Small world yields the most effective information spreading
Spreading dynamics of information and diseases are usually analyzed by using a unified framework and analogous models. In this paper, we propose a model to emphasize the essential difference between information spreading and epidemic spreading, where the memory effects, the social reinforcement and the non-redundancy of contacts are taken into account. Under certain conditions, the information spreads faster and broader in regular networks than in random networks, which to some extent supports the recent experimental observation of spreading in online society [D. Centola, Science {\bf 329}, 1194 (2010)]. At the same time, simulation result indicates that the random networks tend to be favorable for effective spreading when the network size increases. This challenges the validity of the above-mentioned experiment for large-scale systems. More significantly, we show that the spreading effectiveness can be sharply enhanced by introducing a little randomness into the regular structure, namely the small-world networks yield the most effective information spreading. Our work provides insights to the understanding of the role of local clustering in information spreading.
💡 Research Summary
**
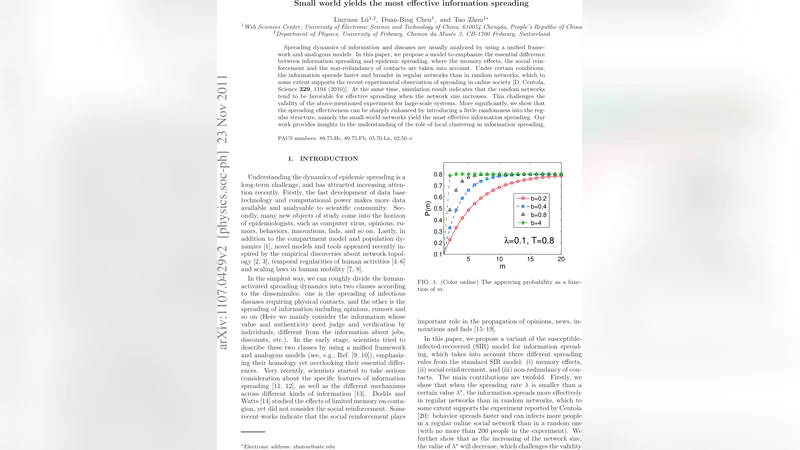
The paper introduces a novel information‑spreading model that explicitly incorporates three mechanisms that are typically absent from classic epidemic models: (i) memory effects, (ii) social reinforcement, and (iii) non‑redundancy of contacts. Each node can be in one of four states—Unknown (susceptible), Known (aware but not yet convinced), Approved (has accepted the information and will transmit it to all neighbors in the next step), and Exhausted (no longer participates). When a node receives the information for the first time, it does so with an approving probability λ; each subsequent exposure increases a cumulative counter m(t). The probability of approval after m exposures is defined as
P(m) = (λ – T) exp
Comments & Academic Discussion
Loading comments...
Leave a Comment