Query Driven Visualization of Astronomical Catalogs
Interactive visualization of astronomical catalogs requires novel techniques due to the huge volumes and complex structure of the data produced by existing and upcoming astronomical surveys. The creation as well as the disclosure of the catalogs can be handled by data pulling mechanisms. These prevent unnecessary processing and facilitate data sharing by having users request the desired end products. In this work we present query driven visualization as a logical continuation of data pulling. Scientists can request catalogs in a declarative way and set process parameters directly from within the visualization. This results in profound interoperation between software with a high level of abstraction. New messages for the Simple Application Messaging Protocol are proposed to achieve this abstraction. Support for these messages are implemented in the Astro-WISE information system and in a set of demonstrational applications.
💡 Research Summary
The paper addresses the challenge of interactively visualizing the massive astronomical catalogs produced by current and upcoming surveys such as KiDS, VIKING, and Euclid. Traditional visualization techniques struggle with the terabyte‑scale data volumes and the complex, multi‑stage processing pipelines that generate these catalogs. To overcome these limitations, the authors extend the concept of data pulling—a mechanism where a user declares the desired end‑product (a catalog) and the system automatically determines which existing data can satisfy the request, creating new derived products only when necessary. This approach guarantees full data lineage, maximizes re‑use, and eliminates unnecessary computation.
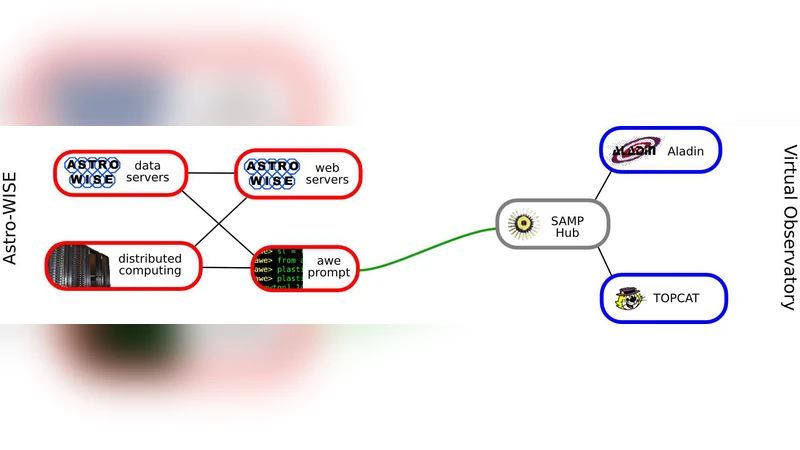
Building on data pulling, the authors propose “query‑driven visualization,” a methodology that integrates the data‑pulling logic directly into the visualization workflow. Scientists can issue declarative queries (e.g., “select sources with R < 300 and return absolute magnitude and inverse concentration index”) from within a visualization client. The client then sends specially designed SAMP (Simple Application Messaging Protocol) messages to the back‑end information system. Two primary message types are introduced:
- target.catalog.pull – requests that the system either retrieve an existing catalog or create a new one that satisfies the query, and then transmit the resulting table to the client using standard SAMP table‑load messages (VOTable or FITS).
- target.catalog.derive – performs the same derivation logic but does not transmit the data; it is used when the client only needs to inspect the derivation path or verify that required data already exist.
Both messages carry three parameters: a catalog identifier (which may refer to an existing catalog or a placeholder for a future product), a selection criterion expressed in a logical language (the authors suggest ADQL‑style WHERE clauses), and a list of requested attributes. The information system (implemented in Astro‑WISE) resolves these parameters by traversing the full data lineage, locating the necessary source collections, and automatically generating any missing intermediate products.
To enable deeper interaction with the data lineage, the authors also define a set of object‑level SAMP messages:
- target.object.info – returns a map describing an object’s properties, processing status, and possible actions.
- target.object.change – allows the client to modify a property (e.g., a processing parameter) of a persistent object.
- target.object.action – triggers a predefined action on the object.
- target.object.highlight – asks the system to visually highlight a specific object in any connected client.
These messages let a visualization client not only display data but also explore and influence the underlying processing pipeline in real time.
The implementation is demonstrated within the Astro‑WISE environment, which stores catalogs as “Source Collections” (process targets) and maintains full lineage through backward chaining. SAMP connectivity is added to Astro‑WISE’s interactive Python prompt (awe‑prompt) and to its web‑based DBViewer. Three proof‑of‑concept applications illustrate the workflow:
- Simple Puller – a minimal web interface that gathers the three required parameters and sends a target.catalog.pull message. The resulting table is displayed in external tools such as Topcat.
- Tree Viewer – visualizes the dependency graph of a derived catalog as a DOT graph. Clicking a node sends target.object.highlight, and the client can request detailed object info via target.object.info.
- Object Viewer – provides a richer GUI that uses target.object.info, target.object.change, and target.object.action to let users inspect and modify process‑target properties (e.g., change a photometric calibration parameter) without leaving the visualization environment.
These prototypes show that users can obtain customized subsets of catalogs without needing detailed knowledge of the underlying database schema, and they can adjust processing parameters on the fly, prompting the system to recompute only the affected parts of the lineage.
The authors’ contributions are fourfold:
- Processing minimization – only the data required for the visualized subset are generated, reducing compute load.
- Declarative abstraction – users formulate high‑level queries; the SAMP messages hide the complexity of table joins, schema navigation, and processing steps.
- Lineage exposure and manipulation – the system returns full provenance information and permits interactive modification of processing parameters, supporting exploratory science and reproducibility.
- SAMP‑based interoperability – by extending the SAMP protocol with domain‑specific message types, the approach works across heterogeneous tools (Topcat, Aladin, custom web clients) while keeping the back‑end agnostic to the specific visualization software.
In summary, the paper demonstrates a viable path toward scalable, interactive exploration of petabyte‑scale astronomical catalogs. By marrying data pulling with a query‑driven, SAMP‑mediated visualization layer, the authors provide a framework that can be adopted by future large surveys (e.g., Euclid, LSST) to enable scientists to query, visualize, and iteratively refine their data products without the overhead of manual data handling or deep database expertise.
Comments & Academic Discussion
Loading comments...
Leave a Comment