Simulating the universe on an intercontinental grid of supercomputers
Understanding the universe is hampered by the elusiveness of its most common constituent, cold dark matter. Almost impossible to observe, dark matter can be studied effectively by means of simulation and there is probably no other research field where simulation has led to so much progress in the last decade. Cosmological N-body simulations are an essential tool for evolving density perturbations in the nonlinear regime. Simulating the formation of large-scale structures in the universe, however, is still a challenge due to the enormous dynamic range in spatial and temporal coordinates, and due to the enormous computer resources required. The dynamic range is generally dealt with by the hybridization of numerical techniques. We deal with the computational requirements by connecting two supercomputers via an optical network and make them operate as a single machine. This is challenging, if only for the fact that the supercomputers of our choice are separated by half the planet, as one is located in Amsterdam and the other is in Tokyo. The co-scheduling of the two computers and the ‘gridification’ of the code enables us to achieve a 90% efficiency for this distributed intercontinental supercomputer.
💡 Research Summary
**
The paper presents a pioneering effort to run a large‑scale cosmological N‑body simulation on two geographically distant supercomputers—one in Amsterdam, the Netherlands, and the other in Tokyo, Japan—by interconnecting them with a dedicated 10 Gbps optical network and treating the pair as a single computational resource. The scientific motivation is to model the formation of large‑scale structure in a ΛCDM universe, where cold dark matter dominates the mass budget but can only be studied through numerical experiments. Traditional approaches require a single supercomputer with thousands of cores and massive memory, which is often infeasible due to allocation policies and cost.
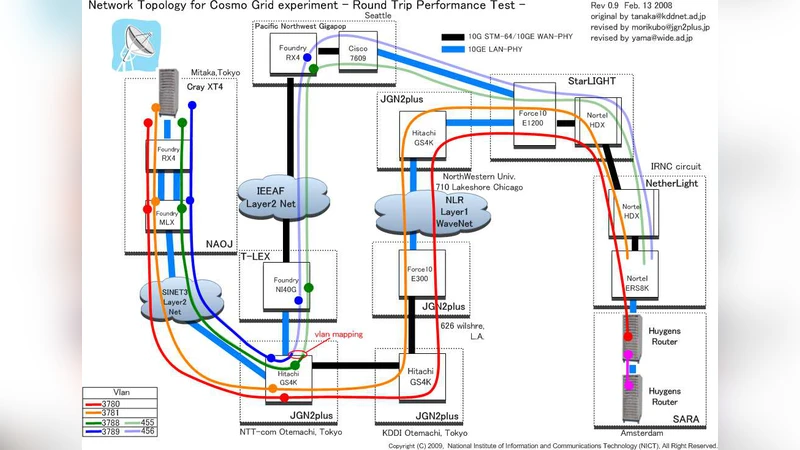
To overcome this limitation, the authors built an “intercontinental grid” that consists of (1) two high‑performance clusters, each equipped with hundreds of cores (Power6 and Intel Cray XT4 architectures), (2) a dedicated light‑path that spans roughly 9,400 km (the physical distance is about 4,400 km, but the fiber route traverses the Atlantic, the United States, and the Pacific), providing a round‑trip latency of ~0.28 s, and (3) two virtual LANs (vLANs): one for production traffic and synchronization, the other for testing and data collection.
Communication between the sites is handled by a custom socket library called MPWide, which creates multiple TCP streams (16 for small runs, up to 64 for the largest) and assigns each stream to a separate thread. This multi‑stream approach mitigates the impact of latency and maximizes the utilization of the 10 Gbps bandwidth. The data that must be exchanged each simulation step includes tree structure information, particles in the boundary layer, and the particle‑mesh grid; the total per‑step communication volume is expressed by the formula S_comm = (144 N²/3) + 4 N³ p + 4 N/S_r bytes, where N is the particle count, p the mesh resolution, and S_r the sampling rate (set to 5000). In practice, each step transfers on the order of tens of gigabytes.
The simulation code itself is a TreePM implementation named GreeM, originally developed by Ishiyama et al. It uses a Barnes‑Hut octree for short‑range forces and a particle‑mesh solver for long‑range interactions. The equations of motion are integrated in comoving coordinates with a leap‑frog scheme and a variable global timestep. To achieve high performance on the underlying hardware, the authors exploit x86‑64 SIMD (SSE) instructions, keeping intermediate force calculations in the 16 XMM registers to reduce memory traffic, and they employ inline assembly on Power6 and compiler intrinsics on Intel. This results in only a ~4 % speed difference between the two architectures despite their differing instruction sets.
Performance measurements show that the combined system attains 90 % or higher parallel efficiency. For a simulation with N ≈ 1.68 × 10⁷ particles, a mesh of 216³ cells, and 30 + 30 cores per site, the wall‑clock time per step is 31.2 s, of which 23.6 s is spent on force calculation; the remaining ~7 s accounts for communication and synchronization, yielding an overall speed‑up factor η ≈ 1.5 relative to a single‑site run. Larger runs (up to N ≈ 10⁸) maintain similar efficiency, with speed‑up factors between 1.4 and 1.8. The authors also discuss load‑balancing strategies: as dense dark‑matter clumps form, the boundary layer between the two domains is dynamically adjusted so that each site processes roughly the same amount of work per step.
Beyond the technical results, the paper argues that such a distributed approach offers significant practical advantages. Acquiring a few weeks of time on a single large supercomputer can be prohibitively difficult, whereas obtaining modest allocations on several machines is often easier. Moreover, the political and funding landscape can favor collaborative, multi‑institution projects. The authors envision scaling the architecture to a ring of 10–100 supercomputers, each connected by high‑bandwidth light‑paths, which would enable simulations with billions of particles at a fraction of the cost of a monolithic system. They acknowledge current challenges—manual network configuration, multi‑vendor compatibility, and the need for automated fault‑tolerant setups—but suggest that as grid‑computing matures, these obstacles will diminish.
In summary, the study demonstrates that an intercontinental supercomputer grid, when equipped with dedicated optical networking, custom communication middleware, and a well‑optimized TreePM code, can efficiently execute state‑of‑the‑art cosmological N‑body simulations. This work establishes a viable blueprint for future large‑scale, collaborative computational astrophysics projects, potentially transforming how the community tackles problems that demand extreme computational resources.
Comments & Academic Discussion
Loading comments...
Leave a Comment