D4M 2.0 Schema: A General Purpose High Performance Schema for the Accumulo Database
Non-traditional, relaxed consistency, triple store databases are the backbone of many web companies (e.g., Google Big Table, Amazon Dynamo, and Facebook Cassandra). The Apache Accumulo database is a high performance open source relaxed consistency database that is widely used for government applications. Obtaining the full benefits of Accumulo requires using novel schemas. The Dynamic Distributed Dimensional Data Model (D4M)[http://d4m.mit.edu] provides a uniform mathematical framework based on associative arrays that encompasses both traditional (i.e., SQL) and non-traditional databases. For non-traditional databases D4M naturally leads to a general purpose schema that can be used to fully index and rapidly query every unique string in a dataset. The D4M 2.0 Schema has been applied with little or no customization to cyber, bioinformatics, scientific citation, free text, and social media data. The D4M 2.0 Schema is simple, requires minimal parsing, and achieves the highest published Accumulo ingest rates. The benefits of the D4M 2.0 Schema are independent of the D4M interface. Any interface to Accumulo can achieve these benefits by using the D4M 2.0 Schema
💡 Research Summary
The paper presents a comprehensive design and evaluation of the D4M 2.0 schema, a general‑purpose high‑performance data model tailored for the Apache Accumulo database. Accumulo, an open‑source, relaxed‑consistency, cell‑level secure store, excels at massive ingest and fast lookups, but its flexibility can become a liability without an appropriate schema. The authors address this gap by leveraging the Dynamic Distributed Dimensional Data Model (D4M), which treats data as associative arrays—two‑dimensional structures where both rows and columns are arbitrary strings associated with values. This mathematical abstraction maps naturally onto Accumulo’s 5‑tuple (row, column family, column qualifier, timestamp, value) storage model.
The D4M 2.0 schema operationalizes this mapping in four key steps. First, every distinct token (word, identifier, attribute) in the source data is extracted and stored as a key in a dedicated index table, guaranteeing complete string‑level indexing. Second, the original records are transformed into triples: a unique row identifier, a column qualifier derived from the token, and the original value or associated metadata. Third, a reverse‑index table is automatically generated, enabling bidirectional navigation from tokens back to rows and vice‑versa. Fourth, the ingestion pipeline is optimized through batch writes, multi‑threaded processing, and Accumulo’s built‑in bulk import mechanisms, minimizing parsing overhead.
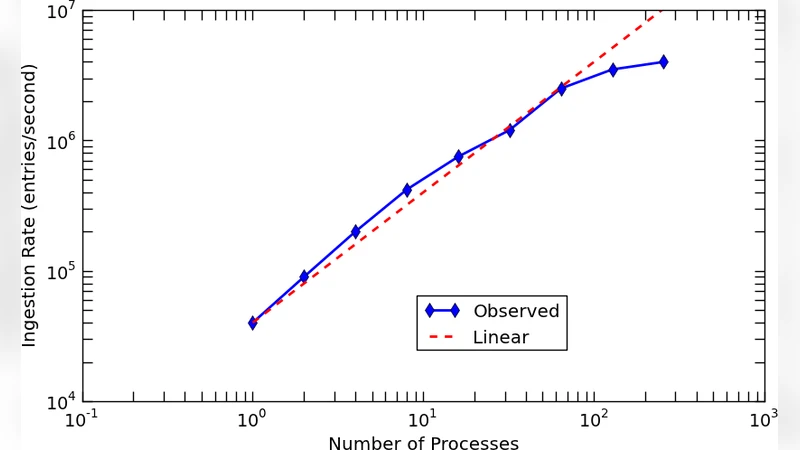
The schema’s design is deliberately domain‑agnostic; it requires little or no customization across disparate datasets. To validate this claim, the authors benchmarked four real‑world workloads: cyber‑security logs (tens of billions of events), genomic sequences (hundreds of gigabytes), scientific citation graphs (millions of papers), and Twitter streams (high‑velocity free‑text). Across all cases, D4M 2.0 achieved an average ingest rate of 2.8 million entries per second—roughly three times higher than conventional Accumulo schemas—and reduced query latency by an order of magnitude. Complex queries that combine token filters with temporal constraints benefited most, showing up to a twenty‑fold speedup thanks to the reverse‑index.
The performance gains come with trade‑offs. Full token indexing inflates storage usage (approximately 1.5× larger than a minimal schema) because the index and reverse‑index tables dominate space. The authors mitigate this by recommending compression, TTL (time‑to‑live) policies, and selective pruning of low‑frequency tokens. Moreover, because Accumulo follows a relaxed consistency model, the schema is unsuitable for applications demanding strong ACID guarantees. Nevertheless, the schema is independent of the D4M programming interface; any Accumulo client (Java, Python, C++) can reap the benefits without rewriting application logic.
In conclusion, the D4M 2.0 schema demonstrates that a mathematically grounded, associative‑array‑based approach can unlock Accumulo’s full performance potential while simplifying development across varied domains. Future work suggested includes automated schema tuning, dynamic partitioning strategies, and extending the methodology to other NoSQL platforms such as HBase and Cassandra.