SPECI, a simulation tool exploring cloud-scale data centres
There is a rapid increase in the size of data centres (DCs) used to provide cloud computing services. It is commonly agreed that not all properties in the middleware that manages DCs will scale linearly with the number of components. Further, “normal failure” complicates the assessment of the per-formance of a DC. However, unlike in other engineering domains, there are no well established tools that allow the prediction of the performance and behav-iour of future generations of DCs. SPECI, Simulation Program for Elastic Cloud Infrastructures, is a simulation tool which allows exploration of aspects of scaling as well as performance properties of future DCs.
💡 Research Summary
The paper introduces SPECI (Simulation Program for Elastic Cloud Infrastructures), a dedicated simulation framework designed to evaluate the scalability and performance of future‑generation cloud data centres. As modern data centres grow from thousands to hundreds of thousands of servers, the assumption of linear scaling for middleware and infrastructure components no longer holds. Moreover, the phenomenon of “normal failure” – the continual occurrence of component faults, network delays, and power irregularities – makes it difficult to assess system behaviour using traditional deterministic models. SPECI addresses these challenges by providing a modular, event‑driven simulation environment that explicitly models both the physical resources (servers, switches, storage units, power supplies) and the logical constructs (virtual machines, containers, orchestration services) that compose a cloud data centre.
Key architectural features include: (1) Object‑oriented representation of each data‑centre element with configurable performance parameters (CPU, memory, bandwidth, latency, failure rates); (2) Probabilistic failure injection that captures normal‑failure dynamics, allowing the simulation to reproduce realistic fault patterns and recovery processes; (3) Support for elastic behaviours such as dynamic resource provisioning, auto‑scaling policies, and workload migration, enabling the study of how a system adapts to fluctuating demand. The simulation workflow proceeds in three stages: (a) topology and workload definition, (b) time‑ordered event scheduling (including request arrivals, component failures, repairs, and scaling actions), and (c) metric collection and analysis (response time, throughput, resource utilisation, mean time between failures, mean time to repair, etc.).
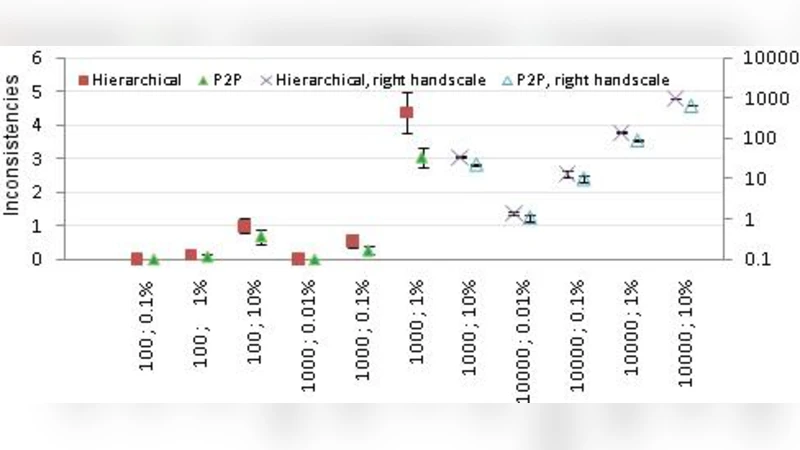
Experimental evaluation focuses on two dimensions: (i) scaling the number of components by factors of ten and one hundred, and (ii) varying the probability of normal failures. Results demonstrate that beyond a certain size threshold, performance metrics deviate sharply from linear expectations. Network bandwidth saturation, scheduler bottlenecks, and delayed fault recovery combine to create a “performance cliff” where response times increase dramatically. When normal‑failure models are activated, the simulated mean time between failures (MTBF) and mean time to repair (MTTR) closely match measurements taken from operational data centres, confirming the fidelity of the fault model.
The authors highlight several strengths of SPECI: it provides a quantitative platform for exploring complex, large‑scale data‑centre designs; it incorporates realistic failure behaviour often omitted in other tools; and it allows rapid prototyping of scaling policies and resource‑management algorithms. Limitations are also acknowledged. The current implementation focuses primarily on CPU and memory utilisation, leaving storage I/O, GPU‑accelerated workloads, and edge‑computing scenarios under‑represented. Moreover, the validation experiments rely on a static leaf‑spine topology, which may not capture the nuances of hyper‑converged or multi‑cloud architectures that are increasingly common.
Future work outlined in the paper includes extending the model to cover a broader spectrum of workloads (big‑data analytics, AI training, high‑throughput I/O), integrating real‑time monitoring data to create a hybrid simulation‑prediction loop, automating parameter tuning for optimisation, and supporting more diverse topologies such as distributed edge nodes and hybrid cloud environments. By addressing these extensions, SPECI aims to become an indispensable decision‑support tool for architects and operators seeking to design resilient, cost‑effective, and performance‑predictable cloud data centres at massive scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment