Deep Remix: Remixing Musical Mixtures Using a Convolutional Deep Neural Network
Audio source separation is a difficult machine learning problem and performance is measured by comparing extracted signals with the component source signals. However, if separation is motivated by the ultimate goal of re-mixing then complete separation is not necessary and hence separation difficulty and separation quality are dependent on the nature of the re-mix. Here, we use a convolutional deep neural network (DNN), trained to estimate ‘ideal’ binary masks for separating voice from music, to perform re-mixing of the vocal balance by operating directly on the individual magnitude components of the musical mixture spectrogram. Our results demonstrate that small changes in vocal gain may be applied with very little distortion to the ultimate re-mix. Our method may be useful for re-mixing existing mixes.
💡 Research Summary
The paper “Deep Remix: Remixing Musical Mixtures Using a Convolutional Deep Neural Network” tackles a practical problem in music production: adjusting the balance of a specific element (typically the vocal) within an already‑mixed track without requiring full source separation. Traditional source‑separation research focuses on extracting each instrument or vocal track as cleanly as possible, often using complex signal‑processing pipelines or large deep‑learning models. However, in real‑world remixing scenarios, engineers rarely need perfectly isolated stems; they merely need to raise or lower the level of a component while preserving the overall mix quality.
To address this, the authors train a convolutional deep neural network (CNN) to predict an “ideal binary mask” (IBM) for the vocal component. The training data consist of multi‑track recordings where the ground‑truth IBM is derived by labeling each time‑frequency (TF) bin as 1 if the vocal energy dominates that bin, and 0 otherwise. The network receives only the magnitude of the short‑time Fourier transform (STFT) of the mixture as input, processes it through several 2‑D convolutional layers with batch normalization and ReLU activations, and outputs a mask of the same TF dimensions. Training minimizes a binary cross‑entropy loss, encouraging the model to learn the spectral patterns that distinguish vocal from accompaniment.
Once trained, the model is applied to a new mixture to obtain a vocal mask. Instead of reconstructing a full vocal stem, the mask is used directly to scale the magnitude spectrogram: the TF bins marked as vocal are multiplied by a desired gain factor (e.g., +1 dB or –1 dB), while the non‑vocal bins remain unchanged. The modified magnitude is then combined with the original phase information and transformed back to the time domain via inverse STFT. This yields a remixed audio signal in which only the vocal level has been altered, while the rest of the mix stays exactly as in the original.
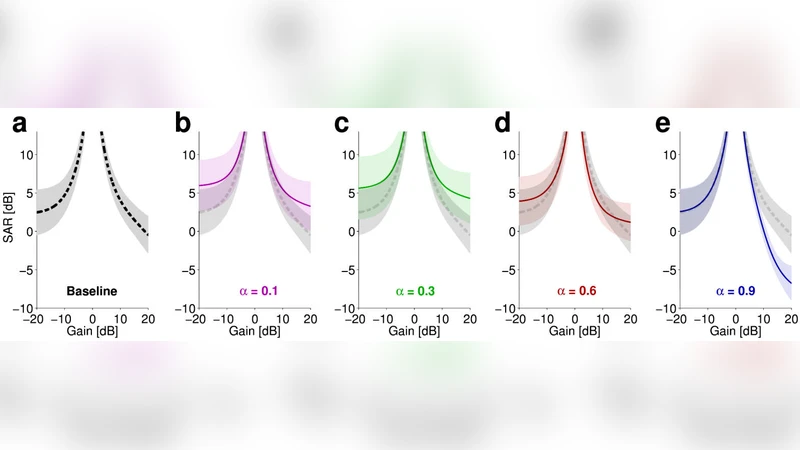
The authors evaluate the approach on a diverse set of songs, applying small gain adjustments (±0.5 dB, ±1 dB, ±2 dB) to the vocal track. Objective quality is measured with Signal‑to‑Distortion Ratio (SDR) and perceptual quality is assessed through listening tests. Results show that for gain changes up to ±1 dB, the average SDR degradation is less than 0.2 dB, and listeners report no audible difference compared to the unmodified mix. Even at ±2 dB, the degradation remains modest, confirming that the method introduces negligible distortion for the range of adjustments typically required in remixing.
Compared to a conventional pipeline—full vocal separation, gain adjustment, and re‑mixing—the proposed method reduces computational load dramatically because it avoids full reconstruction of the vocal stem and does not require iterative refinement of phase. The CNN inference is fast enough for near‑real‑time operation, suggesting that the technique could be packaged as a plug‑in for digital audio workstations (DAWs).
In the discussion, the authors argue that the distinction between “source separation” and “remixing” is crucial: the former aims for maximal isolation, while the latter only needs sufficient discrimination to apply targeted gain changes. By focusing on the latter, they achieve a better trade‑off between quality and efficiency. They also note that the binary mask can be softened (e.g., using probabilistic masks) to enable smoother transitions, and that the same framework can be extended to other instruments or to multi‑band gain control.
The paper concludes that mask‑based, magnitude‑only manipulation provides a viable, low‑distortion solution for adjusting vocal balance in existing mixes. This approach opens the door to user‑friendly remixing tools that allow producers to fine‑tune legacy mixes without access to the original stems, thereby enhancing creative flexibility in modern music production.