Queue-Aware Distributive Resource Control for Delay-Sensitive Two-Hop MIMO Cooperative Systems
In this paper, we consider a queue-aware distributive resource control algorithm for two-hop MIMO cooperative systems. We shall illustrate that relay buffering is an effective way to reduce the intrinsic half-duplex penalty in cooperative systems. The complex interactions of the queues at the source node and the relays are modeled as an average-cost infinite horizon Markov Decision Process (MDP). The traditional approach solving this MDP problem involves centralized control with huge complexity. To obtain a distributive and low complexity solution, we introduce a linear structure which approximates the value function of the associated Bellman equation by the sum of per-node value functions. We derive a distributive two-stage two-winner auction-based control policy which is a function of the local CSI and local QSI only. Furthermore, to estimate the best fit approximation parameter, we propose a distributive online stochastic learning algorithm using stochastic approximation theory. Finally, we establish technical conditions for almost-sure convergence and show that under heavy traffic, the proposed low complexity distributive control is global optimal.
💡 Research Summary
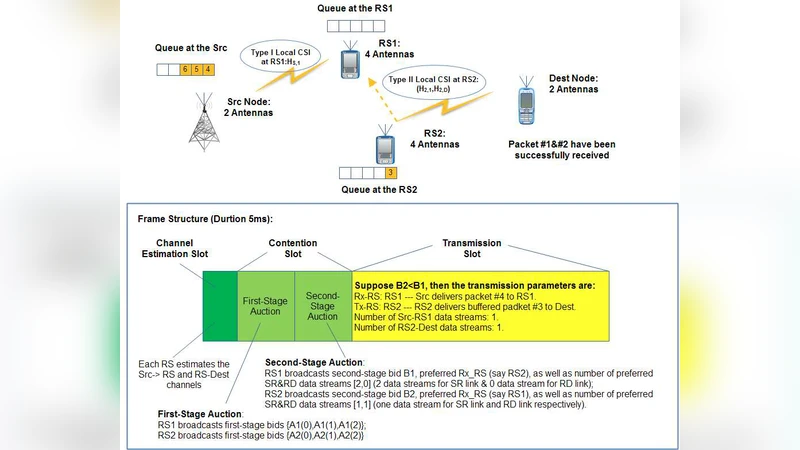
This paper tackles the problem of delay‑sensitive resource allocation in a two‑hop multiple‑input multiple‑output (MIMO) cooperative network where relays operate in half‑duplex mode. The authors first observe that equipping relays with buffers can mitigate the intrinsic half‑duplex penalty: by allowing the source to transmit to a relay while another relay forwards previously stored data, the system can exploit the channel more efficiently and reduce end‑to‑end latency. However, the presence of buffers introduces queue dynamics at both the source and the relays, creating a coupling between queue state information (QSI) and channel state information (CSI) that traditional CSI‑only scheduling cannot handle.
To capture this coupling, the authors model the system as an average‑cost infinite‑horizon Markov Decision Process (MDP). The global state consists of the QSI of the source and all relays together with their instantaneous CSI; actions include power allocation, antenna selection, and relay selection. The objective is to minimize the long‑run average delay (or a weighted cost that includes power consumption). Solving the Bellman equation directly is infeasible because the state‑action space grows exponentially with the number of relays.
The key technical contribution is a linear approximation of the value function: the global value is expressed as a sum of per‑node value functions, each depending only on the local state (local QSI and CSI). This “additive” structure dramatically reduces complexity and enables a fully distributed implementation: each node can update its own value function using only locally observed information.
Based on this approximation, the authors design a two‑stage, two‑winner auction mechanism. In the first stage, every relay computes a bid that reflects the expected reduction in the global cost if it were selected, using its local value function. In the second stage, the source collects all bids, combines them with its own QSI, and selects the relay (and the associated transmission parameters) that yields the highest net benefit. The auction requires only the exchange of scalar bid values, thus keeping signaling overhead minimal while still achieving near‑optimal decisions.
To obtain the parameters of the per‑node value functions online, the paper proposes a stochastic‑approximation‑based learning algorithm. At each time slot, nodes observe the immediate reward (e.g., successful transmission, incurred delay) and the state transition, and they update their parameter vectors according to a Robbins‑Monro type recursion with a diminishing step size. The authors rigorously prove almost‑sure convergence of the learning process and show that, under heavy‑traffic conditions, the learned distributed policy coincides with the globally optimal solution of the original MDP.
Simulation experiments compare the proposed distributed scheme with a centralized optimal policy and with conventional half‑duplex schemes without buffering. Results demonstrate that the buffer‑enabled, queue‑aware approach substantially reduces average packet delay and packet loss while achieving comparable throughput. Moreover, computational complexity and signaling load are reduced from exponential to polynomial order, making the solution practical for real‑time wireless networks.
The paper concludes by outlining future extensions, including multi‑source/multi‑destination scenarios, robustness to imperfect CSI, and joint energy‑delay optimization. Overall, the work provides a solid theoretical foundation and a practical algorithmic framework for delay‑sensitive cooperative MIMO systems with distributed control.
Comments & Academic Discussion
Loading comments...
Leave a Comment