A PCA-Based Convolutional Network
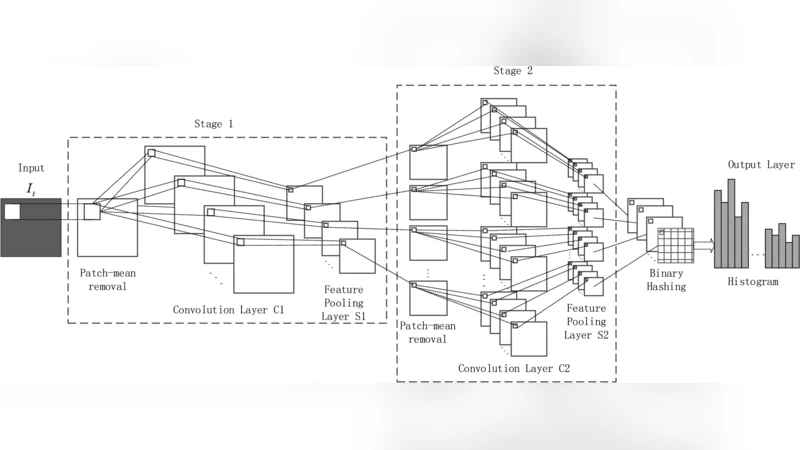
In this paper, we propose a novel unsupervised deep learning model, called PCA-based Convolutional Network (PCN). The architecture of PCN is composed of several feature extraction stages and a nonlinear output stage. Particularly, each feature extraction stage includes two layers: a convolutional layer and a feature pooling layer. In the convolutional layer, the filter banks are simply learned by PCA. In the nonlinear output stage, binary hashing is applied. For the higher convolutional layers, the filter banks are learned from the feature maps that were obtained in the previous stage. To test PCN, we conducted extensive experiments on some challenging tasks, including handwritten digits recognition, face recognition and texture classification. The results show that PCN performs competitive with or even better than state-of-the-art deep learning models. More importantly, since there is no back propagation for supervised finetuning, PCN is much more efficient than existing deep networks.
💡 Research Summary
The paper introduces the PCA‑based Convolutional Network (PCN), an unsupervised deep learning architecture that replaces the conventional trainable convolutional filters with those obtained by Principal Component Analysis (PCA). The authors retain the classic multi‑stage ConvNet pipeline—convolution, non‑linearity, and pooling—but they eliminate the need for back‑propagation by learning each layer’s filters directly from the data.
In the first feature‑extraction stage, all training images are sampled with overlapping (or non‑overlapping) patches of size k₁×k₂ at a stride of k pixels. Each patch is mean‑centered, vectorized, and concatenated across the whole dataset to form a large matrix X. After subtracting the row means, the covariance matrix X Xᵀ is eigendecomposed and the top L₁ eigenvectors are reshaped into convolutional kernels. Convolution of the original images with these kernels yields L₁ feature maps, which are then down‑sampled by average or max pooling over p×q neighborhoods.
The second stage treats the L₁ feature maps as L₁ subsets. An indexing matrix defines how subsets are combined into groups (e.g., adjacent subsets summed together). For each group, the same PCA procedure is applied: patches are extracted from the pooled maps, mean‑centered, and assembled into a matrix Y; the leading L₂ eigenvectors of Y Yᵀ become the second‑stage kernels. Convolution and pooling are repeated, producing L₁ × L₂ new maps. Additional stages can be stacked in the same fashion, each time learning filters from the pooled outputs of the previous stage.
The output stage converts the final set of feature maps into a compact representation. Each map is binarized using a Heaviside step function, and the L₂ binary bits at each pixel are interpreted as a decimal number, forming an integer‑valued image. The image is divided into B blocks (overlapping or not), and a histogram of the integer values is computed for each block. Concatenating all block histograms yields the final feature vector, which is fed to a linear Support Vector Machine for classification.
Experiments were conducted on three benchmark tasks: handwritten digit recognition (basic and full MNIST) and face recognition. For the basic MNIST subset (10 k training, 2 k validation, 50 k test), the optimal configuration used 6 filters in the first stage and 11 in the second, achieving 99.20 % accuracy—higher than PCANet‑2 (98.94 %) and ScatNet‑2 (98.73 %). On the full MNIST dataset (60 k training, 10 k test), the best setting (8 first‑stage and 10 second‑stage filters) reached 99.41 % accuracy, comparable to the best reported ConvNet and ScatNet results. Face recognition experiments similarly demonstrated competitive accuracy while requiring far less computational time because filter learning is reduced to eigen‑decomposition rather than iterative gradient descent.
The authors argue that PCN’s strengths lie in three areas: (1) elimination of supervised back‑propagation, which drastically reduces training time and removes dependence on large labeled corpora; (2) data‑driven filter construction via PCA, which captures the most significant variance of the input distribution without hand‑crafted designs; and (3) the combination of pooling and binary hashing, which controls feature dimensionality while preserving discriminative power.
Limitations are acknowledged. PCA filters are linear and may struggle with highly non‑linear patterns; performance is sensitive to the number of filters, patch size, and pooling parameters; and the current method for combining subsets (the indexing matrix) is manually designed, lacking a systematic optimization strategy. Future work could explore non‑linear extensions of PCA, automated hyper‑parameter search, and deeper stacking of stages.
Overall, PCN demonstrates that a simple, unsupervised, PCA‑driven convolutional architecture can achieve state‑of‑the‑art performance on classic vision benchmarks with significantly lower computational overhead, offering a compelling alternative to fully supervised deep networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment