A Naive Bayes Source Classifier for X-ray Sources
The Chandra Carina Complex Project (CCCP) provides a sensitive X-ray survey of a nearby starburst region over >1 square degree in extent. Thousands of faint X-ray sources are found, many concentrated into rich young stellar clusters. However, significant contamination from unrelated Galactic and extragalactic sources is present in the X-ray catalog. We describe the use of a naive Bayes classifier to assign membership probabilities to individual sources, based on source location, X-ray properties, and visual/infrared properties. For the particular membership decision rule adopted, 75% of CCCP sources are classified as members, 11% are classified as contaminants, and 14% remain unclassified. The resulting sample of stars likely to be Carina members is used in several other studies, which appear in a Special Issue of the ApJS devoted to the CCCP.
💡 Research Summary
The paper presents a statistical framework for classifying the ~14,000 X‑ray sources detected in the Chandra Carina Complex Project (CCCP) into four astrophysical categories: foreground Galactic field stars (H1), young pre‑main‑sequence stars belonging to the Carina star‑forming complex (H2), background Galactic field stars (H3), and extragalactic sources such as active galactic nuclei (AGN, H4). The authors adopt a Naïve Bayes classifier, a simple yet powerful machine‑learning technique that combines prior knowledge with observed data to compute posterior class probabilities for each source.
First, the authors construct likelihood functions p(Di|H) for each observable quantity Di (e.g., spatial position, median X‑ray energy, X‑ray variability, J‑band flux, mid‑infrared brightness, presence of infrared excess). These likelihoods are derived from Monte‑Carlo simulations of contaminating populations (Getman et al. 2011) and from empirical distributions of known Carina members. The key assumption is conditional independence of the observables, allowing the joint likelihood to be expressed as the product of the individual one‑dimensional likelihoods. Missing measurements are handled by simply omitting the corresponding term from the product, which means that absent data do not influence the classification.
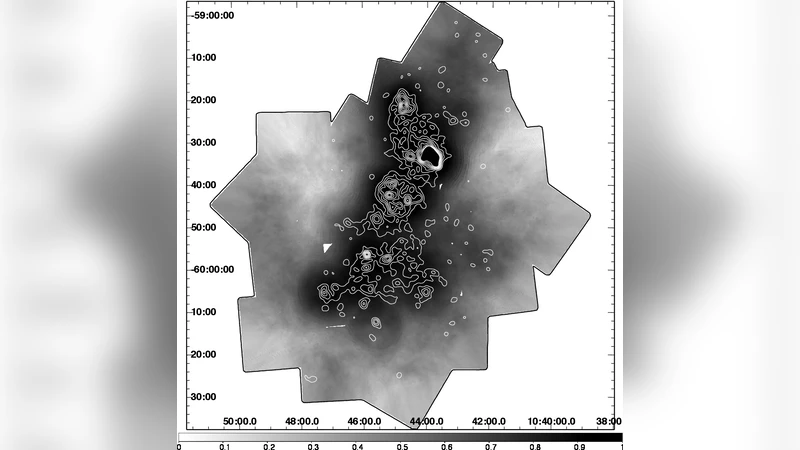
Second, the authors define prior class probabilities. A global prior could be obtained by dividing the expected number of contaminants by the total catalog size, but the authors improve upon this by computing a spatially varying prior for each source. They estimate the local observed source density ρobs(r) and the expected densities of the three contaminant classes (ρH1, ρH3, ρH4), which are essentially uniform across the field. The prior for the Carina member class H2 is then set to the excess of observed density over the summed contaminant densities, ensuring that regions with strong clustering (i.e., known star clusters) receive higher membership priors. This spatial prior map is illustrated in the paper (Figure 2).
Applying Bayes’ theorem, the posterior probability for each class is proportional to the product of the corresponding likelihood and the spatial prior:
p(H|D) ∝ ∏i p(Di|H) × prior(H, r).
The class with the highest posterior probability is assigned to the source, provided the posterior exceeds a chosen confidence threshold; otherwise the source is labeled “unclassified.”
The classification results indicate that 75 % of the CCCP sources are assigned to the Carina member class (H2), 11 % to one of the contaminant classes (H1, H3, H4), and 14 % remain unclassified due to insufficient evidence. Validation against spectroscopically confirmed OB stars, known AGN, and infrared excess sources shows high consistency: OB stars are almost always classified as members, AGN are correctly identified by their extremely faint J‑band and mid‑IR fluxes, and infrared excess sources are preferentially placed in H2.
The authors discuss several limitations. The independence assumption is not strictly valid; for example, higher median X‑ray energy correlates with fainter J‑band flux because both are affected by line‑of‑sight absorption. Similarly, X‑ray variability correlates with X‑ray flux, which in turn relates to stellar mass and infrared brightness. These correlations could bias the posterior probabilities. Moreover, the simulated contaminant models rely on assumptions about Galactic absorption, AGN log N–log S distributions, and instrumental response; any mismatch with reality could lead to systematic misclassifications, especially for faint sources with large measurement uncertainties. The treatment of missing data as “ignored” is pragmatic but discards potentially useful upper‑limit information.
Future work suggested includes moving beyond the naïve independence model to a full Bayesian network that captures conditional dependencies among observables, incorporating hierarchical modeling of measurement errors, and exploring machine‑learning alternatives such as random forests or deep neural networks that can learn complex, non‑linear decision boundaries from labeled training sets. The authors also propose refining the spatial priors by incorporating ancillary data (e.g., molecular cloud maps) to better model the true distribution of young stars versus background objects.
In summary, the paper demonstrates how a relatively simple probabilistic classifier, grounded in astrophysical simulations and spatial priors, can efficiently separate genuine young stellar members of a massive star‑forming region from a substantial background of unrelated Galactic and extragalactic X‑ray sources. The methodology provides a reproducible, quantitative basis for constructing clean member catalogs that underpin subsequent scientific analyses of the Carina complex.
Comments & Academic Discussion
Loading comments...
Leave a Comment