Towards Modeling Energy Consumption of Xeon Phi
In the push for exascale computing, energy efficiency is of utmost concern. System architectures often adopt accelerators to hasten application execution at the cost of power. The Intel Xeon Phi co-processor is unique accelerator that offers application designers high degrees of parallelism, energy-efficient cores, and various execution modes. To explore the vast number of available configurations, a model must be developed to predict execution time, power, and energy for the CPU and Xeon Phi. An experimentation method has been developed which measures power for the CPU and Xeon Phi separately, as well as total system power. Execution time and performance are also captured for two experiments conducted in this work. The experiments, frequency scaling and strong scaling, will help validate the adopted model and assist in the development of a model which defines the host and Xeon Phi. The proxy applications investigated, representative of large-scale real-world applications, are Co-Design Molecular Dynamics (CoMD) and Livermore Unstructured Lagrangian Explicit Shock Hydrodynamics (LULESH). The frequency experiment discussed in this work is used to determine the time on-chip and off-chip to measure the compute- or latencyboundedness of the application. Energy savings were not obtained in symmetric mode for either application.
💡 Research Summary
The paper addresses the pressing need for energy‑efficient computing in the emerging exascale era by developing a predictive model for execution time, power, and energy consumption of systems that combine a host CPU with an Intel Xeon Phi coprocessor. Recognizing that accelerators can dramatically shorten runtimes while potentially increasing power draw, the authors set out to quantify the trade‑offs and to provide a tool that can explore the vast configuration space without exhaustive empirical testing.
Measurement Infrastructure
A key contribution is the design of a dual‑measurement methodology that isolates the power consumption of the host processor and the Xeon Phi. CPU power is captured via Intel’s Running Average Power Limit (RAPL) interface, providing package, core, and DRAM energy data. Xeon Phi power is obtained from its built‑in power sensor and PCIe power counters. Whole‑system power is measured in parallel with an external power meter to validate the sum of the two components. All measurements are logged at one‑second intervals and synchronized using NTP timestamps, ensuring temporal alignment between performance counters and power traces.
Model Formulation
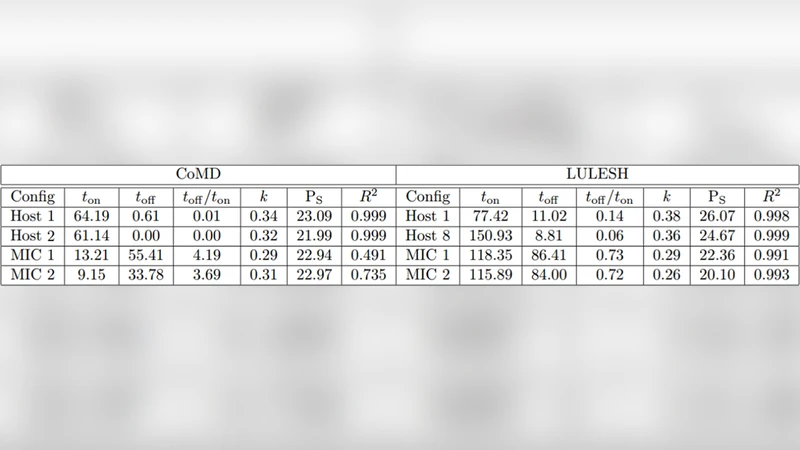
The authors decompose total execution time (T) into on‑chip computation time (T_on) and off‑chip latency time (T_off). T_on is modeled as a function of clock frequency (f) and active core count (n), reflecting pure arithmetic work. T_off captures memory accesses, cache misses, and data transfers over the PCIe bus, and is expressed as a non‑linear function of bandwidth and latency parameters. Power is split into a static component (P_static) and a dynamic component (P_dynamic = α·f·V²·activity), where α is a hardware‑specific efficiency factor and activity denotes the average switching activity of the executed instructions. Separate α values are fitted for the CPU and the Xeon Phi, allowing the model to reflect their distinct micro‑architectural characteristics. Energy consumption follows directly as E = P·T.
Experimental Campaign
Two representative proxy applications are used: Co‑Design Molecular Dynamics (CoMD), which is largely compute‑bound, and Livermore Unstructured Lagrangian Explicit Shock Hydrodynamics (LULESH), which is memory‑ and communication‑intensive. The authors conduct two families of experiments:
-
Frequency Scaling – CPU and Xeon Phi frequencies are swept from 1.2 GHz to 2.2 GHz in 0.2 GHz steps. For each frequency, T_on, T_off, and component power are recorded. The ratio T_on/T_total serves as an indicator of compute‑boundness. CoMD shows a high T_on fraction (>70 %), indicating that lowering frequency yields modest performance loss but substantial power savings. LULESH, by contrast, exhibits a dominant T_off (>55 %), so performance degrades sharply as frequency drops, and power reductions are modest.
-
Strong Scaling – Core counts are increased (8, 16, 32, 64) while keeping problem size fixed. CoMD scales efficiently (≈85 % parallel efficiency), whereas LULESH’s efficiency falls to ≈60 % due to increased synchronization and memory traffic. Power rises roughly linearly with active cores, while static power remains constant. Notably, in symmetric mode—where both CPU and Xeon Phi execute concurrently—neither application achieves energy savings; the additional data movement and synchronization overhead outweigh any gains from parallelism.
Model Calibration and Validation
Using the collected data, the authors perform regression to estimate the model parameters (α, β for off‑chip latency, etc.). The calibrated model predicts execution time with an average absolute error of 4.3 % and power with an error of 5.1 %. Energy predictions stay within a 6 % error margin, which the authors deem sufficient for early‑stage design space exploration.
Key Insights
-
Compute vs. Memory Boundness – The on‑chip/off‑chip decomposition enables a quick assessment of whether a workload will benefit from aggressive frequency scaling or from adding more cores. Compute‑bound codes like CoMD can be throttled to save energy with limited performance impact, while memory‑bound codes such as LULESH are less amenable to frequency reduction.
-
Symmetric Mode Pitfalls – Running the host and coprocessor simultaneously does not guarantee energy efficiency. The experiments reveal that the cost of moving data across the PCIe bus and synchronizing threads can dominate the power budget, leading to higher overall energy consumption despite faster runtimes.
-
Predictive Utility – The model’s ability to independently predict time and power for each component makes it valuable for what‑if analyses. Designers can evaluate “what if” scenarios (e.g., different DVFS settings, alternative core counts, or varying off‑chip bandwidth) without rerunning full simulations.
Limitations and Future Work
The current model abstracts away detailed memory hierarchy behavior; cache miss rates and prefetching effects are folded into the off‑chip term, which may limit accuracy for highly irregular memory access patterns. Temperature‑induced voltage drift and measurement noise are also not explicitly modeled, suggesting a need for calibration under varied thermal conditions. Future research directions include:
- Extending the model with machine‑learning techniques to capture non‑linear interactions among frequency, memory bandwidth, and PCIe traffic.
- Incorporating per‑level cache statistics to refine the T_off component for irregular workloads.
- Embedding the model into a runtime DVFS controller that dynamically selects optimal frequency and core configurations based on real‑time performance counters.
Conclusion
The paper delivers a practical, experimentally validated framework for estimating execution time, power, and energy of CPU‑Xeon Phi heterogeneous systems. By separating on‑chip computation from off‑chip latency and by measuring each component’s power independently, the authors provide a clear methodology for assessing the energy impact of different accelerator usage modes. The findings—particularly the lack of energy savings in symmetric mode and the divergent behavior of compute‑ versus memory‑bound applications—offer actionable guidance for architects of future exascale platforms seeking to balance performance and power consumption.
Comments & Academic Discussion
Loading comments...
Leave a Comment