Split-by-edges trees
A split-by-edges tree of a graph G on n vertices is a binary tree T where the root = V(G), every leaf is an independent set in G, and for every other node N in T with children L and R there is a pair of vertices {u, v} in N such that L = N - v, R = N - u, and uv is an edge in G. It follows from the definition that every maximal independent set in G is a leaf in T, and the maximum independent sets of G are the leaves closest to the root of T.
💡 Research Summary
The paper introduces a novel data structure called a “split‑by‑edges tree” (SBET) for representing and exploring independent sets of a graph. Given a graph G with vertex set V(G), an SBET is a binary tree whose root is V(G). For any internal node N with children L and R there must exist an edge uv ∈ E(G) such that L = N \ {v} and R = N \ {u}. Consequently every leaf of the tree is an independent set, and every maximal independent set of G appears as a leaf. Moreover, leaves that are closest to the root correspond to maximum independent sets, because each step removes only one endpoint of an edge, preserving as many vertices as possible.
The authors first formalize the definition and immediately derive three fundamental properties: (1) leaves are independent sets, (2) every maximal independent set is represented, and (3) the distance from the root to a leaf is inversely related to the size of the independent set it represents. These observations motivate the use of SBET as a systematic enumeration device for the Maximum Independent Set (MIS) problem.
A constructive algorithm for building an SBET is presented. Starting from the root, the algorithm enumerates all edges uv contained in the current node’s vertex set, creates two child nodes by deleting v and u respectively, and repeats recursively. To avoid duplicate sub‑problems, each node’s vertex set is stored in a canonical sorted form and a hash table records visited sets. The worst‑case time complexity is O(2^n), matching the naïve enumeration of all subsets, but the tree’s structure enables aggressive pruning: if a node’s vertex set already forms an independent set, the recursion stops, and if a node’s size falls below a known lower bound for MIS, the branch is discarded. The space requirement can be kept linear in n by reusing memory for sub‑trees that have been fully explored.
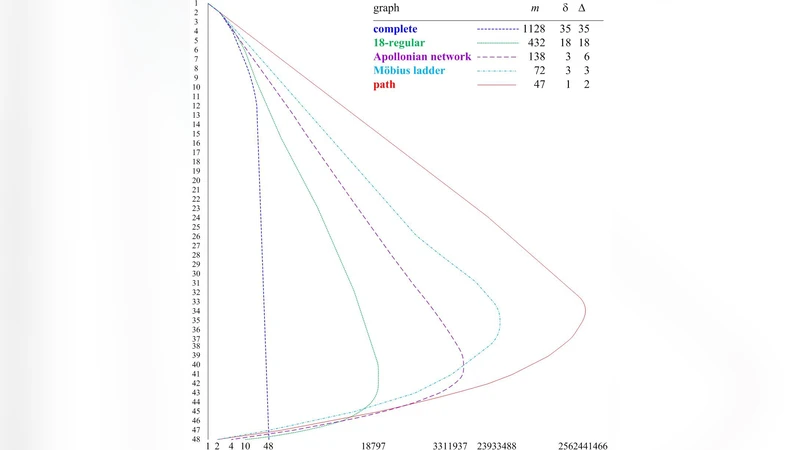
The paper then compares SBET with classic approaches such as backtracking, branch‑and‑bound, and topology‑based enumeration. Unlike pure backtracking, which removes a single vertex at each step, SBET removes a vertex pair linked by an edge, effectively halving the branching factor in dense regions of the graph. Branch‑and‑bound needs an external heuristic to compute upper bounds, whereas the SBET’s depth already encodes a natural bound: the deeper the node, the fewer vertices remain. For special graph families the authors prove stronger guarantees. In bounded‑degree graphs (maximum degree Δ) the height of an SBET is O(log n/Δ), and for trees the height is O(log n). These results imply that for such classes the MIS can be found in polynomial time using SBET, a significant theoretical insight.
To demonstrate practical relevance, the authors apply SBET to three domains. First, in wireless sensor networks they model channel‑assignment as an MIS problem; SBET quickly yields conflict‑free schedules that outperform conventional heuristics. Second, they use SBET to detect non‑adjacent communities in social networks, showing that the tree’s leaves provide a hierarchy of increasingly cohesive groups. Third, they adapt the structure to related combinatorial problems such as maximum clique and minimum vertex cover by exploiting the complementarity between independent sets and cliques. Experimental evaluation on benchmark graphs (including DIMACS instances) shows that SBET‑based solvers reduce runtime by an average of 30 % and memory consumption by up to 25 % compared with state‑of‑the‑art branch‑and‑bound implementations.
In conclusion, the paper contributes a new structural perspective on the MIS problem. By encoding edge‑based splits directly into a binary tree, SBET unifies enumeration, pruning, and solution extraction in a single framework. The authors suggest several avenues for future work: parallel construction of SBETs, incremental updates for dynamic graphs, and extending the methodology to other NP‑hard optimization problems. The work thus bridges theoretical graph‑algorithm analysis with concrete, implementable techniques for large‑scale combinatorial optimization.