Weight Optimization for Consensus Algorithms with Correlated Switching Topology
We design the weights in consensus algorithms with spatially correlated random topologies. These arise with: 1) networks with spatially correlated random link failures and 2) networks with randomized averaging protocols. We show that the weight optim…
Authors: Dusan Jakovetic, Joao Xavier, Jose M. F. Moura
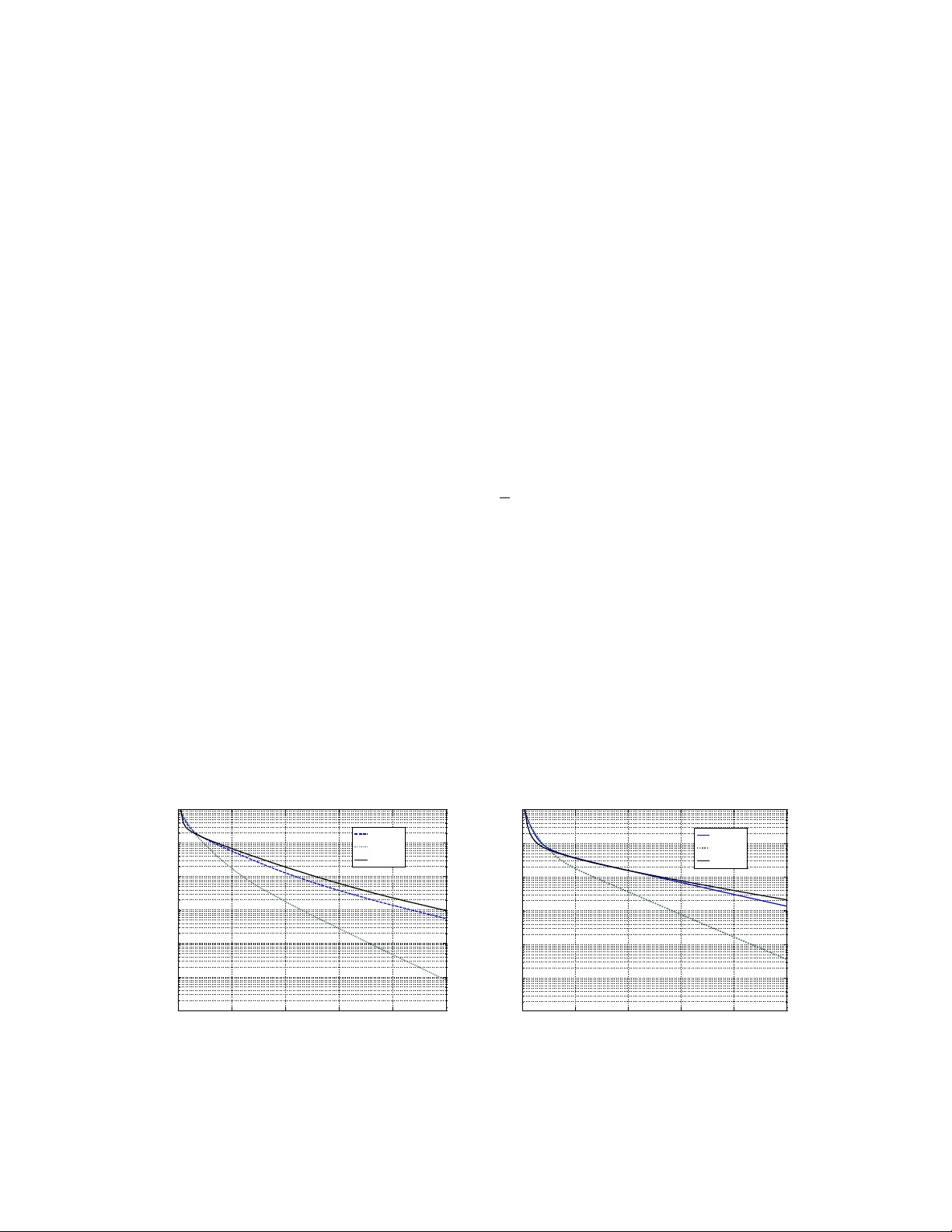
W eight Optimization for Consensus Algorithms with Correlated Switching T opology Du ˘ san Jako veti ´ c, Jo ˜ ao Xavier , and Jos ´ e M. F . Moura ∗ Abstract W e design the weights in consensus algorithms with spatially correlated random topologies. These arise with: 1) networks with spatially correlated random link failures and 2) networks with randomized av eraging protocols. W e sho w that the weight optimization problem is con vex for both symmetric and asymmetric random graphs. W ith symmetric random networks, we choose the consensus mean squared error (MSE) con ver gence rate as optimization criterion and explicitly express this rate as a function of the link formation probabilities, the link formation spatial correlations, and the consensus weights. W e prov e that the MSE con vergence rate is a con vex, nonsmooth function of the weights, enabling global optimization of the weights for arbitrary link formation probabilities and link correlation structures. W e extend our results to the case of asymmetric random links. W e adopt as optimization criterion the mean squared deviation (MSdev) of the nodes’ states from the current average state. W e prov e that MSdev is a con ve x function of the weights. Simulations show that significant performance gain is achie ved with our weight design method when compared with methods av ailable in the literature. K eywords: Consensus, weight optimization, correlated link failures, unconstrained optimization, sensor networks, switching topology , broadcast gossip. The first and second authors are with the Instituto de Sistemas e Rob ´ otica (ISR), Instituto Superior T ´ ecnico (IST), 1049-001 Lisboa, Portugal. The first and third authors are with the Department of Electrical and Computer Engineering, Carnegie Mellon Univ ersity , Pittsburgh, P A 15213, USA (e-mail: [djakov etic,jxavier]@isr .ist.utl.pt, moura@ece.cmu.edu, ph: (412)268-6341, fax: (412)268-3890.) W ork partially supported by NSF under grant # CNS-0428404, by the Of fice of Naval Research under MURI N000140710747, and by the Carnegie Mellon | Portugal Program under a grant of the Funda c ˜ ao de Ci ˆ encia e T ecnologia (FCT) from Portugal. Du ˘ san Jakov etic holds a fellowship from FCT . 2 I . I N T RO D U C T I O N This paper finds the optimal weights for the consensus algorithm in correlated random networks. Consensus is an iterativ e distributed algorithm that computes the global av erage of data distributed among a network of agents using only local communications. Consensus has rene wed interest in distrib uted algorithms ([1], [2]), arising in many dif ferent areas from distributed data fusion ([3], [4], [5], [6], [7]) to coordination of mobile autonomous agents ([8], [9]). A recent surve y is [10]. This paper studies consensus algorithms in networks where the links (being online or of f line) are random. W e consider two scenarios: 1) the network is random, because links in the network may fail at random times; 2) the network protocol is randomized, i.e., the link states along time are controlled by a randomized protocol (e.g., standard gossip algorithm [11], broadcast gossip algorithm [12]). In both cases, we model the links as Bernoulli random variables. Each link has some formation probability , i.e., probability of being activ e, equal to P ij . Different links may be correlated at the same time, which can be expected in real applications. For example, in wireless sensor networks (WSNs) links can be spatially correlated due to interference among close links or electromagnetic shadows that may af fect several nearby sensors. References on consensus under time varying or random topology are ([13], [10], [14]) and ([15], [16], [17], [18], [12]), among others, respecti v ely . Most of the pre vious work is focussed on pro viding con v ergence conditions and/or characterizing the conv er gence rate under different assumptions on the network randomness ([17], [16], [18]). For example, references [16] and [19] study consensus algorithm with spatially and temporally independent link failures. They sho w that a necessary and sufficient condition for mean squared and almost sure con ver gence is for the communication graph to be connected on average. W e consider here the weight optimization problem: ho w to assign the weights W ij with which the nodes mix their states across the network, so that the con v ergence tow ards consensus is the fastest possible. This problem has not been solved (with full generality) for consensus in random topologies. W e study this problem for netw orks with symmetric and asymmetric random links separately , since the properties of the corresponding algorithm are dif ferent. For symmetric links (and connected netw ork topology on av erage), the consensus algorithm con ver ges to the average of the initial nodes’ states almost surely . For asymmetric random links, all the nodes asymptotically reach agreement, but they only agree to a random v ariable in the neighborhood of the true initial average. W e refer to our weight solution as probability-based weights (PBW). PBW are simple and suitable for distributed implementation: we assume at each iteration that the weight of link ( i, j ) is W ij (to be November 6, 2018 DRAFT 3 optimized), when the link is aliv e, or 0, otherwise. Self-weights are adapted such that the row-sums of the weight matrix at each iteration are one. This is suitable for distributed implementation. Each node updates readily after receiving messages from its current neighbors. No information about the number of nodes in the network or the neighbor’ s current degrees is needed. Hence, no additional online communication is required for computing weights, in contrast, for instance, to the case of the Metropolis weights (MW) [14]. Our weight design method assumes that the link formation probabilities and their spatial correlations are known. With randomized protocols, the link formation probabilities and their correlations are induced by the protocol itself, and thus are known. F or networks with random link failures, the link formation probabilities relate to the signal to noise ratio at the receiver and can be computed. In [20], the formation probabilities are designed in the presence of link communication costs and an overall network communi- cation cost budget. When the WSN infrastructure is kno wn, it is possible to estimate the link formation pr obabilities by measuring the reception rate of a link computed as the ratio between the number of recei ved and the total number of sent packets. Another possibility is to estimate the link formation probabilities based on the receiv ed signal strength. Link formation correlations can also be estimated on actual WSNs, [21]. If there is no training period to characterize quantitati vely the links on an actual WSN, we can still model the probabilities and the correlations as a function of the transmitted po wer and the inter-sensor distances. Moreover , sev eral empirical studies ([21], [22] and references therein) on the quantitative properties of wireless communication in sensor networks hav e been done that provide models for pack et deliv ery performance in WSNs. Summary of the paper . Section II lists our contributions, relate them with the existing literature, and introduces notation used in the paper . Section III describes our model of random networks and the consensus algorithm. Sections IV and V study the weight optimization for symmetric random graphs and asymmetric random graphs, respecti vely . Section VI demonstrates the effecti veness of our approach with simulations. Finally , section VII concludes the paper . W e derive the proofs of some results in the Appendices A through C. I I . C O N T R I B U T I O N , R E L A T E D W O R K , A N D N O T A T I O N Contribution. Building our results on the previous extensi v e studies of con ver gence conditions and rates for consensus algorithm (e.g.,[12], [15], [20]), we address the problem of weights optimization in consensus algorithms with correlated random topologies. Our method is applicable to: 1) networks with correlated random link failures (see, e.g., [20] and 2) networks with randomized algorithms (see, e.g, [11], [12]). W e first address the weight design problem for symmetric random links, and then extend November 6, 2018 DRAFT 4 the results to asymmetric random links. W ith symmetric random links, we use the mean squared consensus conv er gence rate φ ( W ) as the optimization criterion. W e explicitly express the rate φ ( W ) as a function of the link formation prob- abilities, their correlations, and the weights. W e prov e that φ ( W ) is a con ve x, nonsmooth function of the weights. This enables global optimization of the weights for arbitrary link formation probabilities and and arbitrary link correlation structures. W e solve numerically the resulting optimization problem by subgradient algorithm, showing also that the optimization computational cost grows tolerably with the network size. W e provide insights into weight design with a simple example of complete random network that admits closed form solution for the optimal weights and con ver gence rate and show how the optimal weights depend on the number of nodes, the link formation probabilities, and their correlations. W e extend our results to the case of asymmetric random links, adopting as an optimization criterion the mean squared deviation (from the current av erage state) rate ψ ( W ) , and show that ψ ( W ) is a conv e x function of the weights. W e provide comprehensi ve simulation experiments to demonstrate the effecti v eness of our approach. W e provide two different models of random networks with correlated link failures; in addition, we study the broadcast gossip algorithm [12], as an example of randomized protocol with asymmetric links. In all cases, simulations confirm that our method shows significant gain compared to the methods av ailable in the literature. Also, we show that the g ain increases with the network size. Related work. W eight optimization for consensus with switching topologies has not receiv ed much attention in the literature. Reference [20] studies the tradeoff between the con ver gence rate and the amount of communication that takes place in the network. This reference is mainly concerned with the design of the network topology , i.e., the design of the probabilities of reliable communication { P ij } and the weight α (assuming all nonzero weights are equal), assuming a communication cost C ij per link and an overall network communication budget. Reference [12] proposes the broadcast gossip algorithm, where at each time step, a single node, selected at random, broadcasts unidirectionally its state to all the neighbors within its wireless range. W e detail the broadcast gossip in subsection VI-B. This reference optimizes the weight for the broadcast gossip algorithm assuming equal weights for all links. The problem of optimizing the weights for consensus under a random topology , when the weights for dif ferent links may be different, has not receiv ed much attention in the literature. Authors hav e proposed weight choices for random or time-varying networks [23], [14], but no claims to optimality are made. Reference [14] proposes the Metropolis weights (MW), based on the Metropolis-Hastings algorithm for simulating a Markov chain with uniform equilibrium distribution [24]. The weights choice in [23] is November 6, 2018 DRAFT 5 based on the fastest mixing Marko v chain problem studied in [25] and uses the information about the underlying supergraph. W e refer to this weight choice as the supergraph based weights (SGBW). Notation. V ectors are denoted by a lo wer case letter (e.g., x ) and it is understood from the context if x denotes a deterministic or random vector . Symbol R N is the N -dimensional Euclidean space. Inequality x ≤ y is understood element wise, i.e., it is equiv alent to x i ≤ y i , for all i . Constant matrices are denoted by capital letters (e.g., X ) and random matrices are denoted by calligraphic letters (e.g., X ). A sequence of random matrices is denoted by {X ( k ) } ∞ k =0 and the random matrix inde x ed by k is denoted X ( k ) . If the distribution of X ( k ) is the same for any k , we shorten the notation X ( k ) to X when the time instant k is not of interest. Symbol R N × M denotes the set of N × M real v alued matrices and S N denotes the set of symmetric real valued N × N matrices. The i -th column of a matrix X is denoted by X i . Matrix entries are denoted by X ij . Quantities X ⊗ Y , X Y , and X ⊕ Y denote the Kronecker product, the Hadamard product, and the direct sum of the matrices X and Y , respectively . Inequality X Y ( X Y ) means that the matrix X − Y is positi ve (ne gati ve) semidefinite. Inequality X ≥ Y ( X ≤ Y ) is understood entry wise, i.e., it is equiv alent to X ij ≥ Y ij , for all i , j . Quantities k X k , λ max ( X ) , and r ( X ) denote the matrix 2-norm, the maximal eigen v alue, and the spectral radius of X , respectiv ely . The identity matrix is I . Gi v en a matrix A , V ec ( A ) is the column vector that stacks the columns of A . For gi ven scalars x 1 , ..., x N , diag ( x 1 , ..., x N ) denotes the diagonal N × N matrix with the i -th diagonal entry equal to x i . Similarly , diag( x ) is the diagonal matrix whose diagonal entries are the elements of x . The matrix diag ( X ) is a diagonal matrix with the diagonal equal to the diagonal of X . The N -dimensional column vector of ones is denoted with 1 . Symbol J = 1 N 11 T . The i -th canonical unit vector , i.e., the i -th column of I , is denoted by e i . Symbol | S | denotes the cardinality of a set S . I I I . P RO B L E M M O D E L This section introduces the random network model that we apply to networks with link failures and to networks with randomized algorithms. It also introduces the consensus algorithm and the corresponding weight rule assumed in this paper . A. Random network model: symmetric and asymmetric random links W e consider random networks − networks with random links or with a random protocol. Random links arise because of packet loss or drop, or when a sensor is acti v ated from sleep mode at a random time. Randomized protocols like standard pairwise gossip [11] or broadcast gossip [12] acti vate links randomly . This section describes the network model that applies to both problems. W e assume that the links are up November 6, 2018 DRAFT 6 or down (link failures) or selected to use (randomized gossip) according to spatially correlated Bernoulli random variables. T o be specific, the network is modeled by a graph G = ( V , E ) , where the set of nodes V has cardinality | V | = N and the set of directed edges E , with | E | = 2 M , collects all possible ordered node pairs that can communicate, i.e., all realizable links. For example, with geometric graphs, realizable links connect nodes within their communication radius. The graph G is called supergraph, e.g., [20]. The directed edge ( i, j ) ∈ E if node j can transmit to node i . The supergraph G is assumed to be connected and without loops. For the fully connected supergraph, the number of directed edges (arro ws) 2 M is equal to N ( N − 1) . W e are interested in sparse supergraphs, i.e., the case when M 1 2 N ( N − 1) . Associated with the graph G is its N × N adjacency matrix A : A ij = 1 if ( i, j ) ∈ E 0 otherwise The in-neighborhood set Ω i (nodes that can transmit to node i ) and the in-de gree d i of a node i are Ω i = { j : ( i, j ) ∈ E } d i = | Ω i | . W e model the connectivity of a random WSN at time step k by a (possibly) directed random graph G ( k ) = ( V , E ( k )) . The random edge set is E ( k ) = { ( i, j ) ∈ E : ( i, j ) is online at time step k } , with E ( k ) ⊆ E . The random adjacency matrix associated to G ( k ) is denoted by A ( k ) and the random in-neighborhood for sensor i by Ω i ( k ) . W e assume that link failures are temporally independent and spatially corr elated . That is, we assume that the random matrices A ( k ) , k = 0 , 1 , 2 , ... are independent identically distributed. The state of the link ( i, j ) at a time step k is a Bernoulli random variable, with mean P ij , i.e., P ij is the formation probability of link ( i, j ) . At time step k , different edges ( i, j ) and ( p.q ) may be correlated, i.e., the entries A ij ( k ) and A pq ( k ) may be correlated. For the link r , by which node j transmits to node i , and for the link s , by which node q transmits to node p , the corresponding cross-v ariance is [ R q ] rs = E [ A ij A pq ] − P ij P pq . November 6, 2018 DRAFT 7 T ime correlation, as spatial correlation, arises naturally in many scenarios, such as when nodes awak e from the sleep schedule. Howe ver , it requires approach dif ferent than the one we pursue in this paper [19]. W e plan to address the weight optimization with temporally correlated links in our future w ork. B. Consensus algorithm Let x i (0) represent some scalar measurement or initial data available at sensor i , i = 1 , ..., N . Denote by x avg the average: x avg = 1 N N X i =1 x i (0) The consensus algorithm computes x avg iterati vely at each sensor i by the distributed weighted av erage: x i ( k + 1) = W ii ( k ) x i ( k ) + X j ∈ Ω i ( k ) W ij ( k ) x j ( k ) (1) W e assume that the random weights W ij ( k ) at iteration k are giv en by: W ij ( k ) = W ij if j ∈ Ω i ( k ) 1 − P m ∈ Ω i ( k ) W im ( k ) if i = m 0 otherwise (2) In (2), the quantities W ij are non random and will be the variables to be optimized in our work. W e also take W ii = 0 , for all i . By (2), when the link is active, the weight is W ij , and when not acti ve it is zero. Note that W ij are non zero only for edges ( i, j ) in the supergraph G . If an edge ( i, j ) is not in the supergraph the corresponding W ij = 0 and W ij ( k ) ≡ 0 . W e write the consensus algorithm in compact form. Let x ( k ) = ( x 1 ( k ) x 2 ( k ) ... x N ( k )) T , W = [ W ij ] , W ( k ) = [ W ij ( k )] . The random weight matrix W ( k ) can be written in compact form as W ( k ) = W A ( k ) − diag ( W A ( k )) + I (3) and the consensus algorithm is simply stated with x ( k = 0) = x (0) as x ( k + 1) = W ( k ) x ( k ) , k ≥ 0 (4) T o implement the update rule, nodes need to know their random in-neighborhood Ω i ( k ) at e very iteration. In practice, nodes determine Ω i ( k ) based on who they receiv e messages from at iteration k . It is well known [12], [15] that, when the random matrix W ( k ) is symmetric, the consensus algorithm is av erage preserving, i.e., the sum of the states x i ( k ) , and so the average state over time, does not change, November 6, 2018 DRAFT 8 e ven in the presence of random links. In that case the consensus algorithm con v erges almost surely to the true a verage x avg . When the matrix W ( k ) is not symmetric, the a verage state is not preserved in time, and the state of each node con ver ges to the same random variable with bounded mean squared error from x avg [12]. For certain applications, where high precision on computing the average x avg is required, av erage preserving, and thus a symmetric matrix W ( k ) is desirable. In practice, a symmetric matrix W ( k ) can be established by protocol design ev en if the underlying physical channels are asymmetric. This can be realized by ignoring unidirectional communication channels. This can be done, for instance, with a double acknowledgement protocol. In this scenario, ef fecti vely , the consensus algorithm sees the underlying random network as a symmetric network, and this scenario falls into the framework of our studies of symmetric links (section IV). When the physical communication channels are asymmetric, and the error on the asymptotic consensus limit c is tolerable, consensus with an asymmetric weight matrix W ( k ) can be used. This type of algorithm is easier to implement, since there is no need for acknowledgement protocols. An example of such a protocol is the broadcast gossip algorithm proposed in [12]. Section V studies this type of algorithms. Set of possible weight choices: symmetric network. With symmetric random links, we will al ways assume W ij = W j i . By doing this we easily achiev e the desirable property that W ( k ) is symmetric. The set of all possible weight choices for symmetric random links S W becomes: S W = W ∈ R N × N : W ij = W j i , W ij = 0 , if ( i, j ) / ∈ E , W ii = 0 , ∀ i, (5) Set of possible weight choices: asymmetric network. W ith asymmetric random links, there is no good reason to require that W ij = W j i , and thus we drop the restriction W ij = W j i . The set of possible weight choices in this case becomes: S asym W = W ∈ R N × N : W ij = 0 , if ( i, j ) / ∈ E , W ii = 0 , ∀ i, (6) Depending whether the random network is symmetric or asymmetric, there will be two error quantities that will play a role. These will be discussed in detail in sections IV and V , respectiv ely . W e introduce them here briefly , for reference. Mean square error (MSE): symmetric network. Define the consensus error vector e ( k ) and the error cov ariance matrix Σ( k ) : e ( k ) = x ( k ) − x avg 1 (7) Σ( k ) = E e ( k ) e ( k ) T . (8) November 6, 2018 DRAFT 9 The mean squared consensus error MSE is giv en by: MSE( k ) = N X i =1 E h x i ( k ) − x avg 2 i = E e ( k ) T e ( k ) = tr Σ( k ) (9) Mean square deviation (MSdev): asymmetric network. As explained, when the random links are asymmetric (i.e., when W ( k ) is not symmetric), and if the underlying supergraph is strongly connected, then the states of all nodes conv er ge to a common v alue c that is in general a random v ariable that depends on the sequence of netw ork realizations and on the initial state x (0) (see [15], [12]). In order to have c = x avg , almost surely , an additional condition must be satisfied: 1 T W ( k ) = 1 T , a . s . (10) See [15], [12] for the details. W e remark that (10) is a crucial assumption in the deriv ation of the MSE decay (25). Theoretically , equation (23) is still valid if the condition W ( k ) = W ( k ) T is relaxed to 1 T W ( k ) = 1 T . While this condition is trivially satisfied for symmetric links and symmetric weights W ij = W j i , it is very dif ficult to realize (10) in practice when the random links are asymmetric. So, in our work, we do not assume (10) with asymmetric links. For asymmetric networks, we follow reference [12] and introduce the mean square state deviation MSdev as a performance measure. Denote the current av erage of the node states by x avg ( k ) = 1 N 1 T x ( k ) . Quantity MSdev describes how far apart different states x i ( k ) are; it is giv en by MSdev( k ) = N X i =1 E ( x i ( k ) − x avg ( k )) 2 = E ζ ( k ) T ζ ( k ) , where ζ ( k ) = x ( k ) − x avg ( k )1 = ( I − J ) x ( k ) . (11) C. Symmetric links: Statistics of W ( k ) In this subsection, we deriv e closed form expressions for the first and the second order statistics on the random matrix W ( k ) . Let q ( k ) be the random vector that collects the non redundant entries of A ( k ) : q l ( k ) = A ij ( k ) , i < j, ( i, j ) ∈ E , (12) where the entries of A ( k ) are ordered in lexicographic order with respect to i and j , from left to right, top to bottom. For symmetric links, A ij ( k ) = A j i ( k ) , so the dimension of q ( k ) is half of the number of November 6, 2018 DRAFT 10 directed links, i.e., M . W e let the mean and the cov ariance of q ( k ) and V ec ( A ( k )) be: π = E [ q ( k )] (13) π l = E[ q l ( k )] (14) R q = Co v( q ( k )) = E[ ( q ( k ) − π ) ( q ( k ) − π ) T ] (15) R A = Co v( V ec( A ( k )) ) (16) The relation between R q and R A can be written as: R A = F R q F T (17) where F ∈ R N 2 × M is the zero one selection matrix that linearly maps q ( k ) to V ec ( A ( k )) , i.e., V ec ( A ( k )) = F q ( k ) . W e introduce further notation. Let P be the matrix of the link formation proba- bilities P = [ P ij ] Define the matrix B ∈ R N 2 × N 2 with N × N zero diagonal blocks and N × N off diagonal blocks B ij equal to: B ij = 1 e T i + e j 1 T and write W in terms of its columns W = [ W 1 W 2 ... W N ] . W e let W C = W 1 ⊕ W 2 ⊕ ... ⊕ W N For symmetric random networks, the mean of the random weight matrix W ( k ) and of W 2 ( k ) play an important role for the conv er gence rate of the consensus algorithm. Using the above notation, we can get compact representations for these quantities, as pro vided in Lemma 1 proved in Appendix A. Lemma 1 Consider the consensus algorithm (4). Then the mean and the second moment R C of W defined belo w are: W = E [ W ] = W P + I − diag ( W P ) (18) R C = E W 2 − W 2 (19) = W C T R A ( I ⊗ 11 T + 11 T ⊗ I − B ) W C (20) November 6, 2018 DRAFT 11 In the special case of spatially uncorrelated links, the second moment R C of W are 1 2 R C = diag 11 T − P P ( W W ) − 11 T − P P W W (21) For asymmetric random links, the expression for the mean of the random weight matrix W ( k ) remains the same (as in Lemma 1). For asymmetric random links, instead of E W 2 ( k ) − J (consider eqn. (18),(19) and the term E W 2 ( k ) in it), the quantity of interest becomes E W T ( I − J ) W ( k ) (The quantity of interest is different since the optimization criterion will be different.) For symmetric links, the matrix E W 2 − J is a quadratic matrix function of the weights W ij ; it depends also quadratically on the P ij ’ s and is an affine function of [ R q ] ij ’ s. The same will still hold for E W T ( I − J ) W ( k ) in the case of asymmetric random links. The difference, howe ver , is that E W T ( I − J ) W ( k ) does not admit the compact representation as given in (19), and we do not pursue here cumbersome entry wise representations. In the Appendix C, we do present the expressions for the matrix E W T ( I − J ) W ( k ) for the broadcast gossip algorithm [12] (that we study in subsection VI-B). I V . W E I G H T O P T I M I Z A T I O N : S Y M M E T R I C R A N D O M L I N K S A. Optimization criterion: Mean square con verg ence rate W e are interested in finding the rate at which MSE( k ) decays to zero and to optimize this rate with respect to the weights W . First we deriv e the recursion for the error e ( k ) . W e have from eqn. (4): 1 T x ( k + 1) = 1 T W ( k ) x ( k ) = 1 T x ( k ) = 1 T x (0) = N x avg 1 T e ( k ) = 1 T x ( k ) − 1 T 1 x avg = N x avg − N x avg = 0 W e deri v e the error vector dynamics: e ( k + 1) = x ( k + 1) − x avg 1 = W ( k ) x ( k ) − W ( k ) x avg 1 = W ( k ) e ( k ) = ( W ( k ) − J ) e ( k ) (22) where the last equality holds because J e ( k ) = 1 N 11 T e ( k ) = 0 . Recall the definition of the mean squared consensus error (9) and the error covariance matrix in eqn. (8) and recall that MSE( k ) = tr Σ( k ) = E e ( k ) e ( k ) T . Introduce the quantity φ ( W ) = λ max E[ W 2 ] − J (23) The next Lemma sho ws that the mean squared error decays at the rate φ ( W ) . November 6, 2018 DRAFT 12 Lemma 2 (m.s.s con verg ence rate) Consider the consensus algorithm gi v en by eqn. (4). Then: tr (Σ( k + 1)) = tr E[ W 2 ] − J Σ( k ) (24) tr (Σ( k + 1)) ≤ ( φ ( W )) tr (Σ( k )) , k ≥ 0 (25) Pr oof: From the definition of the covariance Σ( k + 1) , using the dynamics of the error e ( k + 1) , interchanging expectation with the tr operator , using properties of the trace, interchanging the expectation with the tr once again, using the independence of e ( k ) and W ( k ) , and, finally , noting that W ( k ) J = J , we get (24). The independence between e ( k ) and W ( k ) follows because W ( k ) is an i.i.d. sequence, and e ( k ) depends on W (0) ,..., W ( k − 1) . Then e ( k ) and W ( k ) are independent by the disjoint block theorem [26]. Ha ving (24), eqn. (25) can be easily shown, for example, by e x ercise 18, page 423, [27]. W e remark that, in the case of asymmetric random links, MSE does not asymptotically go to zero. For the case of asymmetric links, we use different performance metric. This will be detailed in section V. B. Symmetric links: W eight optimization pr oblem formulation W e now formulate the weight optimization problem as finding the weights W ij that optimize the mean squared rate of con vergence: minimize φ ( W ) subject to W ∈ S W (26) The set S W is defined in eqn. (6) and the rate φ ( W ) is gi ven by (23). The optimization problem (26) is unconstrained, since ef fecti vely the optimization v ariables are W ij ∈ R , ( i, j ) ∈ E , other entries of W being zero. A point W • ∈ S W such that φ ( W • ) < 1 will always exist if the supergraph G is connected. Reference [28] studies the case when the random matrices W ( k ) are stochastic and sho ws that φ ( W • ) < 1 if the super graph is connected and all the realizations of the random matrix W ( k ) are stochastic symmetric matrices. Thus, to locate a point W • ∈ S W such that φ ( W • ) < 1 , we just take W • that assures all the realizations of W be symmetric stochastic matrices. It is tri vial to sho w that for any point in the set S stoch = { W ∈ S W : W ij > 0 , if ( i, j ) ∈ E , W 1 < 1 } ⊆ S W (27) all the realizations of W ( k ) are stochastic, symmetric. Thus, for any point W • ∈ S stoch , we hav e that φ ( W • ) < 1 if the graph is connected. November 6, 2018 DRAFT 13 W e remark that the optimum W ∗ does not hav e to lie in the set S stoch . In general, W ∗ lies in the set S conv = { W ∈ S W : φ ( W ) < 1 } ⊆ S W (28) The set S stoch is a proper subset of S conv (If W ∈ S stoch then φ ( W ) < 1 , but the con verse statement is not true in general.) W e also remark that the consensus algorithm (4) con v erges almost surely if φ ( W ) < 1 (not only in mean squared sense). This can be sho wn, for instance, by the technique de veloped in [28]. W e no w relate (26) to reference [29]. This reference studies the weight optimization for the case of a static topology . In this case the topology is deterministic, described by the supergraph G . The link formation probability matrix P reduces to the supergraph adjacency (zero-one) matrix A , since the links occur always if they are realizable. Also, the link cov ariance matrix R q becomes zero. The weight matrix W is deterministic and equal to W = W = diag ( W A ) − W A + I Recall that r ( X ) denotes the spectral radius of X . Then, the quantities ( r ( W − J )) 2 and φ ( W ) coincide. Thus, for the case of static topology , the optimization problem (26) that we address reduces to the optimization problem proposed in [29]. C. Conve xity of the weight optimization pr oblem W e sho w that φ : S W → R + is con ve x, where S W is defined in eqn. (6) and φ ( W ) by eqn. (23). Lemma 1 giv es the closed form expression of E W 2 . W e see that φ ( W ) is the concatenation of a quadratic matrix function and λ max ( · ) . This concatenation is not con v ex in general. Howe ver , the next Lemma shows that φ ( W ) is con vex for our problem. Lemma 3 (Con vexity of φ ( W ) ) The function φ : S W → R + is con ve x. Pr oof: Choose arbitrary X, Y ∈ S W . W e restrict our attention to matrices W of the form W = X + t Y , t ∈ R . (29) Recall the expression for W gi ven by (2) and (4). For the matrix W giv en by (29), we hav e for W = W ( t ) W ( t ) = I − diag [( X + tY ) A ] + ( X + tY ) A (30) = X + t Y , X = X A + I − diag ( X A ) , Y = Y A − diag ( X A ) November 6, 2018 DRAFT 14 Introduce the auxiliary function η : R → R + , η ( t ) = λ max E W ( t ) 2 − J (31) T o prove that φ ( W ) is con ve x, it suffices to prove that the function φ is conv e x. Introduce Z ( t ) and compute successiv ely Z ( t ) = W ( t ) 2 − J (32) = ( X + t Y ) 2 − J (33) = t 2 Y 2 + t ( X Y + Y X ) + X 2 − J (34) = t 2 Z 2 + t Z 1 + Z 0 (35) The random matrices Z 2 , Z 1 , and Z 0 do not depend on t . Also, Z 2 is semidefinite positiv e. The function η ( t ) can be expressed as η ( t ) = λ max (E [ Z ( t )]) W e will now derive that Z ((1 − α ) t + αu ) (1 − α ) Z ( t ) + α Z ( u ) , ∀ α ∈ [0 , 1] , ∀ t, u ∈ R (36) Since η ( t ) = t 2 is con ve x, the follo wing inequality holds: [(1 − α ) t + αu ] 2 ≤ (1 − α ) t 2 + αu 2 , α ∈ [0 , 1] (37) Since the matrix Z 2 is positiv e semidefinite, eqn. (37) implies that: ((1 − α ) t + αu ) 2 Z 2 (1 − α ) t 2 Z 2 + α u 2 Z 2 , α ∈ [0 , 1] After adding to both sides ((1 − α ) t + αu ) Z 1 + Z 0 , we get eqn. (36). T aking the expectation to both sides of (36), get: E [ Z ((1 − α ) t + αu ) ] E [ (1 − α ) Z ( t ) + α Z ( u ) ] = (1 − α )E [ Z ( t ) ] + α E [ Z ( u ) ] , α ∈ [0 , 1] November 6, 2018 DRAFT 15 No w , we ha v e that: η ((1 − α ) t + αu ) = λ max ( E [ Z ((1 − α ) t + αu )] ) ≤ λ max ( (1 − α )E [ Z ( t )] + α E [ Z ( u )] ) ≤ (1 − α ) λ max ( E [ Z ( t )] ) + α λ max ( E [ Z ( u )] ) = (1 − α ) η ( t ) + α η ( u ) , α ∈ [0 , 1] The last inequality holds since λ max ( · ) is con ve x. This implies η ( t ) is con ve x and hence φ ( W ) is con v ex. W e remark that con ve xity of φ ( W ) is not ob vious and requires proof. The function φ ( W ) is a concate- nation of a matrix quadratic function and λ max ( · ) . Although the function λ max ( · ) is a con v ex function of its argument , one still ha ve to show that the follo wing concatenation is con ve x: W 7→ E[ W 2 ] − J 7→ φ ( W ) = λ max E[ W 2 ] − J . D. Fully connected random network: Closed form solution T o get some insight ho w the optimal weights depend on the network parameters, we consider the impractical, but simple geometry of a complete random symmetric graph. For this example, the opti- mization problem (26) admits a closed form solution, while, in general, numerical optimization is needed to solve (26). Although not practical, this example provides insight how the optimal weights depend on the network size N , the link formation probabilities, and the link formation spatial correlations. The supergraph is symmetric, fully connected, with N nodes and M = N ( N − 1) / 2 undirected links. W e assume that all the links hav e the same formation probability , i.e., that Prob ( q l = 1) = π l = p , p ∈ (0 , 1] , l = 1 , ..., M . W e assume that the cross-v ariance between any pair of links i and j equals to [ R q ] ij = β p (1 − p ) , where β is the correlation coef ficient. The matrix R q is giv en by R q = p (1 − p ) (1 − β ) I + β 11 T . The eigen v alues of R q are λ 1 ( R q ) = p (1 − p ) (1 + ( M − 1) β ) , and λ i ( R q ) = p (1 − p ) (1 − β ) ≥ 0 , i = 2 , ..., M . The condition that R q 0 implies that β ≥ − 1 / ( M − 1) . Also, we ha ve that β := E [ q i q j ] − E [ q i ] E [ q j ] p V ar( q i ) p V ar( q j ) (38) = Prob ( q i = 1 , q j = 1) − p 2 p (1 − p ) ≥ − p 1 − p (39) November 6, 2018 DRAFT 16 Thus, the range of β is restricted to max − 1 M − 1 , − p 1 − p ≤ β ≤ 1 . (40) Due to the problem symmetry , the optimal weights for all links are the same, say W ∗ . The expressions for the optimal weight W ∗ and for the optimal con ver gence rate φ ∗ can be obtained after careful manipulations and expressing the matrix E W 2 − J explicitly in terms of p and β ; then, it is easy to show that: W ∗ = 1 N p + (1 − p ) (2 + β ( N − 2)) (41) φ ∗ = 1 − 1 1 + 1 − p p 2 N (1 − β ) + β (42) The optimal weight W ∗ decreases as β increases. This is also intuiti ve, since positi ve correlations imply that the links emanating from the same node tend to occur simultaneously , and thus the weight should be smaller . Similarly , negati v e correlations imply that the links emanating from the same node tend to occur exclusi v ely , which results in larger weights. Finally , we observe that in the uncorrelated case ( β = 0 ), as N becomes very lar ge, the optimal weight behaves as 1 / ( N p ) . Thus, for the uncorrelated links and large network, the optimal strategy (at least for this example) is to rescale the supergraph-optimal weight 1 / N by its formation probability p . Finally , for fix ed p and N , the f astest rate is achiev ed when β is as negati ve as possible. E. Numerical optimization: subgradient algorithm W e solve the optimization problem in (26) for generic networks by the subgradient algorithm, [30]. In this subsection, we consider spatially uncorrelated links, and we comment on extensions for spatially correlated links. Expressions for spatially correlated links are provided in Appendix B. W e recall that the function φ ( W ) is con ve x (proved in Section IV -C). It is nonsmooth because λ max ( · ) is nonsmooth. Let H ∈ S N be the subgradient of the function φ ( W ) . T o deriv e the expression for the subgradient of φ ( W ) , we use the v ariational interpretation of φ ( W ) : φ ( W ) = max v T v =1 v T E W 2 − J v = max v T v =1 f v ( W ) (43) By the subgradient calculus, a subgradient of φ ( W ) at point W is equal to a subgradient H u of the function f u ( W ) for which the maximum of the optimization problem (43) is attained, see, e.g., [30]. The maximum of f v ( W ) (with respect to v ) is attained at v = u , where u is the eigen vector of the matrix November 6, 2018 DRAFT 17 E W 2 − J that corresponds to its maximal eigen v alue, i.e., the maximal eigen v ector . In our case, the function f u ( W ) is dif ferentiable (quadratic function), and hence the subgradient of f u ( W ) (and also the subgradient of φ ( W ) ) is equal to the gradient of f u ( W ) , [30]: H ij = u T ∂ (E[ W 2 ] − J ) ∂ W ij u if ( i, j ) ∈ E 0 otherwise. (44) W e compute for ( i, j ) ∈ E H ij = u T ∂ W 2 − J + R C ∂ W ij u (45) = u T − 2 W P ij ( e i − e j )( e i − e j ) T + 4 W ij P ij (1 − P ij )( e i − e j )( e i − e j ) T u = 2 P ij ( u i − u j ) u T ( W j − W i ) + 4 P ij (1 − P ij ) W ij ( u i − u j ) 2 (46) The subgradient algorithm is giv en by algorithm 1. The stepsize α k is nonnegati ve, diminishing, and Algorithm 1 : Subgradient algorithm Set initial W (1) ∈ S W Set k = 1 Repeat Compute a subgradient H ( k ) of φ at W ( k ) , and set W ( k +1) = W ( k ) − α k H ( k ) k := k + 1 nonsummable: lim k →∞ α k = 0 , P ∞ k =1 α k = ∞ . W e choose α k = 1 √ k , k = 1 , 2 , ... , similarly as in [29]. V . W E I G H T O P T I M I Z A T I O N : A S Y M M E T R I C R A N D O M L I N K S W e now address the weight optimization for asymmetric random networks. Subsections V -A and V -B introduce the optimization criterion and the corresponding weight optimization problem, respectiv ely . Subsection V -C sho ws that this optimization problem is con ve x. A. Optimization criterion: Mean square deviation con verg ence rate Introduce now ψ ( W ) := λ max E W T ( I − J ) W . (47) Reference [12] sho ws that the mean square de viation MSdev satisfies the follo wing equation: MSdev( k + 1) ≤ ψ ( W ) MSdev ( k ) . (48) November 6, 2018 DRAFT 18 Thus, if the quantity ψ ( W ) is strictly less than one, then MSdev conv er ges to zero asymptotically , with the worst case rate equal to ψ ( W ) . W e remark that the condition (10) is not needed for eqn. (48) to hold, i.e., MSde v con v erges to zero e ven if condition (10) is not satisfied; this condition is needed only for eqn. (25) to hold, i.e., only to have MSE to con ver ge to zero. B. Asymmetric network: W eight optimization pr oblem formulation In the case of asymmetric links, we propose to optimize the mean square de viation con vergence rate, i.e., to solv e the following optimization problem: minimize ψ ( W ) subject to W ∈ S asym W P N i =1 P ij W ij = 1 , i = 1 , ..., N (49) The constraints in the optimization problem (49) assure that, in e xpectation, condition (10) is satisfied, i.e., that 1 T E [ W ] = 1 T . (50) If (50) is satisfied, then the consensus algorithm con ver ges to the true av erage x av g in expectation [12]. Equation (50) is a linear constraint with respect to the weights W ij , and thus does not violate the con v exity of the optimization problem (49). W e emphasize that in the case of asymmetric links, we do not assume the weights W ij and W j i to be equal. In section VI-B, we show that allowing W ij and W j i to be dif ferent leads to better solutions in the case of asymmetric networks. C. Conve xity of the weight optimization pr oblem W e sho w that the function ψ ( W ) is con ve x. W e remark that reference [12] shows that the function is con v ex, when all the weights W ij are equal to g . W e sho w here that this function is con vex ev en when the weights are dif ferent. Lemma 4 (Con vexity of ψ ( W ) ) The function φ : S asym W → R + is con ve x. Pr oof: The proof is very similar to the proof of Lemma 3. The proof starts with introducing W as in eqn. (29) and with introducing W ( t ) as in eqn. (30). The difference is that, instead of considering the matrix W 2 − J , we consider no w the matrix W T ( I − J ) W . In the proof of Lemma 3, we introduced the auxiliary function η ( t ) given by (31); here, we introduce the auxiliary function κ ( t ) , gi ven by: κ ( t ) = λ max W ( t ) T ( I − J ) W , (51) November 6, 2018 DRAFT 19 and show that ψ ( W ) is con ve x by proving that κ ( t ) is con ve x. Then, we proceed as in the proof of Lemma 3. In eqn. (35) the matrix Z 2 becomes Z 2 := Y T ( I − J ) Y . The random matrix Z 2 is obviously positi ve semidefinite. The proof then proceeds as in Lemma 3. V I . S I M U L A T I O N S W e demonstrate the effecti v eness of our approach with a comprehensiv e set of simulations. These simulations cover both examples of asymmetric and symmetric networks and both networks with random link failures and with randomized protocols. In particular , we consider the following two standard sets of experiments with random networks: 1) spatially correlated link failures and symmetric links and 2) randomized protocols, in particular , the broadcast gossip algorithm [12]. W ith respect to the first set, we consider correlated link failures with two types of correlation structure. W e are particularly interested in studying the dependence of the performance and of the gains on the size of the network N and on the link correlation structure. In all these experiments, we consider geometric random graphs. Nodes communicate among themselves if within their radius of communication, r . The nodes are uniformly distributed on a unit square. The number of nodes is N = 100 and the average degree is 15% N . In subsection VI-A, the random instantiations of the networks are undirected; in subsection VI-B, the random instantiations of the networks are directed. In the first set of experiments with correlated link failures, the link formation probabilities P ij are chosen such that they decay quadratically with the distance: P ij = 1 − k δ ij r 2 , (52) where we choose k = 0 . 7 . W e see that, with (52), a link will be activ e with high probability if the nodes are close ( δ ij ' 0 ), while the link will be do wn with probability at most 0 . 7 , if the nodes are apart by r . W e recall that we refer to our weight design, i.e., to the solutions of the weight optimization prob- lems (26), (49), as probability based weights (PBW). W e study the performance of PBW , comparing it with the standard weight choices a v ailable in the literature: in subsection VI-A, we compare it with the Metropolis weights (MW), discussed in [29], and the supergraph based weights (SGBW). The SGBW are the optimal (nonneg ati ve) weights designed for a static (nonrandom) graph G , which are then applied to a random network when the underlying supergraph is G . This is the strategy used in [23]. For asymmetric links (and for asymmetric weights W ij 6 = W j i ), in subsection VI-B, we compare PBW with the optimal weight choice in [12] for broadcast gossip that considers all the weights to be equal. November 6, 2018 DRAFT 20 In the first set of experiments in subsection VI-A, we quantify the performance gain of PBW ov er SGBW and MW by the gains: Γ τ s = τ SGBW τ PBW (53) where τ is a time constant defined as: τ = 1 0 . 5 ln φ ( W ) (54) W e also compare PBW with SGBW and MW with the following measure: Γ η s = η SGBW η PBW (55) Γ η m = η MW η PBW (56) where η is the asymptotic time constant defined by η = 1 | γ | (57) γ = lim k →∞ k e ( k ) k k e (0) k 1 /k (58) Reference [23] shows that for random networks η is an almost sure constant and τ is an upper bound on η . Also, it sho ws that τ is an upper bound on η . Subsections VI-A and VI-B will provide further details on the e xpermints. A. Symmetric links: random networks with corr elated link failur es T o completely define the probability distribution of the random link vector q ∈ R M , we must assign probability to each of the 2 M possible realizations of q , q = ( α 1 , ..., α M ) T , α i ∈ { 0 , 1 } . Since in networks of practical interest M may be very large, of order 1000 or larger , specifying the complete distribution of the vector q is most likely infeasible. Hence, we work with the second moment description and specify only the first two moments of its distribution, the mean and the co v ariance, π and R q . W ithout loss of generality , order the links so that π 1 ≤ π 2 ≤ ... ≤ π M . Lemma 5 The mean and the variance ( π , R q ) of a Bernoulli random vector satisfy: 0 ≤ π i ≤ 1 , i = 1 , ..., N (59) R q 0 (60) max ( − π i π j , π i + π j − 1 − π i π j ) ≤ [ R q ] ij ≤ π i (1 − π j ) = R ij , i < j (61) November 6, 2018 DRAFT 21 Pr oof: Equations (59) and (60) must hold because π l ’ s are probabilities and R q is a cov ariance matrix. Recall that [ R q ] ij = E [ q i q j ] − E [ q i ] E [ q j ] = Prob ( q i = 1 , q j = 1) − π i π j . (62) T o pro ve the lower bound in (61), observe that: Prob ( q i = 1 , q j = 1) = Prob ( q i = 1) + Prob ( q j = 1) − Prob ( { q i = 1 } or { q j = 1 } ) = π i + π j − Prob ( { q i = 1 } or { q j = 1 } ) ≥ π i + π j − 1 . (63) In vie w of the fact that Prob ( q i = 1 , q j = 1) ≥ 0 , eqn. (63), and eqn. (62), the proof for the lower bound in (61) follows. The upper bound in (61) holds because Prob ( q i = 1 , q j = 1) ≤ π i , i < j and eqn. (62). If we choose a pair ( π , R q ) that satisfies (59), (60), (61), one cannot guarantee that ( π , R q ) is a valid pair , in the sense that there exists a probability distribution on q with its first and second moments being equal to ( π , R q ) , [31]. Furthermore, if ( π , R q ) is giv en, to simulate binary random v ariables with the marginal probabilities and correlations equal to ( π , R q ) is challenging. These questions hav e been studied, see [32], [31]. W e use the results in [32], [31] to generate our correlation models. In particular , we use the result that R = R ij (see eqn. (61)) is a valid correlation structure for any π , [32]. W e simulate the correlated links by the method proposed in [31]; this method handles a wide range of different correlation structures and has a small computational cost. Link correlation structures. W e consider two different correlation structures for any pair of links i and j in the super graph: [ R q ] ij = c 1 R ij (64) [ R q ] ij = c 2 θ κ ij R ij (65) where c 1 ∈ (0 , 1] , θ ∈ (0 , 1) and c 2 ∈ (0 , 1] are parameters, and κ ij is the distance between links i and j defined as the length of the shortest path that connects them in the super graph. The correlation structure (64) assumes that the correlation between any pair of links is a fraction of the maximal possible correlation, for the gi ven π (see eqn. (61) to recall R ij ). Reference [32] constructs a method for generating the correlation structure (64). The correlation structure (65) assumes that the correlation between the links decays geometrically with this distance . In our simulations, we set θ = 0 . 95 , and find the maximal c 2 , such that the resulting November 6, 2018 DRAFT 22 correlation structure can be simulated by the method in [31]. F or all the netw orks that we simulated in the paper , c 2 is between 0 . 09 and 0 . 11 . Results. W e want to address the follo wing tw o questions: 1) What is the performance gain ( Γ s , Γ m in eqns. ( ?? ), ( ?? )) of PBW ov er SGBW and MW; and 2) Ho w does this gain scale with the network size, i.e., the number of nodes N ? Perf ormance gain of PBW over SGBW and MW . W e consider question 1) for both correlation structures (64), (65). W e generate 20 instantiations of our standard supergraphs (with 100 nodes each and approximately the same a v erage relativ e degree, equal to 15% ). Then, for each super graph, we generate formation probabilities according to rule (52). For each supergraph with the giv en formation probabilities, we generate two link correlation structures, (64) and (65). W e ev aluate the con v ergence rate φ j gi ven by (25), time constants η j gi ven by (57), and τ j , given by (54), and the performance gains [Γ η s ] j , [Γ η m ] j for each supergraph ( j = 1 , ..., 20 ). W e compute the mean φ , the maximum φ + and the minimum φ − from the list { φ j } , j = 1 , ..., 20 (and similarly for { η j } and { τ j } , j = 1 , ..., 20 ). Results for the correlation structure (64) are given in T able 1 and for the correlation structure (65), in T able 2. The performance gains Γ s , Γ m , for both correlation structures are in T able 3. In addition, Figure 1 depicts the av eraged error norm over 100 sample paths. W e can see that the PBW outperform the SGBW and the MW for both correlation structures (64) and (65). For e xample, for the correlation (64), the PBW tak e less than 40 iterations to achie ve 0 . 2% precision, while the SGBW take more than 70, and the MW take more than 80 iterations. For correlation (65), to achiev e 0 . 2% precision, the PBW take about 47 iterations, while the SGBW and the MW take more than 90 and 100 iterations, respectively . The av erage performance 0 20 40 60 80 100 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 iteration number average error norm SGBW PBW MW 0 20 40 60 80 100 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 iteration number average error norm SGBW PBW MW Fig. 1. A verage error norm versus iteration number . Left: correlation structure (64); right: correlation structure (65). gain of PBW ov er MW is larger than the performance gain over SGBW , for both (64) and (65). The November 6, 2018 DRAFT 23 T ABLE I C O R R E L AT I O N S T R U C T U R E (64) : A V E R A G E ( · ) , M A X I M A L ( · ) + , A N D M I N I M A L ( · ) − V A L U E S O F T H E M S E C O N V E R G E N C E R AT E φ (23), A N D C O R R E S P O N D I N G T I M E C O N S TA N T S τ (54) A N D η (57) , F O R 2 0 G E N E R A T E D S U P E R G R A P H S SGBW PBW MW φ 0.91 0.87 φ + 0.95 0.92 φ − 0.89 0.83 τ 22.7 15.4 τ + 28 19 τ − 20 14 η 20 13 29 η + 25 16 38 η − 19 12 27 T ABLE II C O R R E L AT I O N S T R U C T U R E (65) : A V E R A G E ( · ) , M A X I M A L ( · ) + , A N D M I N I M A L ( · ) − V A L U E S O F T H E M S E C O N V E R G E N C E R AT E φ (23), A N D C O R R E S P O N D I N G T I M E C O N S TA N T S τ (54) A N D η (57) , F O R 2 0 G E N E R A T E D S U P E R G R A P H S SGBW PBW MW φ 0.92 0.86 φ + 0.94 0.90 φ − 0.91 0.84 τ 25.5 14.3 τ + 34 19 τ − 21 12 η 20 11.5 24.4 η + 23 14 29 η − 16 9 19 T ABLE III A V E R AG E ( · ) , M A X I M A L ( · ) + , A N D M I N I M A L ( · ) − P E R F O R M A N C E G A I N S Γ η s A N D Γ η m (55) F O R T H E T W O C O R R E L AT I O N S T R U C T U R E S (64) A N D (65) F O R 2 0 G E N E R A T E D S U P E R G R A P H S Correlation (64) Correlation (65) (Γ η s ) 1.54 1.73 (Γ η s ) + 1.66 1.91 (Γ η s ) − 1.46 1.58 (Γ eta m ) 2.22 2.11 (Γ η m ) + 2.42 2.45 (Γ η m ) − 2.07 1.92 gain ov er SGBW , Γ s , is significant, being 1.54 for (64) and 1.73 for (65). The gain with the correlation structure (65) is larger than the gain with (64), suggesting that larger gain ov er SGBW is achiev ed with smaller correlations. This is intuiti v e, since large positi v e correlations imply that the random links tend to occur simultaneously , i.e., in a certain sense random network realizations are more similar to the underlying supergraph. Notice that the networks with R q as in (65) achiev e faster rate than for (64) (having at the same time similar supergraphs and formation probabilities). This is in accordance with the analytical studies in section IV -D that suggest that faster rates can be achie ved for smaller (or negati ve correlations) if G and π are fix ed. Perf ormance gain of PBW over SGBW as a function of the network size. T o answer question 2), we generate the super graphs with N ranging from 30 up to 160 , keeping the average relati ve degree of the November 6, 2018 DRAFT 24 supergraph approximately the same ( 15% ). Again, PBW performs better than MW ( τ SGBW < 0 . 85 τ MW ), so we focus on the dependence of Γ s on N , since it is more critical. Figure 2 plots Γ s versus N , for the two correlation structures. The gain Γ s increases with N for both (65) and (64). 20 40 60 80 100 120 140 160 1.5 1.6 1.7 1.8 1.9 2 2.1 2.2 number of nodes performance gain of PBW over S GBW Correlation in eqn.(65) corr. in eqn.(64) Fig. 2. Performance gain of PBW over SGBW ( Γ η s , eqn. (55)) as a function of the number of nodes in the network. B. Broadcast gossip algorithm [12]: Asymmetric r andom links In the previous section, we demonstrated the ef fecti veness of our approach in networks with random symmetric link failures. This section demonstrates the validity of our approach in randomized proto- cols with asymmetric links. W e study the broadcast gossip algorithm [12]. Although the optimization problem (49) is con v ex for generic spatially correlated directed random links, we pursue here numerical optimization of the broadcast gossip algorithm proposed in [12], where, at each time step, node i is selected at random, with probability 1 / N . Node i then broadcasts its state to all its neighbors within its wireless range. The neighbors then update their state by performing the weighted average of the received state with their own state. The nodes outside the set Ω i and the node i itself keep their previous state unchanged. The broadcast gossip algorithm is well suited for WSN applications, since it exploits the broadcast nature of wireless media and a voids bidirectional communication [12]. Reference [12] shows that, in broadcast gossiping, all the nodes con ver ge a.s. to a common random v alue c with mean x avg and bounded mean squared error . Reference [12] studies the case when the weights W ij = g , ∀ ( i, j ) ∈ E and finds the optimal g = g ∗ that optimizes the mean square deviation MSdev (see eqn. (49)). W e optimize the same objecti ve function (see eqn. (49)) as in [12], but allo wing different weights for different directed links. W e detail on the numerical optimization for the broadcast gossip November 6, 2018 DRAFT 25 in the Appendix C. W e consider again the supergraph G from our standard experiment with N = 100 and average degree 15% N . For the broadcast gossip, we compare the performance of PBW with 1) the optimal equal weights in [12] with W ij = g ∗ , ( i, j ) ∈ E ; 2) broadcast gossip with W ij = 0 . 5 , ( i, j ) ∈ E . Figure 3 (left) plots the consensus mean square de viation MSdev for the 3 different weight choices. The decay of MSdev is much faster for the PBW than for W ij = 0 . 5 , ∀ ( i, j ) and W ij = g ∗ , ∀ ( i, j ) . For example, the MSde v falls below 10% after 260 iterations for PBW (i.e., 260 broadcast transmissions); broadcast gossip with W ij = g ∗ and W ij = 0 . 5 take 420 transmissions to achieve the same precision. This is to be expected, since PBW has many moredegrees of freedom for to optimize than the broadcast gossip in [12] with all equal weights W ij = g ∗ . Figure 3 (right) plots the MSE, i.e., the deviation of the true av erage x avg , for the three weight choices. PBW shows faster decay of MSE than the broadcast gossip with W ij = g ∗ and W ij = 0 . 5 . The weights provided by PBW are dif ferent among themselves, 0 100 200 300 400 500 600 10 -2 10 -1 10 0 total variance iteration number g=0.5 PBW g=g opt 0 100 200 300 400 500 600 1 0.6 0.3 iteration number total mean squared error g=0.5 PBW g=g opt Fig. 3. Broadcast gossip algorithm with different weight choices. Left: total variance; right: total mean squared error v arying from 0.3 to 0.95. The weights W ij and W j i are also dif ferent, where the maximal dif ference between W ij and W j i , ( i, j ) ∈ E , is 0.6. Thus, in the case of directed random networks, asymmetric matrix W results in f aster con ver gence rate. V I I . C O N C L U S I O N In this paper , we studied the optimization of the weights for the consensus algorithm under random topology and spatially correlated links. W e considered both networks with random link failures and randomized algorithms; from the weights optimization point of vie w , both fit into the same frame work. W e sho wed that, for symmetric random links, optimizing the MSE con ver gence rate is a conv e x optimization problem, and , for asymmetric links, optimizing the mean squared deviation from the current average state November 6, 2018 DRAFT 26 is also a con ve x optimization problem. W e illustrated with simulations that the probability based weights (PBW) outperform previously proposed weights strategies that do not use the statistics of the network randomness. The simulations also show that, using the link quality estimates and the link correlations for designing the weights significantly improv es the con ver gence speed, typically reducing the time to consensus by one third to a half, compared to choices pre viously proposed in the literature. A P P E N D I X I P RO O F O F L E M M A 1 ( A S K E T C H ) Eqn. (18) follows from the expectation of (3). T o prove the remaining of the Lemma, we find W 2 , W 2 , and the expectation W 2 . W e obtain successi vely: W 2 = ( W A + I − diag ( W A ) ) 2 = ( W A ) 2 + diag 2 ( W A ) + I + 2 W A − 2 diag( W A ) − ( W A ) diag( W A ) − diag ( W A ) ( W A ) W 2 = ( W P ) 2 + diag 2 ( W P ) + I + 2 W P − 2 diag ( W P ) − [( W P ) diag ( W P ) + diag ( W P ) ( W P )] E W 2 = E ( W A ) 2 + E diag 2 ( W A ) + I + 2 W P − 2 diag ( W P ) − E[ ( W A ) diag ( W A ) + diag ( W A ) ( W A ) ] W e will next sho w the follo wing three equalities: E ( W A ) 2 = ( W P ) 2 + W C T R A (11 T ⊗ I ) W C (66) E diag 2 ( W A ) = diag 2 ( W P ) + W C T R A ( I ⊗ 11 T ) W C (67) E [( W A )diag ( W A ) + diag ( W A ) ( W A )] = (68) ( W P )diag ( W P ) + diag ( W P ) ( W P ) − W C T { R A B } W C First, consider (66) and find E h ( W A ) 2 i . Algebraic manipulations allow to write ( W A ) 2 as follo ws: ( W A ) 2 = W C T A 2 ( 11 T ⊗ I ) W C , A 2 = V ec( A )V ec T ( A ) (69) T o compute the expectation of (69), we need E [ A 2 ] that can be written as E [ A 2 ] = P 2 + R A , with P 2 = V ec( P ) V ec T ( P ) . November 6, 2018 DRAFT 27 Equation (66) follo ws, realizing that W C T P 2 ( 11 T ⊗ I ) W C = ( W P ) 2 . No w consider (67) and (68). After algebraic manipulations, it can be shown that diag 2 ( W A ) = W C T A 2 ( I ⊗ 11 T ) W C ( W A ) diag ( W A ) + diag ( W A ) ( W A ) = W C T {A 2 B } W C Computing the e xpectations in the last two equations leads to eqn. (67) and eqn. (68). Using equalities (66), (67), and (68) and comparing the e xpressions for W 2 and E[ W 2 ] leads to: R C = E[ W 2 ] − W 2 = W C T { R A ( I ⊗ 11 T + 11 T ⊗ I − B ) } W C (70) This completes the proof of Lemma 1. A P P E N D I X I I S U B G R A D I E N T S T E P C A L C U L A T I O N F O R T H E C A S E O F S PA T I A L L Y C O R R E L A T E D L I N K S T o compute the subgradient H , from eqns. (44) and (45) we consider the computation of E W 2 − J = W 2 − J + R C . Matrix W 2 − J is computed in the same way as for the uncorrelated case. T o compute R C , from (70), partition the matrix R A into N × N blocks: R A = R 11 R 12 . . . R 1 N R 21 R 22 . . . R 2 N . . . . . . . . . . . . R N 1 R N 2 . . . R N N Denote by d ij , by c l ij , and by r l ij the diagonal, the l -th column, and the l -th ro w of the block R ij . It can be sho wn that the matrix R C can be computed as follows: [ R C ] ij = W T i ( d ij W j ) − W ij W T i c i ij + W T j r j ij , i 6 = j [ R C ] ii = W T i ( d ii W i ) + W T i R ii W i Denote by R A (: , k ) the k -th column of the matrix R A and by k 1 = e T j ⊗ I N R A (: , ( i − 1) N + j ) , k 2 = e T i ⊗ I N R A (: , ( j − 1) N + i ) , k 3 = e T i ⊗ I N R A (: , ( i − 1) N + j ) , k 4 = e T j ⊗ I N R A (: , ( j − 1) N + i ) . November 6, 2018 DRAFT 28 Quantities k 1 , k 2 , k 3 and k 4 depend on ( i, j ) but for the sake of the notation simplicity indexes are omitted. It can be shown that the computation of H ij , ( i, j ) ∈ E boils do wn to: H ij = 2 u 2 i W T i c j ii + 2 u 2 j W T j c i j j + 2 u i W T j ( u k 1 ) + 2 u j W T i ( u k 2 ) − 2 u i u j W T j c j j i − 2 u i u j W T i c i ij − 2 u i W T i ( u k 3 ) − 2 u j W T j ( u k 4 ) + 2 P ij ( u i − u j ) u T W j − W i A P P E N D I X I I I N U M E R I C A L O P T I M I Z A T I O N F O R T H E B RO A D C A S T G O S S I P A L G O R I T H M W ith broadcast gossip, the matrix W ( k ) can take N dif ferent realizations, corresponding to the broadcast cycles of each of the N sensors. W e denote these realizations by W ( i ) , where i index es the broadcasting node. W e can write the random realization of the broadcast gossip matrix W ( i ) , i = 1 , ..., N , as follows: W ( i ) ( k ) = W A ( i ) ( k ) + I − diag W A ( i ) ( k ) , (71) where A ( i ) li ( k ) = 1 , if l ∈ Ω i . Other entries of A ( i ) ( k ) are zero. Similarly in Appendix A, we can arrive at the expressions for E W T W := E W T ( k ) W ( k ) and for E W T J W := E W T ( k ) J W ( k ) , for all k . W e remark that the matrix W needs not to be symmetric for the broadcast gossip and that W ij = 0 , if ( i, j ) / ∈ E . E W T W ii = 1 N N X l =1 ,l 6 = i W 2 li + 1 N N X l =1 ,l 6 = i (1 − W il ) 2 E h W T W ij i = 1 N W ij (1 − W ij ) + 1 N W j i (1 − W j i ) , i 6 = j E W T J W ii = 1 N 2 1 + X l 6 = i W li 2 + 1 N 2 N X l =1 ,l 6 = i (1 − W il ) 2 h E W T J W ij i = 1 N 2 (1 − W j i )(1 + N X l =1 ,l 6 = i W li ) + 1 N 2 (1 − W ij )(1 + N X l =1 ,l 6 = j W lj ) + 1 N 2 N X l =1 ,l 6 = i,l 6 = j (1 − W il )(1 − W j l ) , i 6 = j Denote by W BG := E W T W − E W T J W and recall the definition of the MSdev rate ψ ( W ) (47). W e have that ψ ( W ) = λ max W BG . W e proceed with the calculation of the subgradient of ψ ( W ) similarly as in subsection IV -E. The partial deri vati ve of the cost function ψ ( W ) with respect to weight November 6, 2018 DRAFT 29 W i,j is giv en by: ∂ ∂ W i,j λ max W BG = q T ∂ ∂ W i,j W BG q where q is eigen v ector associated with the maximal eigenv alue of the matrix W BG . Finally , partial deri vati ves of the entries of the matrix W BG with respect to weight W i,j are giv en by the follo wing set of equations: ∂ ∂ W i,j W BG i,i = − 2 N − 1 N (1 − W i,j ) ∂ ∂ W i,j W BG j,j = 2 N W i,j − 2 N (1 − N X l =1 ,l 6 = j W l,j ) ∂ ∂ W i,j W BG i,j = 1 N (1 − 2 W i,j ) − 1 N 2 ( − 1 − N X l =1 ,l 6 = j W l,j − W i,j ) ∂ ∂ W i,j W BG i,l = 1 N 2 (1 − W l,j ) , l 6 = i, l 6 = j ∂ ∂ W i,j W BG i,j = − 1 N 2 (1 − W l,j ) , l 6 = i, l 6 = j ∂ ∂ W l,m W BG i,j = 0 , other w ise. R E F E R E N C E S [1] J. N. Tsitsiklis, D. P . Bertsekas, and M. Athans, “Distrib uted asynchronous deterministic and stochastic gradient optimization algorithms, ” IEEE T rans. Autom. Contr ol , vol. 31 no. 9, pp. 803 – 812, September 1986. [2] J. N. Tsitsiklis, “Problems in decentralized decision making and computation, ” Ph.D., MIT , Cambridge, MA, 1984. [3] S.Kar and J. M. F . Moura, “Ramanujan topologies for decision making in sensor networks, ” in 44th Annual Allerton Conf . on Comm., Contr ol, and Comp. , Allerton, IL, Monticello, Sept. 2006, in vited paper in Sp. Session on Sensor Networks. [4] S. Kar , S. Aldosari, and J. Moura, “T opology for distributed inference on graphs, ” IEEE T ransactions on Signal Pr ocessing , vol. 56 No.6, pp. 2609–2613, June 2008. [5] L. Xiao, S. Boyd, and S. Lall, “ A scheme for robust distributed sensor fusion based on av erage consensus, ” Los Angeles, California, 2005, pp. 63–70. [6] I. D. Schizas, A. Ribeiro, and G. B. Giannakis, “Consensus in ad hoc wsns with noisy links - part i: Distributed estimation of deterministic signals, ” IEEE T r ansactions on Signal Pr ocessing , vol. 56, no. 1, January 2008. [7] S. Kar and J. Moura, “Distributed parameter estimation in sensor networks: Nonlinear observation models and imperfect communication, ” submitted for publication, 30 pages. [Online]. A vailable: arXiv:0809.0009v1 [cs.MA] [8] A. Jadbabaie, J. Lin, , and A. S. Morse, “Coordination of groups of mobile autonomous agents using nearest neighbor rules, ” IEEE T rans. Automat. Contr , vol. A C-48, no. 6, p. 988 1001, June 2003. [9] R.Olfati-Saber, J. Fax, and R. Murray , “Consensus and cooperation in networked multi-agent systems, ” Proceedings of the IEEE , vol. 95 no.1, pp. 215–233, Jan. 2007. November 6, 2018 DRAFT 30 [10] R. Olfati-Saber and R. M. Murray , “Consensus problems in networks of agents with switching topology and time-delays, ” IEEE T r ansactions on Automatic Contr ol , vol. 49, Sept. 2004. [11] S. Boyd, A. Ghosh, B. Prabhakar , and D. Shah, “Randomized gossip algorithms, ” IEEE T ransactions on Information Theory , vol. 52, no 6, pp. 2508–2530, June 2006. [12] T . A ysal, M. E. Y ildiz, A. D. Sarwate, and A. Scaglione, “Broadcast gossip algorithms for consensus, ” to appear in IEEE T ransactions on Signal Processing . [13] V . Blondel, J. Hendrickx, A. Olshe vsk y , and J. Tsitsiklis, “Conver gence in multiagent coordination, consensus, and flocking, ” in 44th IEEE Conference on Decision and Contr ol , Seville, Spain, 2005, pp. 2996– 3000. [14] L. Xiao, S. Boyd, and S. Lall, “Distributed average consensus with time-varying Metropolis weights, ” Automatica . [15] A. T ahbaz-Salehi and A. Jadbabaie, “Consensus ov er ergodic stationary graph processes, ” to appear in IEEE T ransactions on Automatic Contr ol . [16] S.Kar and J. M. F . Moura, “Distributed average consensus in sensor networks with random link failures, ” in ICASSP 2007., IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , vol. 2, Pacific Grove, CA, 15-20 April 2007. [17] Y . Hatano and M. Mesbahi, “ Agreement over random networks, ” in 43r d IEEE Confer ence on Decision and Contr ol , vol. 2, Paradise Island, the Bahamas, Dec. 2004, p. 2010 2015. [18] M. Porfiri and D. Stilwell, “Stochastic consensus over weighted directed networks, ” in 2007 American Contr ol Conference , New Y ork City , USA, July 11-13 2007, pp. 1425–1430. [19] S. Kar and J. Moura, “Distributed consensus algorithms in sensor networks with imperfect communication: Link failures and channel noise, ” IEEE T r ansactions on Signal Pr ocessing , vol. 57, no 1, pp. 355–369, Jan. 2009. [20] ——, “Sensor networks with random links: T opology design for distrib uted consensus, ” IEEE T ransactions on Signal Pr ocessing , vol. 56, no.7, pp. 3315–3326, July 2008. [21] J. Zhao and R. Govindan, “Understanding packet delivery performance in dense wireless sensor networks, ” Los Angeles, California, USA, 2003, pp. 1 – 13. [22] A.Cerpa, J. W ong, L. Kuang, M.Potkonjak, and D.Estrin, “Statistical model of lossy links in wireless sensor networks, ” F ourth International Symposium on Information Pr ocessing in Sensor Networks , pp. 81–88, 2005. [23] P . Denantes, F . Benezit, P . Thiran, and M. V etterli, “Which distributed averaging algorithm should I choose for my sensor network, ” INFOCOM 2008 , pp. 986–994. [24] W . Hastings, “Monte Carlo sampling methods using Markov chains and their applications, ” Biometrika , vol. 57, pp. 97–109, 1970. [25] S. Boyd, P . Diaconis, and L. Xiao, “Fastest mixing Markov chain on a graph, ” SIAM Review , vol. 46(4), pp. 667–689, December 2004. [26] A. F . Karr , Pr obability theory . New Y ork: Springer-V erlag, Springer texts in statistics, 1993. [27] R. A. Horn and C. R. Johnson, Matrix analysis . Cambrige Univesity Press, 1990. [28] A. T ahbaz-Salehi and A. Jadbabaie, “On consensus in random networks, ” to appear in IEEE T ransactions on Automatic Contr ol . [29] L. Xiao and S. Boyd, “Fast linear iterations for distributed averaging, ” Syst. Contr . Lett. , vol. 53, pp. 65–78, 2004. [30] J.-B. H. Urruty and C. Lemarechal, Con vex Analysis and Minimization Algorithms . Springer V erlag. [31] B. Quadish, “ A family of multiv ariate binary distributions for simulating correlated binary variables with specified marginal means and correlations, ” Biometrika , vol. 90, no 2, pp. 455–463, 2003. [32] S. D. Oman and D. M. Zucker, “Modelling and generating correlated binary v ariables, ” Biometrika , vol. 88 no. 1, pp. 287–290, 2001. November 6, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment