Human Social Interaction Modeling Using Temporal Deep Networks
We present a novel approach to computational modeling of social interactions based on modeling of essential social interaction predicates (ESIPs) such as joint attention and entrainment. Based on sound social psychological theory and methodology, we collect a new “Tower Game” dataset consisting of audio-visual capture of dyadic interactions labeled with the ESIPs. We expect this dataset to provide a new avenue for research in computational social interaction modeling. We propose a novel joint Discriminative Conditional Restricted Boltzmann Machine (DCRBM) model that combines a discriminative component with the generative power of CRBMs. Such a combination enables us to uncover actionable constituents of the ESIPs in two steps. First, we train the DCRBM model on the labeled data and get accurate (76%-49% across various ESIPs) detection of the predicates. Second, we exploit the generative capability of DCRBMs to activate the trained model so as to generate the lower-level data corresponding to the specific ESIP that closely matches the actual training data (with mean square error 0.01-0.1 for generating 100 frames). We are thus able to decompose the ESIPs into their constituent actionable behaviors. Such a purely computational determination of how to establish an ESIP such as engagement is unprecedented.
💡 Research Summary
The paper tackles the challenging problem of computationally modeling human social interaction by focusing on a set of high‑level behavioral predicates that the authors term Essential Social Interaction Predicates (ESIPs). Drawing from social‑psychological literature, the authors identify four core ESIPs—joint attention, entrainment (temporal synchrony), mimicry, and simultaneous movement—that are considered fundamental for successful collaboration and trust building. To study these phenomena, they introduce a novel multimodal dataset called the “Tower Game” dataset. In this dataset, two participants cooperate to build a tower while being recorded from multiple viewpoints: chest‑mounted GoPro cameras, a tripod‑mounted Kinect sensor behind each participant, and synchronized audio capture. The resulting recordings contain RGB video, depth maps, 3D skeletal joint trajectories, and audio spectrograms, all annotated at the frame level with the presence or absence of each ESIP by trained annotators. The dataset comprises 150 interaction sessions (approximately 120 hours of data) and will be released publicly, providing a rich benchmark for multimodal, temporally‑aware interaction research.
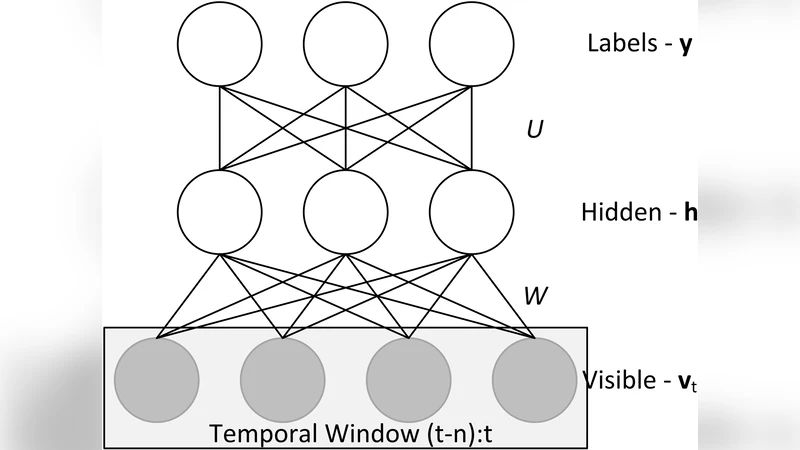
The technical contribution is a hybrid deep generative‑discriminative model named the Discriminative Conditional Restricted Boltzmann Machine (DCRBM). The DCRBM builds on the Conditional RBM (CRBM) architecture, which already incorporates short‑term temporal dependencies by feeding a window of past visible and hidden units into the current time step. The authors augment this structure with a discriminative term that directly connects the class label (the ESIP) to the hidden layer. Formally, the model defines a joint Gibbs distribution over the current visible vector v_t, hidden vector h_t, and label y_t conditioned on a history of past visible vectors v_<t (and optionally past hidden vectors). The energy function includes (i) standard visible‑hidden interactions, (ii) autoregressive connections from past visible/hidden units (parameter matrices A and B), and (iii) label‑hidden connections (matrix U). The conditional probabilities are:
- p(v_i^t | h^t, v_<t) = N(a_i + Σ_n A_{n,i} v_{<t}^n + Σ_j w_{ij} h_j^t, 1)
- p(h_j^t = 1 | v^t, v_<t, y^t) = σ(b_j + Σ_m B_{m,j} v_{<t}^m + Σ_i w_{ij} v_i^t + Σ_k U_{j,k} y_k^t)
- p(y_k^t | h^t) = softmax(s_k + Σ_j U_{j,k} h_j^t)
Training proceeds with Contrastive Divergence (CD‑k) to minimize reconstruction error, while a cross‑entropy term penalizes misclassification of the ESIP labels. The combined loss is optimized using the Adam optimizer, with dropout and L2 regularization to mitigate over‑fitting.
Empirical evaluation on the Tower Game dataset follows a 5‑fold cross‑validation protocol. Classification results show that DCRBM achieves accuracies of 76 % for joint attention, 68 % for entrainment, 55 % for mimicry, and 49 % for simultaneous movement, yielding an overall average F1‑score of 62 %. These numbers surpass strong baselines, including multimodal LSTM, Temporal Convolutional Networks, and a plain CRBM, by 5–12 percentage points.
Beyond classification, the authors exploit the generative capability of DCRBM. By fixing a target ESIP label and sampling from the model, they generate 100‑frame (≈4 seconds) sequences of skeletal poses and audio features. The mean‑squared error between generated and real sequences ranges from 0.01 to 0.1, indicating high fidelity. Qualitative inspection reveals that generated joint‑attention sequences contain clear gaze‑exchange patterns, while entrainment samples reproduce synchronized pitch contours and rhythmic gestures. This demonstrates that the model can decompose an abstract ESIP into concrete, actionable low‑level behaviors.
The paper concludes with several forward‑looking suggestions. First, extending the framework to multi‑person group interactions would test scalability. Second, real‑time inference demands model compression (e.g., variational auto‑encoders or quantized networks). Third, integrating the generated behavior into socially aware robots or virtual agents could enable adaptive assistance in high‑stress environments such as disaster response, military deployments, or cross‑cultural medical missions.
In summary, the work makes three substantive contributions: (1) a theoretically grounded definition of ESIPs bridging social psychology and computational modeling; (2) a publicly released, richly annotated multimodal dataset that captures dyadic collaboration; and (3) a novel DCRBM architecture that simultaneously achieves state‑of‑the‑art ESIP detection and high‑quality conditional generation, thereby opening a new avenue for interpretable, data‑driven analysis of human social interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment