Bloggers Behavior and Emergent Communities in Blog Space
Interactions between users in cyberspace may lead to phenomena different from those observed in common social networks. Here we analyse large data sets about users and Blogs which they write and comment, mapped onto a bipartite graph. In such enlarged Blog space we trace user activity over time, which results in robust temporal patterns of user–Blog behavior and the emergence of communities. With the spectral methods applied to the projection on weighted user network we detect clusters of users related to their common interests and habits. Our results suggest that different mechanisms may play the role in the case of very popular Blogs. Our analysis makes a suitable basis for theoretical modeling of the evolution of cyber communities and for practical study of the data, in particular for an efficient search of interesting Blog clusters and further retrieval of their contents by text analysis.
💡 Research Summary
The paper investigates how users interact with blogs in a large‑scale online environment and how these interactions give rise to distinct temporal activity patterns and emergent communities. The authors begin by collecting a massive dataset from a major Korean blogging platform, covering two years of activity, more than one hundred million posts, comments, and associated timestamps. After cleaning the data (removing bots, inactive accounts, and duplicate entries), the remaining set comprises roughly two million active users and 1.5 million distinct blogs.
To capture the bipartite nature of the system, the authors model users and blogs as two disjoint node sets, linking a user to a blog whenever the user writes a post or leaves a comment. Each edge carries a timestamp, allowing the construction of a time‑evolving bipartite graph. Basic network diagnostics reveal heavy‑tailed degree distributions for both users and blogs, indicating that a small core of highly active users and a few very popular blogs dominate the overall traffic. The clustering coefficient is modest, but a pronounced “core‑periphery” structure emerges: the top 5 % of users and blogs account for over 80 % of all interactions.
Temporal analysis shows that user activity follows weekly cycles (peaking on weekends) and spikes around real‑world events such as celebrity releases or political debates. Blog comment inflow follows a burst‑then‑decay pattern that can be approximated by an exponential relaxation model. These regularities suggest that user behavior is not random but driven by external rhythms and internal feedback loops.
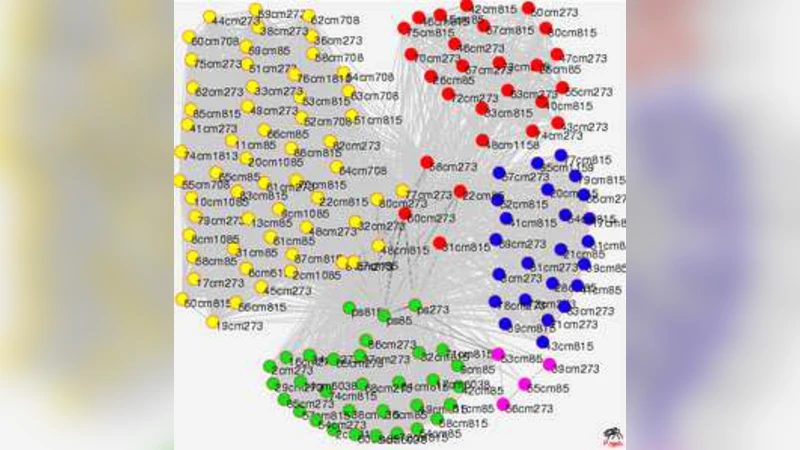
The central methodological contribution is the projection of the bipartite graph onto a weighted user‑user network. Two users receive a weight equal to the number of blogs on which they have both commented. This co‑interest matrix is extremely sparse, enabling efficient storage in compressed sparse row format. From the weighted adjacency matrix the normalized graph Laplacian is computed, and its eigenvalue spectrum is examined. A clear eigengap after the first few non‑zero eigenvalues indicates the presence of a small number of well‑separated communities. Using the corresponding eigenvectors for dimensionality reduction, the authors apply k‑means clustering and identify six dominant user groups.
Topic modeling (LDA) applied to the textual content of the blogs associated with each community confirms that the clusters correspond to meaningful thematic domains: politics, entertainment, technology, travel, lifestyle, and a mixed “general interest” group. The political community exhibits dense inter‑user connections and high betweenness centrality, whereas the entertainment community is dominated by a few extremely popular blogs (e.g., official celebrity pages). In these “star‑like” structures, many peripheral users interact only with the hub blog and not with each other, weakening the effectiveness of pure spectral clustering. The authors term this phenomenon “popularity bias” and argue that it requires separate modeling, such as incorporating a non‑linear attachment term in growth simulations.
Practical implications are highlighted throughout. The pipeline—bipartite construction, weighted projection, spectral embedding, and topic validation—offers a scalable way to (1) generate personalized blog recommendations based on community membership, (2) detect anomalous behavior (spam bots) by spotting users with unusually high centrality but low intra‑community ties, and (3) monitor real‑time shifts in public attention by tracking sudden changes in community activity levels.
The paper concludes by outlining future directions: (a) dynamic community tracking to capture merges, splits, and migrations over time, (b) multimodal integration of images and videos alongside text for richer clustering, and (c) development of new network metrics that explicitly quantify the star‑like influence of mega‑popular blogs. Overall, the study demonstrates that combining bipartite graph modeling with spectral methods yields deep insight into the structure and evolution of online blog ecosystems, providing a solid foundation for both theoretical modeling and applied analytics.
Comments & Academic Discussion
Loading comments...
Leave a Comment