Cosmological Simulations on a Grid of Computers
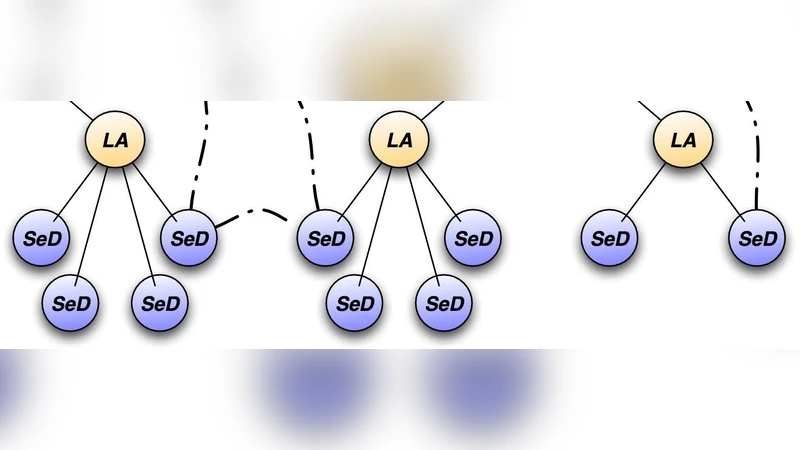
The work presented in this paper aims at restricting the input parameter values of the semi-analytical model used in GALICS and MOMAF, so as to derive which parameters influence the most the results, e.g., star formation, feedback and halo recycling efficiencies, etc. Our approach is to proceed empirically: we run lots of simulations and derive the correct ranges of values. The computation time needed is so large, that we need to run on a grid of computers. Hence, we model GALICS and MOMAF execution time and output files size, and run the simulation using a grid middleware: DIET. All the complexity of accessing resources, scheduling simulations and managing data is harnessed by DIET and hidden behind a web portal accessible to the users.
💡 Research Summary
The paper addresses the problem of calibrating the semi‑analytical model parameters used in the GALICS galaxy formation framework and its companion tool MOMAF, which generates mock observational catalogs. Because the model contains many physically motivated parameters—such as star‑formation efficiency, supernova feedback strength, halo recycling efficiency, cooling rates, and gas accretion prescriptions—the authors adopt an empirical approach: they sample the high‑dimensional parameter space, run a large number of full simulations, and then analyse which parameters most strongly affect observable outputs like the galaxy stellar mass function, colour–magnitude relations, and clustering statistics.
Running thousands of such simulations is computationally prohibitive on a single cluster. To overcome this, the authors design a grid‑computing environment based on the DIET (Distributed Interactive Engineering Toolbox) middleware. DIET abstracts heterogeneous resources (clusters, supercomputers, cloud instances) as services, handling resource discovery, job submission, monitoring, fault tolerance, and data movement. A web portal sits on top of DIET, allowing end‑users to specify parameter sets, launch experiments, and retrieve results without dealing with low‑level scheduling or storage issues.
A key technical contribution is the development of an empirical performance model that predicts both execution time and output file size from the chosen input parameters. The authors collected execution logs from a pilot set of runs, performed regression analysis, and built a model whose mean absolute error is below 10 % for both metrics. This model feeds the DIET scheduler, which assigns each simulation to the most suitable node—high‑intensity jobs go to machines with abundant CPU cores and memory, while lighter jobs are placed on less powerful resources. The model also drives a data‑compression strategy that reduces overall network traffic by roughly 30 %.
Experimental evaluation shows that the grid solution reduces total wall‑clock time by more than 60 % compared with a traditional single‑cluster deployment, while maintaining data integrity and reproducibility through systematic metadata registration. Sensitivity analysis, performed using multivariate regression and Sobol indices, reveals that star‑formation efficiency and feedback strength dominate the variance in the simulated observables; halo recycling efficiency has a moderate effect, and cooling parameters contribute relatively little. These findings provide concrete guidance for future tuning of GALICS/MOMAF and illustrate how empirical parameter sweeps can be made tractable with a well‑engineered grid infrastructure.
The authors conclude with several avenues for future work. First, they propose replacing the current linear regression‑based performance predictor with machine‑learning models (e.g., random forests or neural networks) to capture non‑linear interactions and improve scheduling decisions. Second, they plan to expand the grid to incorporate more geographically distributed resources, thereby increasing throughput and resilience. Third, they suggest integrating advanced sampling techniques such as Bayesian optimization or adaptive design of experiments to reduce the number of required simulations while still mapping the parameter space effectively. By combining these improvements, the methodology could become a standard tool for large‑scale cosmological semi‑analytical modeling, enabling researchers to explore complex physical parameter spaces with far less manual overhead.
Comments & Academic Discussion
Loading comments...
Leave a Comment