recognition of the anomalies with the fixed-bac kground mo del enables a v ariet y of data analysis tasks: (i) Classific ation : Observ ations can b e classified as anomalies using the p osterior probability as a discriminant function p (anomaly | x ) = λp A ( x ) (1 − λ ) p B ( x ) + λp A ( x ) =: D ( x ) . (2) An observ ation x is then classified as an anomaly if D ( x ) ≥ T for some threshold T ∈ [0 , 1]. −20 −10 0 10 0 p(x) (a) Background data p B (x) −20 −10 0 10 0 p(x) (b) Unlabeled data p FB (x) p A (x) Figure 2. (a) A histogram of background data from a univ ariate Gaussian distribution and an estimated background mo del p B ( x ). (b) An illustration of the fixed-background mo del in a univ ariate case. The histogram shows the unlab eled observ ations (the gray excess in the histogram denotes the anomalous contribution). The estimated fixed-background mo del p FB ( x ) is shown with a blac k line and the anomaly mo del p A ( x ) with a gray line. (ii) Pr op ortion of anomalies : The mixing prop ortion of the anomaly mo del λ directly giv es us an estimate for the prop ortion of anomalies in the observ ations. This could be further used to derive a cross section estimate for the anomalous physics pro cess. (iii) Statistic al signific anc e : The statistical significance of the anomaly mo del can b e estimated b y p erforming a statistical test for the background-only n ull h yp othesis λ = 0 using the lik eliho o d ratio test statistic Λ [6]. This enables us to discriminate betw een statistical fluctuations of the background and real anomalous pro cesses. F ollo wing [7], we obtain the distribution of the test statistic using nonparametric b o otstrapping. That is, we sample with replacemen t observ ations from the background data, fit p FB ( x ) to this new sample and compute the corresp onding v alue of Λ. This allows us to recov er the distribution of Λ under the bac kground-only null h yp othesis and hence to compute the significance of the observ ed collective anomaly . As a simple illustration of the fixed-bac kground mo del, Figure 2a shows a univ ariate data set of bac kground data generated from a Gaussian distribution and a maxim um likelihoo d Gaussian densit y p B ( x ) estimated using the data set. Figure 2b shows a v ery simple anomalous pattern that can be mo deled with a single additional univ ariate Gaussian. Given a sample contaminated with these anomalies, our goal is to find an optimal combination of the parameters of the anomaly mo del ( µ A , σ 2 A ) and the mixing prop ortion λ . The resulting mo del p FB ( x ) is shown with a black line and the anomaly mo del p A ( x ) with a gray line in Figure 2b. 2.3. Algorithmic details W e mo del all the densities in Equation (1) using a multiv ariate Gaussian mixture mo del [8] p ( x | θ ) = J X j =1 π j N ( x | µ j , Σ j ) . (3) Here J is the n umber of Gaussian comp onen ts in the mo del. The comp onents hav e means µ j and cov ariances Σ j , while π j are the mixing prop ortions whic h satisfy P j π j = 1. Fitting a Gaussian mixture mo del with J comp onen ts to the bac kground sample by maximizing its log-likelihoo d is a standard problem in computational statistics and can b e carried out using the iterative exp ectation-maximization (EM) algorithm [9]. The algorithm pro ceeds in tw o steps. In the exp e ctation step (E-step), we compute the p osterior probabilities for each data p oint x i to hav e b een generated b y the j th Gaussian component p ( z ij = 1 | x i , θ k ) = π k j N ( x i | µ k j , Σ k j ) P J j 0 =1 π k j 0 N ( x i | µ k j 0 Σ k j 0 ) =: γ k ij . (4) Here, θ k con tains the parameter estimates at the k th iteration and z i indicates whic h comp onent generated the i th observ ation. In the subsequen t maximization step (M-step), the parameter v alues are up dated according to the following equations: π k +1 j = 1 N N X i =1 γ k ij , µ k +1 j = P N i =1 γ k ij x i P N i =1 γ k ij , Σ k +1 j = P N i =1 γ k ij ( x i − µ k +1 j )( x i − µ k +1 j ) T P N i =1 γ k ij . (5) The algorithm alternates betw een these tw o steps un til the log-likelihoo d is not impro ving an ymore. This gives us an estimate of the bac kground mo del p B ( x ). The next step of the anomaly detection algorithm is to fit to the unlab eled observ ations the fixed-background mo del (1) where the anomaly mo del is a Gaussian mixture model with Q comp onen ts. When we keep the background mo del fixed, the free parameters of the full mo del are the parameters of the anomalous Gaussians, their mixing prop ortions and the global mixing prop ortion λ and we seek to find such v alues of these parameter that their log-likelihoo d is maximized. This can b e done easily by noting that as a mixture of tw o Gaussian mixtures, the fixed-bac kground mo del itself is a Gaussian mixture with J + Q comp onen ts. Hence, w e can use the same EM up date equations as ab o v e to up date the free parameters of the mo del and simply skip the up dates of the fixed parameters. The complete update equations based on this idea can b e found in the technical report [10], where w e also describ e a num b er of heuristics implemented in the algorithm to o vercome the issues related to choosing the mo del complexities J and Q . 3. Demonstration: Searc h for the Higgs b oson W e demonstrate the application potential of the proposed anomaly detection framew ork b y using a data set from the Higgs b oson analysis at the CDF detector. It should b e stressed that the results presented here should not b e regarded as a realistic Higgs analysis. Instead, the goal is to merely demonstrate the p erformance and the p otential b enefits of the prop osed algorithm. 3.1. Description of the data set W e consider a data set pro duced b y the CDF collab oration [11] con taining bac kground even ts and MC sim ulated Higgs ev en ts where the Higgs is pro duced in asso ciation with the W b oson and deca ys into t wo b ottom quarks, q ¯ q → W H → l ν b ¯ b . In the data space, this signal lo oks slightly differen t for different Higgs masses m H . The goal is to show that semi-sup ervised anomaly detection is able to identify such a signal without a priori knowledge of m H . More generally , this could b e any set of free parameters in the new physics theory under consideration. Eac h observ ation in the data set corresp onds to a single simulated collision even t in the CDF detector at the T ev atron proton-antiproton collider. W e follow the even t selection and c hoice of v ariables describ ed in [11] for double SECVTX tagged collision ev ents. W e also consider an additional neural netw ork based flav or separator from [12], giving us a total of 8 v ariables to describ e each ev ent. T o facilitate density estimation and visualization of the results, the dimensionality of the logarithmically normalized data w as reduced to 2 using principal comp onen t analysis (PCA) [13]. W e used 3406 data p oints to train the bac kground mo del which was then used to detect signals of 400 data p oints for masses m H = 100 , 115 , 135 , 150 GeV among another sample of −5 0 5 −4 −2 0 2 4 PCA1 PCA2 (a) Background model p B (x) −5 0 5 −4 −2 0 2 4 PCA1 PCA2 (b) Anomaly model p A (x) Background Signal Figure 3. (a) A pro jection of the WH background data in to its tw o-dimensional principal subspace. The solid lines show contours of the estimated 5-comp onen t Gaussian mixture mo del for the background. (b) A pro jection of the m H = 150 GeV test data set in to the t wo- dimensional principal subspace. The solid lines show con tours of the estimated 2-comp onent Gaussian mixture mo del for the signal. 3406 observ ations of bac kground data. Hence, the unlab eled sample con tained 10.5 % of signal ev ents. In realit y , the exp ected signal is roughly 5 to 50 times weak er than this, but due to the limited num b er of bac kground ev en ts a v ailable, the signal had to b e amplified for this demonstration. Based on exp eriments with artificial toy data rep orted in [10], we exp ect to b e able to detect signals whic h contribute only a few p ercent to the unlabeled sample when we ha v e t wo orders of magnitude larger background statistics. 3.2. Mo deling the Higgs data W e used the cross-v alidation-based information criterion (CVIC) [14] to select a suitable n umber of comp onents J for the background mo del. When a 5-fold cross-v alidation was p erformed, the ev aluation log-likelihoo d w as maximized with J = 5. Figure 3a shows contours of the resulting fiv e-comp onen t background mo del in the tw o-dimensional principal subspace. W e then learned the fixed-background mo dels for the signals with different masses starting with Q = 3 anomalous comp onents. The algorithm conv erged with one anomalous comp onen t for m H = 100 GeV and t wo comp onents for the rest of the masses. The resulting anomaly model for m H = 150 GeV is shown in Figure 3b. 3.3. Anomaly dete ction r esults The statistical significances of the anomaly mo dels w ere ev aluated using the b o otstrap tec hnique with 50 000 resamplings. The significances, starting from the low est mass, w ere 1 . 8 σ , 2 . 8 σ , 3 . 1 σ and 3 . 3 σ . Hence, in our to y analysis, all the signals w ould hav e b een significan t enough to dra w closer attention. Figure 4a shows the receiver op erating ch aracteristic (R OC) curves for anomaly detection with different Higgs masses. One can see that regardless of the mass of the Higgs, the algorithm is able to identify the signal with a relatively constan t accuracy . The classification results are sligh tly b etter with the higher masses because the high-mass signal lies on a region of the data space with a low er background density . Starting from the low est mass, the estimated anomaly 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Signal efficiency Background rejection (a) Anomaly detection for the WH data 150 GeV 135 GeV 115 GeV 100 GeV 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Signal efficiency Background rejection (b) Neural network for the WH data 150 GeV 135 GeV 115 GeV 100 GeV Figure 4. (a) ROC curves for the WH data with differen t Higgs masses m H with semi-supervised anomaly detection. The metho d is able to identify the signal without a priori knowledge of the mass. (b) ROC curves for the WH data for a neural netw ork classifier trained with the 150 GeV signal. The neural netw ork is able to efficien tly identify only the signal it has b een trained for. prop ortions are λ = 0 . 100 , 0 . 121 , 0 . 118 , 0 . 122, whic h are all in agreemen t with the correct prop ortion of 0.105. W e also trained a sup ervised MLP neural net work for eac h of the mass p oints to act as an “optimal” reference classifier and compared the ROC curves to the ones obtained with anomaly detection. Figure 4b sho ws the ROC curves for a neural netw ork trained with the 150 GeV signal and tested with all the mass p oints. When the neural netw ork was tested and trained with the same mass, the R OC curv e was comparable to anomaly detection, whic h shows that the prop osed mo del-indep endent framework is able to achiev e similar p erformance as mo del- dep enden t sup ervised classification. How ever, when the neural netw ork w as tested with a mass differen t from its training mass, its p erformance started to decline. F or example the 150 GeV neural net work w ould b e lik ely to miss the 100 GeV signal. On the other hand, anomaly detection is able to successfully identify the signal regardless of the mass. In other words, this exp eriment sho ws that sup ervised classifiers are able to efficiently iden tify only the signals they hav e b een trained for with p otentially severe consequences, while mo del-indep endent approac hes, suc h as semi-sup ervised anomaly detection, do not suffer from such a limitation. 4. Discussion The semi-sup ervised anomaly detection algorithm could b e used to scan the measurements for new physics signals by fo cusing on some particular final state which is though t to b e esp ecially sensitiv e to new physics. One could then use the framew ork to lo ok for deviations from the exp ected Standard Mo del background in this final state. If a statistically significant anomaly is found, one could use the fixed-bac kground mo del to study its prop erties. Since the anomalous ev ents are likely to lie within the bulk of the background, the b est w a y to reconstruct their prop erties would b e a soft classification based approach [15] where the con tribution of a single ev ent to some physical observ able is weigh ted b y the p osterior class probability of the ev en t. Reconstructing a num b er of physical sp ectra for the anomaly should allo w one to pro duce a ph ysics interpretation for the observ ed deviation. It is lik ely that most observed anomalies corresp ond detector effec ts and background mismo deling. If this is determined to b e the case, new cuts could b e in tro duced to isolate such regions or the background estimate could b e corrected to account for the anomaly . The analysis could then b e rep eated iteratively until all anomalies are understo o d. If at some stage we encounter a significant anomaly whic h cannot b e explained by just adjusting the bac kground estimate, it could b e a sign of new physics and should b e studied further to see if there is a plausible new ph ysics interpretation for it. The computational exp eriments of this pap er were carried out using well-un dersto o d standard tec hniques from computational statistics in order to con vey the basic idea of semi-sup ervised anomaly detection as clearly as p ossible. It is lik ely that some of the shortcomings of the algorithm could b e alleviated b y using more adv anced computational to ols. One of the obvious limitations of the algorithm is the curse of dimensionalit y . With a reasonable sample size, the algorithm seems to perform relativ ely w ell up to three dimensions, but b eyond that, the num b er of observ ations required to estimate the parameters of the Gaussian mixture mo dels b ecomes prohibitiv ely large. W e demonstrated with the Higgs example that one p ossible wa y of solving the problem is dimensionalit y reduction with PCA or some other dimensionality reduction algorithm. Another p ossibility would b e to consider parsimonious Gaussian mixture mo dels, where the num b er of parameters is reduced by constraining the structure of the cov ariance matrices [16]. The curren t algorithm is also only able to handle anomalies whic h manifest themselv es as an excess ov er the bac kground. That is, a deficit with resp ect to the background estimate is not treated prop erly , although it migh t b e p ossible to circumv en t this restriction b y allo wing λ to tak e negative v alues. 5. Conclusions W e presented a no vel and self-consisten t framework for model-indep endent searches of new ph ysics based on a semi-sup ervised anomaly detection algorithm. W e show ed using a Higgs b oson data set that the metho d can b e successfully applied to searches of new physics and demonstrated the potential benefits of the approac h with resp ect to con v entional analyses. T o make sure that no new physics signals hav e b een missed b y the curren t mo del-dep endent searc hes, it w ould b e imp ortan t to complement them by scanning the collision data with mo del- indep enden t tec hniques, one example of which is the prop osed anomaly detection framework. W e hop e that the work presented here helps to reviv e interest in such techniques among the HEP comm unity by sho wing that mo del-indep enden t new physics searches can be conducted in a feasible and practical manner. Ac knowledgmen ts The authors are grateful to the CDF collab oration for pro viding access to the Higgs signal and bac kground Monte Carlo samples, to the Academ y of Finland for financial supp ort and to Matti P¨ oll¨ a, Timo Honkela and Risto Orav a for v aluable advice. References [1] Bhat P C 2011 Annual R eview of Nuclear and Particle Scienc e 61 281–309 [2] CDF Collab oration 2008 Physic al R eview D 78 (1) 012002 [3] CMS Collab oration 2008 MUSiC – an automated scan for deviations b etw een data and Mon te Carlo sim ulation CMS P AS EXO-08-005 [4] Chandola V, Banerjee A and Kumar V 2009 ACM Computing Surveys 41 (3) 15:1–15:58 [5] Ribarics P et al. 1993 Pr o c ee dings of the Thir d International Workshop on Softwar e Engine ering, Artificial Intel ligenc e and Exp ert Systems for High Ener gy and Nucle ar Physics, AIHENP93 pp 423–428 [6] Knight K 2000 Mathematic al Statistics (Chapman and Hall) [7] W ang S, W o o dward W A, Gray H L, Wiec hecki S and Sain S R 1997 Journal of Computational and Gr aphic al Statistics 6 285–299 [8] McLachlan G and Peel D 2000 Finite Mixtur e Models (Wiley-Interscience) [9] McLachlan G J and Krishnan T 2008 The EM Algorithm and Extensions 2nd ed (Wiley-Interscience) [10] V atanen T, Kuusela M, Malmi E, Raiko T, Aaltonen T and Nagai Y 2011 Fixed-background EM algorithm for semi-sup ervised anomaly detection T ec h. rep. Aalto Universit y School of Science [11] Nagai Y et al. 2009 Search for the Standard Model Higgs b oson production in asso ciation with a W b oson using 4.3/fb CDF/PUB/EXOTIC/PUBLIC/9997 [12] Chw alek T et al. 2007 Up date of the neural netw ork b tagger for single-top analyses CDF/ANAL/TOP/CDFR/8903 [13] Jolliffe I T 2002 Princip al Comp onent Analysis 2nd ed (Springer) [14] Smyth P 2000 Statistics and Computing 10 (1) 63–72 [15] Kuusela M, Malmi E, Orav a R and V atanen T 2011 AIP Confer enc e Pr o ce e dings 1350 111–114 [16] F raley C and Raftery A E 2002 Journal of the Americ an Statistical Association 97 611–631
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment